Co to jest obliczenia kwantowe. Obliczenia kwantowe kontra klasyczne: po co nam tak wiele liczb? Klasyczne obliczenia: AND, OR, NOT
Przeczytaj także
Kandydat nauk fizycznych i matematycznych L. FEDICHKIN (Instytut Fizyczno-Technologiczny Rosyjskiej Akademii Nauk.
Korzystając z praw mechaniki kwantowej, możliwe jest stworzenie zasadniczo nowego typu komputera, który pozwoli rozwiązać pewne problemy niedostępne nawet dla najpotężniejszych współczesnych superkomputerów. Szybkość wielu skomplikowanych obliczeń gwałtownie wzrośnie; wiadomości przesyłanych za pośrednictwem kwantowych linii komunikacyjnych nie będzie można przechwycić ani skopiować. Dziś powstały już prototypy tych komputerów kwantowych przyszłości.
Amerykański matematyk i fizyk węgierskiego pochodzenia Johann von Neumann (1903-1957).
Amerykański fizyk teoretyczny Richard Phillips Feynman (1918-1988).
Amerykański matematyk Peter Shor, specjalista w dziedzinie obliczeń kwantowych. Zaproponował algorytm kwantowy do szybkiej faktoryzacji dużych liczb.
Bit kwantowy, czyli kubit. Stany odpowiadają na przykład kierunkom wirowania jądro atomowe Góra czy dół.
Rejestr kwantowy to łańcuch bitów kwantowych. Jedno- lub dwukubitowe bramki kwantowe wykonują operacje logiczne na kubitach.
WSTĘP, CZYLI O OCHRONIE INFORMACJI
Jak myślisz, jaki program sprzedał najwięcej licencji na świecie? Nie będę ryzykował upierania się, że znam właściwą odpowiedź, ale na pewno znam jedną błędną: tę Nie któraś z wersji Microsoft Windows. Najpopularniejszy system operacyjny wyprzedza skromny produkt firmy RSA Data Security, Inc. - program implementujący algorytm szyfrowania za pomocą klucz publiczny RSA, nazwany na cześć swoich autorów - amerykańskich matematyków Rivesta, Shamira i Adelmana.
Faktem jest, że algorytm RSA jest wbudowany w większość komercyjnych systemów operacyjnych, a także w wiele innych aplikacji używanych w różnych urządzeniach - od kart inteligentnych po telefony komórkowe. W szczególności jest on dostępny również w systemie Microsoft Windows, co oznacza, że jest z pewnością bardziej rozpowszechniony niż ten popularny system operacyjny. Aby wykryć ślady RSA, na przykład w przeglądarce Internet Explorera(program do przeglądania stron www w Internecie), wystarczy otworzyć menu „Pomoc”, wejść do podmenu „O przeglądarce Internet Explorer” i wyświetlić listę używanych produktów innych firm. Inna popularna przeglądarka, Netscape Navigator, również wykorzystuje algorytm RSA. Generalnie ciężko znaleźć znaną firmę działającą w branży zaawansowana technologia, który nie kupiłby licencji na ten program. Obecnie RSA Data Security, Inc. sprzedał już ponad 450 milionów(!) licencji.
Dlaczego algorytm RSA był tak ważny?
Wyobraź sobie, że musisz szybko wymienić wiadomość z osobą, która jest daleko. Dzięki rozwojowi Internetu taka wymiana stała się dziś dostępna dla większości ludzi – wystarczy mieć komputer z modemem lub karta sieciowa. Naturalnie, wymieniając informacje w sieci, chciałbyś zachować swoje wiadomości w tajemnicy przed obcymi. Niemożliwe jest jednak całkowite zabezpieczenie długiej linii komunikacyjnej przed podsłuchem. Oznacza to, że wysyłane wiadomości muszą zostać zaszyfrowane, a otrzymane – odszyfrowane. Ale w jaki sposób Ty i Twój rozmówca możecie uzgodnić, jakiego klucza użyjecie? Jeśli wyślesz klucz do szyfru tą samą linią, osoba podsłuchująca może go łatwo przechwycić. Możesz oczywiście przekazać klucz inną linią komunikacyjną, na przykład wysłać go telegramem. Ale ta metoda jest zwykle niewygodna, a ponadto nie zawsze niezawodna: można również dotknąć drugiej linii. Dobrze, jeśli Ty i Twój odbiorca wiedzieliście wcześniej, że będziecie wymieniać szyfrowanie, dlatego wcześniej przekazaliście sobie klucze. A co jeśli na przykład chcesz wysłać potencjalnemu partnerowi biznesowemu poufną ofertę handlową lub kupić wybrany przez Ciebie produkt w nowym sklepie internetowym za pomocą karty kredytowej?
W latach 70. XX w., aby rozwiązać ten problem, zaproponowano systemy szyfrowania wykorzystujące do tej samej wiadomości dwa rodzaje kluczy: publiczny (nie wymagający zachowania tajemnicy) i prywatny (ściśle tajny). Klucz publiczny służy do szyfrowania wiadomości, a klucz prywatny służy do jej odszyfrowania. Wysyłasz swojemu korespondentowi klucz publiczny, a on używa go do szyfrowania swojej wiadomości. Osoba atakująca, która przechwyciła klucz publiczny, może jedynie zaszyfrować nim swoją wiadomość e-mail i przesłać ją innej osobie. Nie będzie jednak w stanie rozszyfrować korespondencji. Ty, znając klucz prywatny (jest on początkowo przechowywany przy Tobie), możesz łatwo odczytać zaadresowaną do Ciebie wiadomość. Do szyfrowania odpowiedzi użyjesz klucza publicznego przesłanego przez Twojego korespondenta (a on zachowa odpowiedni klucz prywatny dla siebie).
To jest dokładnie schemat kryptograficzny zastosowany w algorytmie RSA, najpopularniejszej metodzie szyfrowania klucza publicznego. Ponadto, aby utworzyć parę kluczy publicznych i prywatnych, stosuje się następującą ważną hipotezę. Jeśli są dwa duże (wymagające zapisania więcej niż stu cyfr dziesiętnych) prosty liczby M i K, to znalezienie ich iloczynu N=MK nie będzie trudne (nie trzeba do tego nawet komputera: w miarę uważna i cierpliwa osoba będzie w stanie pomnożyć takie liczby za pomocą długopisu i papieru). Ale aby rozwiązać problem odwrotny, to znaczy wiedzieć duża liczba N, rozłóż to na czynniki pierwsze M i K (tzw problem faktoryzacji) - Prawie niemożliwe! Właśnie z takim problemem spotka się atakujący, jeśli zdecyduje się „zhakować” algorytm RSA i odczytać zaszyfrowane nim informacje: aby poznać klucz prywatny, znając klucz publiczny, będzie musiał obliczyć M lub K .
Aby sprawdzić słuszność hipotezy o praktycznej złożoności rozkładu na czynniki dużych liczb, organizowano i nadal organizuje się specjalne konkursy. Rozłożenie zaledwie 155-cyfrowej (512-bitowej) liczby uważa się za rekord. Obliczenia prowadzono równolegle na wielu komputerach przez siedem miesięcy 1999 roku. Gdyby to zadanie wykonać na jednym nowoczesnym komputerze osobistym, wymagałoby to około 35 lat czasu pracy komputera! Obliczenia pokazują, że przy użyciu nawet tysiąca nowoczesnych stanowisk pracy i najlepszego znanego dziś algorytmu obliczeniowego jedną 250-cyfrową liczbę można rozłożyć na czynniki w ciągu około 800 tysięcy lat, a 1000-cyfrową w ciągu 10-25 (!) lat. (Dla porównania wiek Wszechświata wynosi ~10 10 lat.)
Dlatego algorytmy kryptograficzne takie jak RSA, działające na odpowiednio długich kluczach, uznano za całkowicie niezawodne i znalazły zastosowanie w wielu zastosowaniach. I wszystko było w porządku do tego czasu ...aż pojawiły się komputery kwantowe.
Okazuje się, że korzystając z praw mechaniki kwantowej, można zbudować komputery, dla których problem faktoryzacji (i wielu innych!) nie będzie bardzo trudny. Według szacunków, komputer kwantowy mając tylko około 10 tysięcy kwantowych bitów pamięci, może rozłożyć 1000-cyfrową liczbę na czynniki pierwsze w ciągu zaledwie kilku godzin!
JAK TO SIĘ WSZYSTKO ZACZEŁO?
Dopiero w połowie lat 90. XX w. teoria komputerów kwantowych i obliczeń kwantowych została uznana za Nowa okolica Nauki. Jak to często bywa w przypadku świetnych pomysłów, tak i tutaj trudno wskazać twórcę. Podobno węgierski matematyk J. von Neumann jako pierwszy zwrócił uwagę na możliwość rozwoju logiki kwantowej. Jednak w tamtym czasie nie powstały jeszcze nie tylko komputery kwantowe, ale także zwykłe, klasyczne komputery. Wraz z pojawieniem się tego ostatniego główne wysiłki naukowców miały na celu przede wszystkim znalezienie i opracowanie dla nich nowych elementów (tranzystorów, a następnie układów scalonych), a nie tworzenie zasadniczo różnych urządzeń komputerowych.
W 1960 roku Amerykański fizyk R. Landauer, który pracował w IBM, próbował zwrócić uwagę świata naukowego na fakt, że obliczenia są zawsze pewnym procesem fizycznym, co oznacza, że nie da się zrozumieć granic naszych możliwości obliczeniowych bez określenia, jakiej fizycznej realizacji one dotyczą. odpowiadać. Niestety, w tamtym czasie wśród naukowców dominował pogląd, że obliczenia są rodzajem abstrakcyjnej procedury logicznej, którą powinni badać matematycy, a nie fizycy.
W miarę upowszechniania się komputerów naukowcy kwantowi doszli do wniosku, że praktycznie niemożliwe jest bezpośrednie obliczenie stanu ewoluującego układu składającego się zaledwie z kilkudziesięciu oddziałujących ze sobą cząstek, takich jak cząsteczka metanu (CH 4). Tłumaczy się to tym, że aby w pełni opisać złożony układ, konieczne jest przechowywanie w pamięci komputera wykładniczo dużej (w sensie liczby cząstek) liczby zmiennych, tzw. amplitud kwantowych. Doszło do paradoksalnej sytuacji: znając równanie ewolucji, znając z wystarczającą dokładnością wszystkie potencjały interakcji cząstek ze sobą oraz stan początkowy układu, obliczenie jego przyszłości jest prawie niemożliwe, nawet jeśli układ składa się tylko z 30 elektronów w studni potencjału i jest tam superkomputer Baran, którego liczba bitów jest równa liczbie atomów w widzialnym obszarze Wszechświata (!). Jednocześnie, aby zbadać dynamikę takiego układu, można po prostu przeprowadzić eksperyment z 30 elektronami, umieszczając je w danym potencjale i stanie początkowym. Zauważył to w szczególności rosyjski matematyk Yu I. Manin, który w 1980 roku zwrócił uwagę na potrzebę opracowania teorii kwantowych urządzeń obliczeniowych. W latach 80. XX w. ten sam problem badał amerykański fizyk P. Benev, który wyraźnie pokazał, że układ kwantowy może wykonywać obliczenia, a także angielski naukowiec D. Deutsch, który teoretycznie opracował uniwersalny komputer kwantowy, przewyższający jego możliwości klasyczny odpowiednik.
Laureat Nagrody Nobla w dziedzinie fizyki R. Feynman, dobrze znany stałym czytelnikom „Science and Life”, zwrócił dużą uwagę na problematykę rozwoju komputerów kwantowych. Dzięki jego autorytatywnemu powołaniu liczba specjalistów zajmujących się obliczeniami kwantowymi wielokrotnie wzrosła.
Ale nadal przez długi czas Nie było jasne, czy hipotetyczną moc obliczeniową komputera kwantowego można wykorzystać do przyspieszenia rozwiązywania problemów praktycznych. Ale w 1994 roku amerykański matematyk, pracownik Lucent Technologies (USA) P. Shore oszołomiony świat naukowy, proponując algorytm kwantowy pozwalający na szybką faktoryzację dużych liczb (waga tego problemu była już omawiana we wstępie). W porównaniu do najbardziej znanych dzisiaj metody klasyczne Algorytm kwantowy Shora zapewnia wielokrotne przyspieszenie obliczeń, a im dłuższa liczba jest uwzględniana, tym większy przyrost prędkości. Algorytm szybkiej faktoryzacji ma duże znaczenie praktyczne dla różnych agencji wywiadowczych, które zgromadziły banki niezaszyfrowanych wiadomości.
W 1996 roku kolega Shora z Lucent Technologies L. Grover zaproponował algorytm kwantowy Szybkie wyszukiwanie w nieuporządkowanej bazie danych. (Przykładem takiej bazy danych jest książka telefoniczna, w której nazwiska abonentów ułożone są nie alfabetycznie, lecz w sposób dowolny.) Z zadaniem wyszukania, wybrania optymalnego elementu spośród wielu opcji spotykamy się bardzo często w branżach gospodarczej, wojskowej, problemy inżynieryjne, V gry komputerowe. Algorytm Grovera pozwala nie tylko przyspieszyć proces wyszukiwania, ale także w przybliżeniu podwoić liczbę parametrów branych pod uwagę przy wyborze optymalnego.
Prawdziwe stworzenie komputerów kwantowych utrudniał w zasadzie jedyny poważny problem – błędy, czyli zakłócenia. Faktem jest, że ten sam poziom zakłóceń psuje proces obliczeń kwantowych znacznie intensywniej niż obliczenia klasyczne. Sposobów rozwiązania tego problemu nakreślił P. Shor w 1995 roku, opracowując schemat kodowania stanów kwantowych i korygowania w nich błędów. Niestety, temat korekcji błędów w komputerach kwantowych jest tak ważny, że trudno go omówić w tym artykule.
URZĄDZENIE KOMPUTERA KWANTOWEGO
Zanim opowiemy Wam, jak działa komputer kwantowy, przypomnijmy sobie główne cechy układów kwantowych (patrz także „Science and Life” nr 8, 1998; nr 12, 2000).
Aby zrozumieć prawa świata kwantowego, nie należy opierać się bezpośrednio na codziennym doświadczeniu. W zwyczajny (w potocznym rozumieniu) cząstki kwantowe zachowują się tylko wtedy, gdy stale im się „podglądamy”, czyli, ściślej mówiąc, stale mierzymy stan, w jakim się znajdują. Ale gdy tylko się „odwrócimy” (przestaniemy obserwować), cząstki kwantowe natychmiast przechodzą z bardzo specyficznego stanu w kilka różnych form jednocześnie. Oznacza to, że elektron (lub jakikolwiek inny obiekt kwantowy) będzie częściowo zlokalizowany w jednym punkcie, częściowo w innym, częściowo w trzecim itd. Nie oznacza to, że jest podzielony na plasterki, jak pomarańcza. Wtedy możliwe byłoby wiarygodne wyizolowanie jakiejś części elektronu i zmierzenie jego ładunku lub masy. Jednak doświadczenie pokazuje, że po pomiarze elektron zawsze okazuje się „bezpieczny” w jednym punkcie, mimo że wcześniej udawało mu się być niemal wszędzie w tym samym czasie. Nazywa się ten stan elektronu, gdy znajduje się on w kilku punktach przestrzeni jednocześnie superpozycja stanów kwantowych i są zwykle opisywane funkcją falową, wprowadzoną w 1926 roku przez niemieckiego fizyka E. Schrödingera. Kwadrat modułu wartości funkcji falowej w dowolnym punkcie określa prawdopodobieństwo znalezienia cząstki w tym punkcie ten moment. Po zmierzeniu położenia cząstki jej funkcja falowa wydaje się kurczyć (zapadać) do punktu, w którym cząstka została wykryta, a następnie ponownie zaczyna się rozprzestrzeniać. Właściwość cząstek kwantowych bycia w wielu stanach jednocześnie, tzw równoległość kwantowa, został z powodzeniem zastosowany w obliczeniach kwantowych.
Bit kwantowy
Podstawową komórką komputera kwantowego jest bit kwantowy, czyli w skrócie kubit(q-bit). Ten cząstka kwantowa, mający dwa podstawowe stany, które są oznaczone 0 i 1 lub, jak to jest zwyczajowo w mechanice kwantowej, i. Dwie wartości kubitu mogą odpowiadać np. stanowi podstawowemu i wzbudzonemu atomu, kierunkowi wirowania jądra atomowego w górę i w dół, kierunkowi prądu w pierścieniu nadprzewodzącym, dwóm możliwym położeniom elektron w półprzewodniku itp.
Rejestr kwantowy
Rejestr kwantowy ma strukturę prawie taką samą jak rejestr klasyczny. Jest to łańcuch bitów kwantowych, na którym można wykonywać jedno- i dwubitowe operacje logiczne (podobnie jak w przypadku operacji NOT, 2I-NOT itp. na rejestrze klasycznym).
Podstawowe stany rejestru kwantowego utworzonego z kubitów L obejmują, podobnie jak w klasycznym, wszystkie możliwe ciągi zer i jedynek o długości L. Łącznie może istnieć 2 L różnych kombinacji. Można je uznać za zapis liczb w postaci binarnej od 0 do 2 L -1 i oznaczyć. Te stany podstawowe nie wyczerpują jednak wszystkich możliwych wartości rejestru kwantowego (w przeciwieństwie do klasycznego), gdyż istnieją również stany superpozycji określone przez zespolone amplitudy powiązane warunkiem normalizacji. Klasyczny analog dla większości możliwych wartości rejestru kwantowego (z wyjątkiem podstawowych) po prostu nie istnieje. Stany rejestru klasycznego są tylko żałosnym cieniem całego bogactwa stanów komputera kwantowego.
Wyobraź sobie, że na rejestr działa zewnętrzny wpływ, na przykład impulsy elektryczne są przykładane do części przestrzeni lub kierowane są wiązki lasera. Jeżeli jest to rejestr klasyczny, impuls, który można uznać za operację obliczeniową, spowoduje zmianę L zmiennych. Jeśli jest to rejestr kwantowy, to ten sam impuls może jednocześnie zostać zamieniony na zmienne. Zatem rejestr kwantowy jest w zasadzie w stanie przetwarzać informacje kilka razy szybciej niż jego klasyczny odpowiednik. Stąd od razu widać, że małe rejestry kwantowe (L<20) могут служить лишь для демонстрации отдельных узлов и принципов работы квантового компьютера, но не принесут большой практической пользы, так как не сумеют обогнать современные ЭВМ, а стоить будут заведомо дороже. В действительности квантовое ускорение обычно значительно меньше, чем приведенная грубая оценка сверху (это связано со сложностью получения большого количества амплитуд и считывания результата), поэтому практически полезный квантовый компьютер должен содержать тысячи кубитов. Но, с другой стороны, понятно, что для достижения действительного ускорения вычислений нет необходимости собирать миллионы квантовых битов. Компьютер с памятью, измеряемой всего лишь в килокубитах, будет в некоторых задачах несоизмеримо быстрее, чем классический суперкомпьютер с терабайтами памяти.
Warto jednak zaznaczyć, że istnieje klasa problemów, dla których algorytmy kwantowe nie zapewniają znacznego przyspieszenia w porównaniu do algorytmów klasycznych. Jednym z pierwszych, który to pokazał, był rosyjski matematyk Yu Ozhigov, który skonstruował szereg przykładów algorytmów, których w zasadzie nie można przyspieszyć jednym cyklem zegara na komputerze kwantowym.
Nie ulega jednak wątpliwości, że komputery działające zgodnie z prawami mechaniki kwantowej stanowią nowy i decydujący etap w ewolucji systemów obliczeniowych. Pozostaje tylko je zbudować.
KOMPUTERY KWANTOWE DZIŚ
Prototypy komputerów kwantowych istnieją już dzisiaj. To prawda, że dotychczas udało się eksperymentalnie złożyć jedynie małe rejestry składające się z zaledwie kilku bitów kwantowych. Dlatego niedawno grupa kierowana przez amerykańskiego fizyka I. Changa (IBM) ogłosiła zbudowanie 5-bitowego komputera kwantowego. Bez wątpienia jest to duży sukces. Niestety istniejące systemy kwantowe nie są jeszcze w stanie zapewnić wiarygodnych obliczeń, ponieważ są albo słabo kontrolowane, albo bardzo podatne na szum. Nie ma jednak fizycznych ograniczeń w zbudowaniu efektywnego komputera kwantowego; konieczne jest jedynie pokonanie trudności technologicznych.
Istnieje kilka pomysłów i propozycji dotyczących wytwarzania niezawodnych i łatwych do kontrolowania bitów kwantowych.
I. Chang rozwija pomysł wykorzystania spinów jąder niektórych cząsteczek organicznych jako kubitów.
Rosyjski badacz M.V. Feigelman, pracujący w Instytucie Fizyki Teoretycznej im. L.D. Landau RAS proponuje złożenie rejestrów kwantowych z miniaturowych pierścieni nadprzewodzących. Każdy pierścień pełni rolę kubitu, a stany 0 i 1 odpowiadają kierunkowi prądu elektrycznego w pierścieniu – zgodnie z ruchem wskazówek zegara i przeciwnie do ruchu wskazówek zegara. Takie kubity można przełączać za pomocą pola magnetycznego.
W Instytucie Fizyki i Technologii Rosyjskiej Akademii Nauk grupa kierowana przez akademika K. A. Valiewa zaproponowała dwie opcje umieszczania kubitów w strukturach półprzewodnikowych. W pierwszym przypadku rolę kubitu pełni elektron w układzie dwóch studni potencjału utworzonych przez napięcie przyłożone do minielektrod na powierzchni półprzewodnika. Stany 0 i 1 to pozycje elektronu w jednej z tych studzienek. Kubit przełączany jest poprzez zmianę napięcia na jednej z elektrod. W innej wersji kubit jest jądrem atomu fosforu osadzonym w pewnym punkcie półprzewodnika. Stany 0 i 1 - kierunki spinu jądrowego wzdłuż lub pod zewnętrznym polem magnetycznym. Sterowanie odbywa się za pomocą połączonego działania impulsów magnetycznych o częstotliwości rezonansowej i impulsów napięciowych.
Badania są więc aktywnie prowadzone i można przypuszczać, że w najbliższej przyszłości – za około dziesięć lat – powstanie efektywny komputer kwantowy.
SPOJRZENIE W PRZYSZŁOŚĆ
Jest zatem całkiem możliwe, że w przyszłości komputery kwantowe będą produkowane tradycyjnymi metodami technologii mikroelektronicznej i będą zawierały wiele elektrod sterujących, przypominających nowoczesny mikroprocesor. Aby zmniejszyć poziom hałasu, który jest krytyczny dla normalnej pracy komputera kwantowego, pierwsze modele najwyraźniej będą musiały być chłodzone ciekłym helem. Jest prawdopodobne, że pierwsze komputery kwantowe będą nieporęcznymi i drogimi urządzeniami, które nie zmieszczą się na biurku, a których konserwacją zajmie się liczna kadra programistów systemowych i dopasowywaczy sprzętu w białych fartuchach. W pierwszej kolejności dostęp do nich będą miały jedynie agencje rządowe, a następnie zamożne organizacje komercyjne. Ale era konwencjonalnych komputerów rozpoczęła się mniej więcej w ten sam sposób.
Co stanie się z klasycznymi komputerami? Czy wymrą? Ledwie. Zarówno komputery klasyczne, jak i kwantowe mają swoje własne obszary zastosowań. Chociaż najprawdopodobniej stosunek na rynku będzie stopniowo przesuwał się w stronę tego drugiego.
Wprowadzenie komputerów kwantowych nie doprowadzi do rozwiązania zasadniczo nierozwiązywalnych klasycznych problemów, a jedynie przyspieszy niektóre obliczenia. Ponadto możliwa stanie się komunikacja kwantowa - przesyłanie kubitów na odległość, co doprowadzi do powstania swego rodzaju kwantowego Internetu. Komunikacja kwantowa umożliwi zapewnienie bezpiecznego (zgodnie z prawami mechaniki kwantowej) połączenia wszystkich ze sobą przed podsłuchem. Twoje informacje przechowywane w kwantowych bazach danych będą lepiej chronione przed kopiowaniem niż obecnie. Firmy produkujące programy dla komputerów kwantowych będą mogły zabezpieczyć je przed wszelkim, także nielegalnym, kopiowaniem.
Dla głębszego zrozumienia tego tematu można przeczytać artykuł poglądowy E. Riffela i V. Polaka „Fundamentals of Quantum Computing” opublikowany w rosyjskim czasopiśmie „Quantum Computers and Quantum Computing” (nr 1, 2000). (Nawiasem mówiąc, jest to pierwsze i jak dotąd jedyne czasopismo na świecie poświęcone informatyce kwantowej. Dodatkowe informacje na ten temat można znaleźć w Internecie pod adresem http://rcd.ru/qc.). Po opanowaniu tej pracy będziesz mógł czytać artykuły naukowe na temat obliczeń kwantowych.
Nieco bardziej wstępne przygotowanie matematyczne będzie wymagane przy lekturze książki A. Kitaeva, A. Shena, M. Vyaly’a „Classical and Quantum Computations” (Moskwa: MTsNMO-CheRo, 1999).
Szereg podstawowych aspektów mechaniki kwantowej, niezbędnych do przeprowadzania obliczeń kwantowych, omawianych jest w książce V. V. Belokurowa, O. D. Timofeevskiej, O. A. Khrustalev „Quantum teleportation – a common cud” (Iżewsk: RHD, 2000).
Wydawnictwo RCD przygotowuje się do wydania w osobnej książce tłumaczenia recenzji A. Steena na temat komputerów kwantowych.
Poniższa literatura będzie przydatna nie tylko edukacyjnie, ale także historycznie:
1) Yu. I. Manin. Obliczalne i nieobliczalne.
M.: Sow. radio, 1980 rok.
2) J. von Neumanna. Matematyczne podstawy mechaniki kwantowej.
M.: Nauka, 1964.
3) R. Feynmana. Symulacja fizyki na komputerach // Komputer kwantowy i obliczenia kwantowe:
sob. w 2 tomach - Iżewsk: RHD, 1999. T. 2, s. 1. 96-123.
4) R. Feynmana. Komputery mechaniki kwantowej
// Tamże, s. 123.-156.
Zobacz problem na ten sam temat
Stworzenie uniwersalnego komputera kwantowego to jedno z najtrudniejszych zadań współczesnej fizyki, którego rozwiązanie radykalnie zmieni rozumienie przez ludzkość Internetu i sposobów przesyłania informacji, cyberbezpieczeństwa i kryptografii, walut elektronicznych, sztucznej inteligencji i systemów uczenia maszynowego, metody syntezy nowych materiałów i leków, podejścia do modelowania złożonych systemów fizycznych, kwantowych i ultradużych (Big Data).
Wykładniczy wzrost wymiarowości przy próbach obliczania systemów rzeczywistych lub najprostszych układów kwantowych jest przeszkodą nie do pokonania dla klasycznych komputerów. Jednak w 1980 roku Yuri Manin i Richard Feynman (w 1982 roku, ale bardziej szczegółowo) niezależnie przedstawili pomysł wykorzystania układów kwantowych do obliczeń. W przeciwieństwie do klasycznych współczesnych komputerów, obwody kwantowe do obliczeń wykorzystują kubity (bity kwantowe), które ze swej natury są kwantowymi układami dwupoziomowymi i umożliwiają bezpośrednie wykorzystanie zjawiska superpozycji kwantowej. Innymi słowy oznacza to, że kubit może jednocześnie znajdować się w stanach |0> i |1>, a dwa połączone ze sobą kubity mogą jednocześnie znajdować się w stanach |00>, |10>, |01> i |11>. To właśnie ta właściwość systemów kwantowych powinna zapewnić wykładniczy wzrost wydajności obliczeń równoległych, dzięki czemu komputery kwantowe będą miliony razy szybsze niż najpotężniejsze współczesne superkomputery.
W 1994 roku Peter Shor zaproponował algorytm kwantowy rozkładający liczby na czynniki pierwsze. Kwestia istnienia skutecznego klasyczne rozwiązanie Zagadnienie to jest niezwykle istotne i wciąż otwarte, natomiast algorytm kwantowy Shora zapewnia przyspieszenie wykładnicze w stosunku do najlepszego klasycznego analogu. Na przykład nowoczesny superkomputer w zakresie petaflopów (10,15 operacji/s) może rozwiązać liczbę z dokładnością do 500 miejsc po przecinku w ciągu 5 miliardów lat; komputer kwantowy w zakresie megaherców (10,6 operacji/s) rozwiązałby ten sam problem 18 sekund. Warto zauważyć, że złożoność rozwiązania tego problemu leży u podstaw popularnego algorytmu bezpieczeństwa kryptograficznego RSA, który po stworzeniu komputera kwantowego po prostu straci na znaczeniu.
W 1996 roku Lov Grover zaproponował algorytm kwantowy do rozwiązywania problemu wyliczania (wyszukiwania) z przyspieszeniem kwadratowym. Pomimo tego, że przyspieszenie algorytmu Grovera jest zauważalnie mniejsze niż algorytmu Shora, ważny jest jego szeroki zakres zastosowań i oczywista niemożność przyspieszenia klasycznej wersji brutalnej siły. Obecnie znanych jest ponad 40 efektywnych algorytmów kwantowych, z których większość opiera się na ideach algorytmów Shora i Grovera, których wdrożenie stanowi ważny krok w kierunku stworzenia uniwersalnego komputera kwantowego.
Implementacja algorytmów kwantowych jest jednym z priorytetowych zadań Centrum Badawczego Fizyki i Matematyki. Nasze badania w tym obszarze mają na celu opracowanie wielokubitowych nadprzewodzących kwantowych układów scalonych do tworzenia uniwersalnych systemów przetwarzania informacji kwantowej i symulatorów kwantowych. Podstawowym elementem takich obwodów są złącza tunelowe Josephsona, składające się z dwóch nadprzewodników oddzielonych cienką barierą – dielektrykiem o grubości około 1 nm. Kubity nadprzewodzące oparte na złączach Josephsona po schłodzeniu w kriostatach rozpuszczających do temperatury bliskiej zero absolutne(~20 mK) wykazują właściwości mechaniki kwantowej, wykazując kwantyzację ładunku elektrycznego (kubity ładunku), fazy lub strumienia pola magnetycznego (kubity strumienia) w zależności od ich konstrukcji. Pojemnościowe lub indukcyjne elementy sprzęgające, a także nadprzewodzące rezonatory współpłaszczyznowe służą do łączenia kubitów w obwody, a sterowanie odbywa się za pomocą impulsów mikrofalowych o kontrolowanej amplitudzie i fazie. Obwody nadprzewodzące są szczególnie atrakcyjne, ponieważ można je wytwarzać przy użyciu technologii mas planarnych stosowanych w przemyśle półprzewodników. W Centrum Badawczym Fizyki i Matematyki wykorzystujemy aparaturę (klasy R&D) wiodących światowych producentów, specjalnie dla nas zaprojektowaną i stworzoną, z uwzględnieniem specyfiki procesów technologicznych wytwarzania nadprzewodzących kwantowych układów scalonych.
Chociaż w ciągu ostatnich 15 lat jakość nadprzewodzących kubitów poprawiła się o prawie kilka rzędów wielkości, nadprzewodzące kwantowe układy scalone są nadal bardzo niestabilne w porównaniu z klasycznymi procesorami. Zbudowanie niezawodnego, uniwersalnego wielokubitowego komputera kwantowego wymaga rozwiązania dużej liczby problemów fizycznych, technologicznych, architektonicznych i algorytmicznych. Utworzono REC ds. Fizyki i Matematyki kompleksowy program prace badawczo-rozwojowe w kierunku stworzenia wielokubitowych nadprzewodnikowych obwodów kwantowych, w tym:
- metody powstawania i badania nowych materiałów i interfejsów;
- projektowania i technologii wytwarzania elementów obwodów kwantowych;
- skalowalne wytwarzanie wysoce spójnych kubitów i wysokiej jakości rezonatorów;
- tomografia (pomiary charakterystyczne) kubitów nadprzewodzących;
- sterowanie kubitami nadprzewodzącymi, przełączanie kwantowe (splątanie);
- metody wykrywania błędów i algorytmy korekcji błędów;
- rozwój wielokubitowej architektury obwodów kwantowych;
- nadprzewodnikowe wzmacniacze parametryczne z kwantowym poziomem szumu.
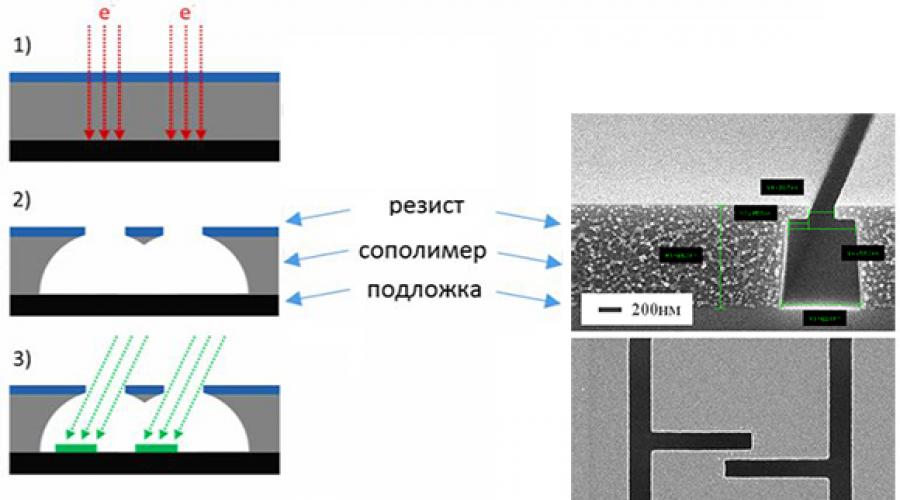
Ze względu na swoje nieliniowe właściwości z bardzo niskimi stratami (z natury) i skalowalność (wytwarzaną metodami litograficznymi), złącza Josephsona są niezwykle atrakcyjne do tworzenia kwantowych obwodów nadprzewodzących. Często, aby wyprodukować obwód kwantowy, konieczne jest utworzenie w krysztale np setek i tysięcy złączy Josephsona o charakterystycznych wymiarach rzędu 100 nm. W której niezawodne działanie obwodów jest realizowany tylko wtedy, gdy parametry przejść są dokładnie odwzorowane. Innymi słowy, wszystkie przejścia obwodów kwantowych muszą być absolutnie identyczne. W tym celu korzystają z najnowocześniejszych metod litografii wiązką elektronów, a następnie precyzyjnego osadzania cienia za pomocą masek rezystancyjnych lub sztywnych.

Tworzenie złącz Josephsona odbywa się standardowymi metodami litografii o ultrawysokiej rozdzielczości przy użyciu dwuwarstwowych masek rezystancyjnych lub sztywnych. Po opracowaniu takiej dwuwarstwowej maski powstają okna do osadzania warstw nadprzewodników pod takimi kątami, że procesy te powodują nakładanie się osadzonych warstw. Przed osadzeniem drugiej warstwy nadprzewodnika tworzy się bardzo wysokiej jakości dielektryczna warstwa tunelowa złącza Josephsona. Po utworzeniu połączeń Josephsona usuwa się dwuwarstwową maskę. Jednocześnie na każdym etapie powstawania przejścia krytycznym czynnikiem jest stworzenie „idealnych” interfejsów – nawet zanieczyszczenie atomowe radykalnie pogarsza parametry wytwarzanych obwodów jako całości.
FMN opracowało technologię aluminiową do tworzenia złączy Josephsona Al–AlOx–Al minimalne rozmiary w zakresie 100-500 nm, a powtarzalność parametrów przejścia względem prądu krytycznego jest nie gorsza niż 5%. Ciągłe badania technologiczne mają na celu poszukiwanie nowych materiałów, udoskonalanie operacji technologicznych formowania przejść i podejść do integracji z nową trasą procesy technologiczne oraz zwiększenie powtarzalności wytwarzania złączy przy zwiększeniu ich liczby do kilkudziesięciu tysięcy sztuk na chipie.
Kubity Josephsona (kwantowy układ dwupoziomowy lub „sztuczny atom”) charakteryzują się typowym podziałem energii podstawowego stanu wzbudzonego na poziomy i są napędzane standardowymi impulsami mikrofalowymi (zewnętrzna regulacja odległości między poziomami a stanami własnymi) przy częstotliwość podziału w zakresie gigaherców. Wszystkie kubity nadprzewodzące można podzielić na kubity ładunkowe (kwantyzacja ładunku elektrycznego) i kubity przepływu (kwantyzacja pola magnetycznego lub fazy), a głównymi kryteriami jakości kubitów z punktu widzenia obliczeń kwantowych są czas relaksacji (T1), czas koherencji (T2, rozfazowanie) i czas wykonania jednej operacji. Pierwszy kubit ładunkowy został zrealizowany w laboratorium NEC (Japonia) przez grupę naukową pod przewodnictwem Y. Nakamury i Yu Pashkina (Nature 398, 786–788, 1999). W ciągu ostatnich 15 lat wiodące grupy badawcze poprawiły czasy koherencji nadprzewodzących kubitów o prawie sześć rzędów wielkości, od nanosekund do setek mikrosekund, umożliwiając setki operacji na dwóch kubitach i algorytmy korekcji błędów.

W REC FMS opracowujemy, produkujemy i testujemy kubity ładunku i przepływu różne projekty(streaming, fluxoni, transmon 2D/3D, X-mon itp.) z aluminiowymi złączami Josephsona prowadzimy badania nad nowymi materiałami i metodami tworzenia wysoce spójnych kubitów, mających na celu poprawę podstawowych parametrów kubitów nadprzewodzących.
Specjaliści centrum opracowują cienkowarstwowe linie transmisyjne oraz wysokiej jakości rezonatory nadprzewodzące o częstotliwościach rezonansowych z zakresu 3-10 GHz. Wykorzystywane są w obwodach kwantowych i pamięciach do obliczeń kwantowych, umożliwiając kontrolę poszczególnych kubitów, komunikację między nimi oraz odczyt ich stanów w czasie rzeczywistym. Głównym zadaniem jest tutaj zwiększenie współczynnika jakości struktur powstałych w reżimie jednofotonowym w niskich temperaturach.

W celu doskonalenia parametrów rezonatorów nadprzewodzących prowadzimy badania nad różnymi typami ich konstrukcji, materiałami cienkowarstwowymi (aluminium, niob, azotek niobu), metodami osadzania warstw (wiązka elektronów, magnetron, warstwa atomowa) oraz kształtowaniem topologii ( litografia wybuchowa, różne procesy trawienia) na różnych podłożach (krzem, szafir) i integracja różne materiały w jednym schemacie.
Grupy naukowe z różnych dziedzin fizyki od dawna badają możliwość spójnego oddziaływania (komunikacji) kwantowych układów dwupoziomowych z kwantowymi oscylatorami harmonicznymi. Do 2004 roku taką interakcję można było osiągnąć jedynie w eksperymentach z fizyki atomowej i optyki kwantowej, gdzie pojedynczy atom spójnie wymienia pojedynczy foton z promieniowaniem jednomodowym. Eksperymenty te wniosły ogromny wkład w zrozumienie mechanizmów oddziaływania światła z materią, Fizyka kwantowa, fizyka koherencji i dekoherencji, a także potwierdzone podstawy teoretyczne koncepcje obliczeń kwantowych. Jednak w 2004 roku zespół badawczy kierowany przez A. Wallraffa (Nature 431, 162-167 (2004)) jako pierwszy zademonstrował możliwość spójnego sprzężenia półprzewodnikowego obwodu kwantowego z pojedynczym fotonem mikrofalowym. Dzięki tym eksperymentom i po rozwiązaniu szeregu problemów technologicznych opracowano zasady tworzenia kontrolowanych dwupoziomowych układów kwantowych w stanie stałym, które stały się podstawą nowy paradygmat W ostatnich latach aktywnie badano obwody elektrodynamiki kwantowej (obwody QED).

Obwody QED są niezwykle atrakcyjne zarówno z punktu widzenia badania cech interakcji różnych elementów układów kwantowych, jak i tworzenia urządzeń kwantowych do praktycznego zastosowania. Badamy różne typy schematów interakcji dla elementów obwodu QED: efektywna komunikacja kubity i elementy sterujące, rozwiązania obwodów splątania kubitów, nieliniowość kwantowa interakcji elementów z małą liczbą fotonów itp. Badania te mają na celu opracowanie podstaw praktycznych metod eksperymentalnych tworzenia wielokubitowych kwantowych układów scalonych.
Głównym celem badań w tym kierunku w FMS jest opracowanie technologii tworzenia bazy metrologicznej, metodologicznej i algorytmicznej do implementacji algorytmów Shora i Grovera z wykorzystaniem wielokubitowych obwodów kwantowych i wykazania przyspieszenia kwantowego w porównaniu z klasycznymi superkomputerami. To niezwykle ambitne zadanie naukowo-techniczne wymaga rozwiązania kolosalnej liczby problemów teoretycznych, fizycznych, technologicznych, projektowania obwodów, metrologicznych i algorytmicznych, nad którymi obecnie aktywnie pracują wiodące grupy naukowe i firmy informatyczne.

Badania i rozwój w dziedzinie obliczeń kwantowych prowadzone są w ścisłej współpracy z wiodącymi rosyjskimi zespołami naukowymi Instytutu Fizyki i Technologii Rosyjskiej Akademii Nauk, MISIS, MIPT, NSTU i RKTs pod kierownictwem światowej sławy rosyjskich naukowców .
Odniesienie historyczne
Obliczenia kwantowe są nie do pomyślenia bez kontroli stanu kwantowego poszczególnych cząstek elementarnych. Udało się to dwóm fizykom – Francuzowi Serge’owi Lroche i Amerykaninowi Davidowi Winelandowi. Lrosh wychwytywał pojedyncze fotony w rezonatorze i na długi czas „odczepiał” je od świata zewnętrznego. Wineland uwięził pojedyncze jony w określonych stanach kwantowych i odizolował je od wpływów zewnętrznych. Harosh użył atomów do obserwacji stanu fotonu. Wineland wykorzystał fotony do zmiany stanu jonów. Udało im się poczynić postępy w badaniu relacji między światem kwantowym i klasycznym. W 2012 roku zostali nagrodzeni nagroda Nobla w fizyce za „przełom metody eksperymentalne, co umożliwiło pomiar i kontrolę poszczególnych układów kwantowych.”
Działanie komputerów kwantowych opiera się na właściwościach kwantowego bitu informacji. Jeśli procesy obliczeniowe używają P kubitów, wówczas przestrzeń stanów Hilberta układu kwantowego ma wymiar równy 2”. przestrzeń Hilberta będziemy rozumieć wymiarową przestrzeń wektorową, w której iloczyn skalarny jest zdefiniowany pod warunkiem, że wartość dąży P do nieskończoności.
W naszym przypadku oznacza to, że istnieją 2" stany bazowe i komputer może działać w oparciu o superpozycję tych 2" stanów bazowych.
Należy pamiętać, że wpływ na dowolny kubit natychmiast prowadzi do jednoczesnej zmiany wszystkich 2-calowych stanów podstawowych. Ta właściwość nazywa się „Równoległość kwantowa».
Obliczenia kwantowe to transformacja unitarna. Oznacza to, że transformację liniową przeprowadza się przy współczynnikach zespolonych, zachowując niezmienioną sumę kwadratów przekształconych zmiennych. Transformacja jednostkowa jest transformacją ortogonalną, w której współczynniki tworzą macierz jednostkową.
Pod macierz jednostkowa zrozumiemy macierz kwadratową ||aj|, której iloczyn przez zespoloną macierz sprzężoną i transponowaną || aJI daje macierz tożsamości. Liczby ajk I ki złożony. Jeśli liczby ik są liczbami rzeczywistymi, to macierz unitarna będzie ortogonalna. Określona liczba kubitów tworzy rejestr kwantowy komputera. W takim łańcuchu bitów kwantowych jedno- i dwubitowe operacje logiczne można przeprowadzać w taki sam sposób, jak operacje NOT, NAND, 2 OR-HE itp. przeprowadza się na rejestrze klasycznym. (ryc. 5.49).
Konkretny numer N rejestry tworzą zasadniczo komputer kwantowy. Działanie komputera kwantowego odbywa się zgodnie z opracowanymi algorytmami obliczeniowymi.
Ryż. 5,49.
NIE - wartość logiczna NIE; CNOT – kontrolowane NIE
Kubity jako nośniki informacji posiadają szereg ciekawych właściwości, które całkowicie odróżniają je od klasycznych bitów. Jedna z głównych tez teorii informacji kwantowej brzmi uwikłanie państwowe. Załóżmy, że istnieją dwa dwupoziomowe kubity A I W, realizowany w postaci atomu o spinie elektronowym lub jądrowym, cząsteczki o dwóch spinach jądrowych. Ze względu na interakcję dwóch podsystemów A I W powstaje nielokalna korelacja o charakterze czysto kwantowym. Korelację tę można opisać za pomocą macierzy gęstości stanu mieszanego
Gdzie Liczba Pi- populacja lub prawdopodobieństwo I- stan, tak R ( + str. 2 + str. 3 + + Ra = 1-
Właściwość spójnych stanów kwantowych polegająca na tym, że suma prawdopodobieństw jest równa jedności, nazywa się splątaniem lub sprzężeniem stanów. Splątane lub splątane obiekty kwantowe są ze sobą połączone bez względu na to, jak daleko od siebie się znajdują. Jeśli zmierzony zostanie stan jednego z powiązanych obiektów, wówczas natychmiast uzyskana zostanie informacja o stanie pozostałych obiektów.
Jeśli dwa kubity są ze sobą powiązane, to są one pozbawione indywidualnych stanów kwantowych. Zależą od siebie w ten sposób, że pomiar dla jednego typu daje „O”, a dla drugiego „1” i odwrotnie (ryc. 5.50). W tym przypadku mówi się, że maksymalnie połączona para niesie jeden e-bit spójność.
Stany splątane są zasobem w kwantowych urządzeniach obliczeniowych i aby uzupełnić liczbę stanów splątanych, należy opracować metody niezawodnego generowania splątanych kubitów. Jedna z metod

Ryż. 5,50. Schemat maksymalnie splątanej pary kubitów to algorytmiczny sposób uzyskania splątanych kubitów na jonach w pułapkach, spinach jądrowych lub parze fotonów. Proces rozpadu cząstki w stanie singletowym na dwie cząstki może być bardzo efektywny. W tym przypadku generowane są pary cząstek splątanych pod względem współrzędnych, pędu lub spinu.
Opracowanie wszechstronnej teorii splątania jest kluczowym celem kwantowej teorii informacji. Za jego pomocą możliwe będzie zbliżenie się do rozwiązania problemów teleportacji, ultragęstego kodowania, kryptografii i kompresji danych. W tym celu opracowywane są algorytmy kwantowe, w tym kwantowe transformaty Fouriera.
Schemat obliczeń na komputerze kwantowym opiera się na następującym algorytmie: tworzony jest układ kubitów, na którym zapisywany jest stan początkowy. Poprzez transformacje unitarne stan systemu i jego podsystemów zmienia się podczas wykonywania operacji logicznych. Proces kończy się pomiarem nowych wartości kubitów. Rolę łączenia przewodników klasycznego komputera pełnią kubity, a bloki logiczne klasycznego komputera pełnią transformacje unitarne. Ta koncepcja procesora kwantowego i kwantowych bramek logicznych została sformułowana w 1989 roku przez Davida Deutscha. Następnie zaproponował uniwersalny blok logiczny, który można wykorzystać do wykonania dowolnych obliczeń kwantowych.
Algorytm Doina-Jozhi pozwala określić „w jednym obliczeniu”, czy funkcja zmiennej binarnej /(/?) jest stała (f x (ri)= Och, fa 2 (ri) = 1 niezależnie od tego P) lub „zrównoważony” (f 3 ( 0) = 0,/ 3 (1) = 1;/ 4 (0) = 1, / 4 (1) = 0).
Okazało się, że do skonstruowania dowolnego obliczenia wystarczą dwie podstawowe operacje. Układ kwantowy daje wynik, który jest poprawny tylko z pewnym prawdopodobieństwem. Ale nieznacznie zwiększając liczbę operacji w algorytmie, możesz zwiększyć prawdopodobieństwo uzyskania tak blisko, jak chcesz prawidłowy wynik do jednego. Wykorzystując podstawowe operacje kwantowe, można symulować działanie zwykłych bramek logicznych, z których zbudowane są zwykłe komputery.
Algorytm Grovera pozwala nam znaleźć rozwiązanie równania f(x) = 1 dla 0 x w czasie O(VN) i jest przeznaczony do przeszukiwania bazy danych. Algorytm kwantowy Grovera jest oczywiście bardziej wydajny niż jakikolwiek algorytm wyszukiwania nieuporządkowanego na klasycznym komputerze.
Algorytm faktoryzacji Shora pozwala określić czynniki pierwsze ok podana liczba całkowita M= a"Xb za pomocą odpowiedniego obwodu kwantowego. Algorytm ten pozwala znaleźć współczynniki liczby całkowitej A-cyfrowej. Można go wykorzystać do oszacowania czasu procesu obliczeniowego. Jednocześnie algorytm Shora można interpretować jako przykład procedury wyznaczania poziomów energii kwantowego systemu obliczeniowego.
Algorytm Zalki-Wiesnera pozwala symulować jednostkową ewolucję układu kwantowego P cząstek w czasie niemal liniowym przy użyciu NA) kubity
Algorytm Simona rozwiązuje problem czarnej skrzynki wykładniczo szybciej niż jakikolwiek klasyczny algorytm, w tym algorytmy probabilistyczne.
Algorytm korekcji błędów umożliwia zwiększenie odporności na zakłócenia kwantowego systemu obliczeniowego, który jest podatny na niszczenie delikatnych stanów kwantowych. Istotą tego algorytmu jest to, że nie wymaga on klonowania kubitów i określania ich stanu. Tworzony jest obwód logiki kwantowej, który jest w stanie wykryć błąd w dowolnym kubicie bez faktycznego odczytywania indywidualnego stanu. Na przykład triplet 010 przechodzący przez takie urządzenie wykrywa nieprawidłowy bit środkowy. Urządzenie odwraca go bez określania konkretnych wartości któregokolwiek z trzech bitów. Zatem w oparciu o teorię informacji i mechanikę kwantową powstał jeden z podstawowych algorytmów - korekcja błędów kwantowych.
Problemy te są ważne przy tworzeniu komputera kwantowego, ale wchodzą w zakres kompetencji programistów kwantowych.
Komputer kwantowy jest pod wieloma względami bardziej postępowy niż komputer klasyczny. Większość współczesnych komputerów działa według schematu von Neumanna lub Harvarda: P bity pamięci przechowują stan i są zmieniane przez procesor za każdym razem, gdy takt. W komputerze kwantowym system P kubity znajdują się w stanie będącym superpozycją wszystkich stanów bazowych, więc zmiana w systemie dotyka wszystkich 2" stany podstawowe jednocześnie. Teoretycznie nowy schemat może działać wykładniczo szybciej niż klasyczny. Niemal kwantowy algorytm przeszukiwania baz danych wykazuje kwadratowy wzrost mocy w porównaniu z algorytmami klasycznymi.
Od czasu do czasu dociera do nas lawina wiadomości na temat obliczeń kwantowych. Temat cieszy się dużym zainteresowaniem, a jedna firma twierdzi, że ma algorytm szyfrowania, którego wkrótce będziesz potrzebować, ponieważ komputery kwantowe sprawią, że obecne algorytmy szyfrowania staną się bezużyteczne.
Dla osoby dociekliwej takie stwierdzenia rodzą pytania. Co to jest przetwarzanie kwantowe (rysunek 1)? To jest prawdziwe? Jeśli tak, jak to działa? A jak to się ma do kryptografii? Potem pojawiają się bardziej osobiste pytania. Czy obliczenia kwantowe mogą zmienić sposób, w jaki projektuję? Czy powinienem przestudiować ten materiał?
Nawet w renderingach artystów elementy obliczeń kwantowych nie przypominają niczego w świecie sprzętu cyfrowego.
Rysunek 1 – Wizualizacja elementów obliczeń kwantowych
Okazuje się, że to nie za dużo proste pytania na naukę. Odpowiednia literatura należy głównie do jednego z dwóch gatunków. Pierwsza przeznaczona jest dla ogółu czytelników i traktuje mechanikę kwantową jak piekło: mroczną, być może niebezpieczną i całkowicie niezrozumiałą. Po zapoznaniu się z taką literaturą dość trudno jest wyciągnąć jakiekolwiek wnioski.
Drugi gatunek jest zupełnie inny, ale równie „użyteczny”, pisany przez ekspertów, aby zaimponować innym ekspertom. Gatunek ten charakteryzuje się użyciem terminów takich jak maszyna Turinga, nazwisko Richarda Feynmana, przestrzeń Hilberta i transformata Hadamarda, wszystkich powyższych i około 75 innych słów, po których następuje plątanina równań o nieznanej i niewytłumaczalnej terminologii. Oczywiście wszyscy dobrze pamiętacie, co oznacza |0>!
Trzy równoległe wszechświaty
Jednym z powodów, dla których ten temat jest tak złożony, jest fakt, że obliczenia kwantowe obejmują trzy dyscypliny o bardzo różnej terminologii i zainteresowaniach. Wszystko zaczęło się od fizyków teoretycznych. Już w 1980 roku fizyk Paul Benioff ( Paweł Benioff) z Argonne National Laboratory opisał, w jaki sposób można wykorzystać niektóre efekty mechaniki kwantowej do wdrożenia maszyny Turinga. Dwa lata później znany fizyk Richard Feynman poruszył także kwestię komputera wykorzystującego zachowanie kwantowe.
Ale pomysł podchwyciła zupełnie inna grupa: informatycy i matematycy. Czerpiąc z fizyki podstawowe pojęcia dotyczące bitu kwantowego (kubitu) i odwracalnych transformacji unitarnych (które nazywali bramkami kwantowymi lub kwantylami), informatycy badali, jakie obliczenia można by przeprowadzić, gdyby istniały idealne kubity i bramki kwantowe. Znaleźli przypadki, w których takie rzekome komputery mogły być znacznie szybsze niż konwencjonalne komputery cyfrowe.
Wynik ten skłonił fizyków eksperymentalnych – trzecią grupę – do rozpoczęcia prób tworzenia urządzenia fizyczne, które mogą być bliskie idealnym kubitom i bramkom kwantowym. Były to długie i wymagające dużych zasobów badania, które w dalszym ciągu nie udowodniły, że naprawdę działający komputer kwantowy jest fizycznie możliwy. Ale ta możliwość jest niezwykle zachęcająca.
Kilka wyjaśnień
Czym więc jest ten wyimaginowany komputer, który nas interesuje? Najpierw wyjaśnijmy pewne nieporozumienia. Komputer kwantowy nie jest zwykłym komputerem symulującym zjawiska mechaniki kwantowej. Nie jest to też zwykły komputer cyfrowy, zbudowany z kilku tranzystorów (z końca prawa Moore’a) na tyle małych, że przechowują lub przełączają poszczególne kwanty energii.
Zamiast tego komputery kwantowe są maszynami opartymi na unikalnym zachowaniu opisanym przez mechanikę kwantową i zupełnie odmiennym od zachowania systemy klasyczne. Jedną z tych różnic jest zdolność cząstki lub grupy cząstek pod pewnym względem do przebywania tylko w dwóch dyskretnych kwantowych stanach podstawowych - nazwijmy je 0 i 1. Obejdziemy się tutaj bez śmiesznych nawiasów (notacje przyjęte w teorii kwantów - dodane przez Przykładami tego rodzaju mogą być elektrony spinowe, polaryzacja fotonów lub ładunek kropki kwantowej.
Po drugie, obliczenia kwantowe zależą od właściwości superpozycji — sprzecznej z intuicją zdolności cząstki do przebywania w pewnej kombinacji obu stanów podstawowych 0 i 1 w tym samym czasie, aż do momentu dokonania pomiaru. Po zmierzeniu takiego stanu zmienia się on na 0 lub 1, a wszystkie inne informacje znikają. Mechanika kwantowa poprawnie opisuje taki połączony stan jako sumę dwóch podstawowych stanów, z których każdy jest pomnożony przez jakiś złożony czynnik. Pełny rozmiar tych współczynników jest zawsze równa 1. Stan taki można przedstawić jako wektor jednostkowy rozpoczynający się w początku i kończący się gdzieś na kuli zwanej sferą Blocha, co pokazano na rysunku 2. Kluczowy punkt stąd wynika, że kwadrat (moduł - dodany przez tłumacza) współczynnika zespolonego dla stanu bazowego 0 reprezentuje prawdopodobieństwo, że w wyniku pomiaru kubit znajdzie się w stanie bazowym 0, analogicznie dla stanu bazowego 1. A kiedy dokonasz pomiaru, zawsze otrzymasz lub dokładnie stan 0, lub dokładnie stan 1.
 Rysunek 2 – Sfera Blocha – jeden ze sposobów wizualizacji superpozycji kwantowej w kubicie
Rysunek 2 – Sfera Blocha – jeden ze sposobów wizualizacji superpozycji kwantowej w kubicie To (właściwość superpozycji - dodana przez tłumacza) jest ważna, ponieważ pozwala kubitowi znajdować się jednocześnie w obu stanach 0 i 1. Zatem rejestr składający się z n kubitów może jednocześnie „zawierać” wszystkie możliwe liczby binarne o długości n bitów. Dzięki temu komputer kwantowy może wykonać pojedynczą operację nie tylko na jednej n-bitowej liczbie całkowitej, ale na wszystkich możliwych n-bitowych liczbach całkowitych jednocześnie — bardzo znacząca równoległość w miarę wzrostu n.
Po trzecie, obliczenia kwantowe zależą od zdolności bramki kwantowej do zmiany tych współczynników, a co za tym idzie, od prawdopodobieństwa zmierzenia dowolnej liczby w przewidywalny sposób. Jeśli zaczniesz od stanu, w którym wszystkie współczynniki we wszystkich kubitach są równe, a następnie zmierzysz wszystkie kubity w rejestrze, z równym prawdopodobieństwem znajdziesz dowolny ciąg bitów pomiędzy ciągiem samych zer i ciągiem samych jedynek, włącznie. Jednak przepuszczając ten stan początkowy przez starannie wybraną sekwencję bramek kwantowych, komputer kwantowy może zmienić te współczynniki w taki sposób, że stan, który najprawdopodobniej zmierzysz jako wynik, będzie wynikiem pewnych obliczeń, na przykład jest bardzo prawdopodobne, że zmierzyć bity liczby będącej idealnym kwadratem.
Komputer na papierze
Ale co to wszystko ma wspólnego z prawdziwym przetwarzaniem? Aby odpowiedzieć na to pytanie, musimy przenieść naszą uwagę z fizyków teoretycznych na informatyków i matematyków. Aby uzyskać praktyczne wyniki, musimy być w stanie odwzorować rejestr kubitów na określoną superpozycję stanów. Potrzebujemy bramek kwantowych, ewentualnie przewodów i pewnego rodzaju urządzeń wyjściowych.
Wszystko to jest łatwe dla informatyków - mogą po prostu założyć, że te pomysły zostały już wdrożone w prawdziwym życiu. Będą jednak musieli pójść na ustępstwa na rzecz mechaniki kwantowej. Aby uniknąć łamania praw fizyki kwantowej, informatycy muszą wymagać, aby bramki kwantowe były odwracalne – można umieścić wynik na wyjściu i uzyskać prawidłowe wartości wejściowe na wejściu. I upierają się, że bramy kwantowe muszą być transformacjami unitarnymi. Według algebry macierzy oznacza to, że jeśli przepuścisz stan kubitu przez bramkę kwantową, wynikowy stan będzie miał wartość 0 lub 1, a suma prawdopodobieństw kwadratów tych współczynników pozostanie równa jedności.
Należy zauważyć, że te bramki kwantowe, nawet w teorii, bardzo różnią się od zwykłych bramek logicznych. Na przykład większość funkcji logicznych nie jest odwracalna. Niemożliwe jest wyprowadzenie danych wejściowych z bramki NAND, jeśli na wyjściu nie ma wartości 0. Bramki logiczne działają oczywiście tylko z jedynkami i zerami (stany 1 i 0), podczas gdy bramki kwantowe działają na zasadzie obracania wektora wewnątrz kuli Blocha. Tak naprawdę nie ma między nimi nic wspólnego poza nazwą.
Informatycy odkryli, że do emulacji maszyny Turinga wystarczy bardzo mały zestaw bramek kwantowych — wystarczy zestaw bramek kwantowych z jednym wejściem i jedna bramka kwantowa z dwoma wejściami. Najczęściej używanym przykładem dwuwejściowej bramki kwantowej jest „kontrolowana bramka NOT” (CNOT). Ta odwracalna funkcja albo odwraca stan wektorowy kubitu, albo pozostawia go bez zmian, w zależności od stanu drugiego kubitu. To bardziej przypomina kwantową analogię XOR.
Możliwe korzyści
Nadal nie odpowiedzieliśmy na pytanie, jak to wszystko można wykorzystać. Odpowiedź jest taka, że jeśli w odpowiedni sposób połączymy ze sobą wystarczającą liczbę bramek kwantowych i jeśli potrafimy przygotować kubity wejściowe reprezentujące wszystkie możliwe liczby w dziedzinie danych wejściowych, to na wyjściu układu bramek kwantowych można teoretycznie zmierzyć bity reprezentujące wartości jakiejś przydatnej funkcji.
Podajmy przykład. W 1994 roku matematyk Peter Shor z Bell Labs opracował algorytm rozkładu na czynniki bardzo dużych liczb przy użyciu procedur kwantowych. Ta faktoryzacja jest istotnym problemem w matematyce stosowanej, ponieważ nie ma rozwiązania analitycznego: jedynym sposobem jest metoda prób i błędów, a przyspieszenie algorytmu można osiągnąć jedynie poprzez umiejętniejszy dobór odpowiednich numerów prób. W związku z tym, gdy liczba wejściowa będzie bardzo duża, ilość prób i błędów staje się ogromna. To nie przypadek, że jest to podstawa algorytmów kryptograficznych takich jak RSA. Szyfry RSA i krzywe eliptyczne są trudne do złamania, szczególnie dlatego, że tak trudno jest rozłożyć na czynniki ogromne liczby.
Algorytm Shora łączył tradycyjne obliczenia z dwiema funkcjami kwantowymi, które bezpośrednio przyspieszają algorytm w części prób i błędów, zasadniczo wypróbowując wszystkie możliwe liczby w tym samym czasie. Demonstrację algorytmu pokazano na rysunku 3. Jedna z tych funkcji kwantowych wykonuje modułowe potęgowanie, a drugie wykonuje kwantową wersję szybkiej transformaty Fouriera (FFT). Z powodów, które pokochał tylko matematyk, gdybyśmy wprowadzili zestaw n kubitów przygotowanych tak, aby razem reprezentowały wszystkie możliwe liczby binarne do długości n, to w bramkach kwantowych różne stany w superpozycji znoszą się nawzajem - jak interferencja dwóch spójnych promieni świetlnych - i pozostaje nam pewna struktura stanów w rejestrze wyjściowym.
 Rysunek 3 – Algorytm Shora zależy od procedur kwantowych dla potęgowania modułowego i operacji FFT. (zdjęcie dzięki uprzejmości Tysona Williamsa)
Rysunek 3 – Algorytm Shora zależy od procedur kwantowych dla potęgowania modułowego i operacji FFT. (zdjęcie dzięki uprzejmości Tysona Williamsa) Procedura ta nie generuje czynnika pierwszego – jest to jedynie krok pośredni, który pozwala obliczyć możliwy czynnik pierwszy. Obliczenia te przeprowadza się poprzez pomiar kubitów — należy pamiętać, że jesteśmy w sferze możliwości, ale nie precyzji pomiaru najbardziej prawdopodobnego stanu każdego kubitu — a następnie wykonujemy wiele rutynowych obliczeń na zwykłym procesorze (CPU), aby upewnij się, że wynik jest poprawny.
Wszystko to może wydawać się beznadziejnie skomplikowane i niemożliwe. Jednak zdolność potęgowania kwantowego i kwantowej FFT do jednoczesnej pracy ze wszystkimi możliwymi potęgami liczby 2 w celu znalezienia największego czynnika pierwszego sprawia, że algorytm Shora jest szybszy niż konwencjonalne obliczenia dla dużych liczb, nawet przy użyciu raczej powolnych teoretycznych procedur kwantowych.
Algorytm Shora jest znakomitym przykładem obliczeń kwantowych, ponieważ różni się od obliczeń konwencjonalnych i jest potencjalnie niezwykle ważny. Ale nie jest sam. Amerykański Narodowy Instytut Standardów i Technologii (NIST) utrzymuje dużą bibliotekę algorytmów obliczeń kwantowych w swoim zoo Quantum Algorithms Zoo pod adresem math.nist.gov/quantum/zoo/.
Czy te algorytmy to tylko ćwiczenia matematyczne? Jest za wcześnie, żeby powiedzieć to na pewno. Jednak w praktyce badacze faktycznie stworzyli laboratoryjne kalkulatory kwantowe z kilkoma działającymi kubitami. Maszyny te pomyślnie rozłożyły na czynniki liczbę 15 (po raz pierwszy wykonano w IBM w 2001 r.), w przewidywalny sposób dając 3 i 5, a aktualny rekord świata to 21 (uzyskany przez zespół składający się z wielu instytucji w 2012 r.). Zatem w przypadku małych liczb pomysł się sprawdza. Przydatność tego podejścia do dużych liczb będzie można przetestować w przyszłości dopiero na maszynach z większą liczbą kubitów. A to przenosi problem na poziom praktyczny.
Droga do urzeczywistnienia
Aby stworzyć funkcjonalne urządzenia do obliczeń kwantowych, należy przejść szereg etapów wdrożeniowych. Musimy zbudować działające kubity – nie tylko pięć, ale tysiące. Musimy zorganizować strukturę bramek kwantowych i odpowiedników drutów - chyba że uda nam się zmusić bramki do bezpośredniego działania na stan w wejściowym rejestrze kwantowym. To wszystko złożone zadania, a harmonogram ich rozstrzygnięcia jest nieprzewidywalny.
Niestety problemy te nie są związane z nowością zagadnień, ale z prawami mechaniki kwantowej i fizyki klasycznej. Być może najważniejszym i najmniej znanym z nich jest dekoherencja. Rolą kubitu jest utrzymywanie obiektu fizycznego – takiego jak jon, pakiet fotonów lub elektron – w miejscu, dzięki czemu możemy na niego wpływać i ostatecznie zmierzyć skwantowaną wielkość, taką jak ładunek lub spin. Aby ta wielkość zachowywała się raczej kwantowo niż klasycznie, musimy być w stanie ograniczyć jej stan do superpozycji dwóch czystych stanów podstawowych, które nazwaliśmy 0 i 1.
Ale natura systemów kwantowych jest taka, że łączy je z otaczającymi je rzeczami, znacznie zwiększając liczbę możliwych stanów podstawowych. Fizycy nazywają to rozmyciem dekoherencji stanów czystych. Analogią może być spójna wiązka lasera w światłowodzie, rozproszona przez niejednorodności materiału i rozmazana z superpozycji dwóch modów w całkowicie niespójne światło. Celem utworzenia fizycznego kubitu jest zapobieganie dekoherencji tak długo, jak to możliwe.
W praktyce oznacza to, że nawet pojedynczy kubit jest skomplikowanym instrumentem laboratoryjnym, być może wykorzystującym lasery lub nadajniki radiowe o wysokiej częstotliwości, precyzyjnie kontrolowane pola elektryczne i magnetyczne, dokładne wymiary, specjalne materiały i ewentualnie chłodzenie kriogeniczne. Jego zastosowanie jest zasadniczo złożoną procedurą eksperymentalną. Nawet przy tych wszystkich wysiłkach dzisiaj „tak długo, jak to możliwe” mierzy się w dziesiątkach mikrosekund. Zatem masz bardzo mało czasu na wykonanie obliczeń kwantowych, zanim kubity stracą spójność. To znaczy zanim informacja zniknie.
Obecnie ograniczenia te uniemożliwiają stosowanie dużych rejestrów kwantowych lub obliczeń wymagających więcej niż kilku mikrosekund. Jednak obecnie trwają badania w mikroelektronice, których celem jest stworzenie znacznie większych układów kubitów i bramek kwantowych.
Jednak sama ta praca jest nieco chaotyczna, ponieważ nie jest jeszcze pewne, jakiego zjawiska fizycznego użyć do przechowywania stanów kwantowych. Istnieją projekty kubitów, które kwantyzują polaryzację fotonów, ładunek elektronów uwięzionych w kropkach kwantowych, spin netto przechłodzonych jonów w pułapce, ładunek w urządzeniu zwanym transmonem i kilka innych podejść.
Rodzaj wybranego kubitu w naturalny sposób określi implementację bramki kwantowej. Można na przykład wykorzystać interakcję impulsów radiowych z wewnętrznymi spinami cząsteczek w pułapce lub interakcję rozdzielaczy wiązki z modami fotonów w falowodach. Oczywiście istota sprawy leży głęboko w obszarze fizyki eksperymentalnej. I jak już wspomniano, realizacja kubitów czy bramek kwantowych wymaga użycia dużej liczby różnorodnego sprzętu, od logiki cyfrowej po lasery czy nadajniki radiowe, anteny, aż po chłodnice kriogeniczne.
Implementacja kubitu zależy również od sposobu pomiaru stanu kubitu. Możesz potrzebować ultraczułego fotometru lub bolometru, mostka rezystancyjnego lub innego niezwykle czułego urządzenia do pomiaru kubitów i wymuszenia stanu superpozycji do stanu podstawowego. Co więcej, proces pomiaru stanu kubitu wprowadza inny problem nieznany tradycyjnemu przetwarzaniu: uzyskanie błędnej odpowiedzi.
Wątpienie
Istnieją dwa główne typy problemów z wyodrębnieniem stanu podstawowego z kubitu. Po pierwsze, mierzysz superpozycję kwantową, a nie wielkość klasyczną. Zakładając, że kubit pozostaje spójny, otrzymasz jeden lub drugi ze stanów podstawowych, ale nie możesz z góry być pewien, który otrzymasz: możesz być pewien jedynie, że prawdopodobieństwo uzyskania określonego stanu będzie równe kwadratowi ( moduł – dodany przez tłumacza) współczynnika tego stanu w superpozycji. Jeśli zmierzysz kubit dokładnie w tym samym stanie sto razy, otrzymasz rozkład zer i jedynek zbieżny do kwadratów współczynników.
Nie wiesz więc, czy stan wyjściowy, który zmierzyłeś w jakimś badaniu, rzeczywiście ma największe prawdopodobieństwo. Po odczytaniu kwantowego rejestru wyjściowego, zmierzeniu bitów i ustawieniu ich w ten sposób na stany podstawowe, masz trzy możliwości. Możesz wątpić, czy znasz właściwą odpowiedź i iść dalej. Możesz sprawdzić za pomocą tradycyjnych obliczeń, tak jak robi to algorytm Shora, aby sprawdzić, czy liczba, o której myślałeś, jest rzeczywiście poprawnym rozwiązaniem. Możesz też powtórzyć obliczenia duża liczba razy, sekwencyjnie lub równolegle, i uwzględnia najczęściej występujący wynik. Możesz także zorganizować swoje obliczenia w taki sposób, aby wynikiem był rozkład prawdopodobieństwa podstawowych stanów, a nie konkretna liczba binarna. W tym przypadku również konieczne jest powtórzenie.
Dzieje się tak nawet w przypadku teoretycznie doskonałego komputera kwantowego. Ale faktyczna implementacja ma jeszcze jeden problem: stary, dobry, klasyczny hałas. Nawet jeśli wszystko pójdzie dobrze, nie ma dekoherencji kubitów, a obliczenia mają na celu uzyskanie odpowiedzi z bardzo dużym prawdopodobieństwem, nadal obserwujesz kubity, próbując zmierzyć bardzo, bardzo małe wielkości fizyczne. Hałas nadal istnieje. Ponownie jedynym rozwiązaniem jest albo wykrycie błędu w drodze dalszych obliczeń, albo wykonanie obliczeń tyle razy, aby zaakceptować pozostałą niepewność. Koncepcja gwarantowanej poprawnej odpowiedzi jest obca samej istocie obliczeń kwantowych.
Jeśli to wszystko nie rysuje różowego obrazu przyszłości obliczeń kwantowych, należy potraktować tę kwestię bardzo poważnie. Poszukiwania są w toku najlepszy wybór do implementacji kubitów, chociaż odpowiedź może zależeć od algorytmu. Naukowcy zajmujący się mikroelektroniką pracują nad miniaturyzacją komponentów kwantowych przy użyciu nowych materiałów i struktur, które umożliwiłyby tworzenie bardzo dużych układów kwantowych urządzeń obliczeniowych, które można byłoby produkować masowo, podobnie jak tradycyjne chipy procesorowe. Informatycy opracowują prototypowe asemblery i kompilatory, które mogą przełożyć algorytm na układ rejestrów kwantowych i bramek kwantowych w określonej technologii.
Czy warto? Oto jeden fakt. Shore obliczył, że skromny komputer hybrydowy — to znaczy komputer kwantowy i konwencjonalny — mógłby złamać potężny algorytm szyfrowania RSA szybciej, niż byłby w stanie go zaszyfrować konwencjonalny komputer. Podobne wyniki uzyskano w przypadku problemów takich jak sortowanie i rozplątywanie innych podobnych złożonych problemów matematycznych. Zatem w tej dziedzinie jest wystarczająco dużo obietnic, aby badacze byli podekscytowani. Ale miło byłoby zobaczyć to wszystko jeszcze za życia.
Dziś chciałbym rozpocząć publikowanie serii notatek na ten palący temat, na temat którego niedawno ukazała się moja nowa książka, a mianowicie wprowadzenie do zrozumienia kwantowego modelu obliczeniowego. Dziękuję mojemu dobremu przyjacielowi i współpracownikowi Aleksandrowi za możliwość zamieszczania gościnnych postów na ten temat na jego blogu.
Starałem się uczynić tę krótką notatkę możliwie najprostszą z punktu widzenia zrozumienia dla nieprzeszkolonego czytelnika, który jednak chciałby zrozumieć, czym jest przetwarzanie kwantowe. Od czytelnika wymagana jest jednak podstawowa wiedza z zakresu informatyki. Cóż, ogólne wykształcenie matematyczne też by nie pasowało :). W artykule nie ma żadnych formuł, wszystko jest wyjaśnione słowami. Jednakże wszyscy możecie zadawać mi pytania w komentarzach, a ja postaram się wyjaśnić najlepiej jak potrafię.
Co to jest przetwarzanie kwantowe?
Zacznijmy od tego, że informatyka kwantowa to temat nowy, bardzo modny, który rozwija się skokowo w kilku kierunkach (podczas gdy w naszym kraju, jak każda nauka podstawowa, pozostaje w opłakanym stanie i pozostawiony jest nielicznym naukowcom zasiadającym w ich wieże z kości słoniowej). A teraz już mówi się o pojawieniu się pierwszych komputerów kwantowych (D-Wave, ale to nie jest uniwersalny komputer kwantowy), co roku publikowane są nowe algorytmy kwantowe, powstają kwantowe języki programowania, mroczny geniusz International Business Machines w tajnych podziemnych laboratoriach wykonuje obliczenia kwantowe na dziesiątkach kubitów.
Co to jest? Obliczenia kwantowe to model obliczeniowy, który różni się od modeli Turinga i von Neumanna i oczekuje się, że będzie bardziej wydajny w przypadku niektórych zadań. Przynajmniej znaleziono problemy, dla których kwantowy model obliczeniowy daje złożoność wielomianową, podczas gdy dla klasycznego modelu obliczeniowego nie są znane algorytmy, które miałyby złożoność mniejszą niż wykładnicza (ale z drugiej strony nie zostało to jeszcze udowodnione że takie algorytmy nie istnieją).
Jak to może być? To proste. Model obliczeń kwantowych opiera się na kilku dość prostych zasadach przekształcania informacji wejściowych, które zapewniają masową równoległość procesów obliczeniowych. Innymi słowy, możesz oszacować wartość funkcji dla wszystkich jej argumentów jednocześnie (i będzie to pojedyncze wywołanie funkcji). Osiąga się to poprzez specjalne przygotowanie parametrów wejściowych i specjalny rodzaj funkcji.
Lighter Prots uczy, że wszystko to jest manipulacją składniową za pomocą symboli matematycznych, za którą w rzeczywistości nie ma żadnego znaczenia. Istnieje formalny system zawierający zasady przekształcania danych wejściowych w dane wyjściowe i system ten pozwala, poprzez spójne stosowanie tych reguł, uzyskać wynik z danych wejściowych. Wszystko to ostatecznie sprowadza się do pomnożenia macierzy i wektora. Tak tak tak. Cały model obliczeń kwantowych opiera się na jednej prostej operacji – pomnożeniu macierzy przez wektor, w wyniku czego otrzymujemy inny wektor jako wynik.
Luminarz Halikaarn natomiast uczy, że istnieje obiektywny proces fizyczny, który wykonuje określoną operację i dopiero jego istnienie przesądza o możliwości masowej równoległości obliczeń funkcji. Fakt, że postrzegamy to jako mnożenie macierzy przez wektor, jest po prostu naszym niezbyt doskonałym sposobem odzwierciedlania obiektywnej rzeczywistości w naszych umysłach.
Jesteśmy w swoim laboratorium naukowe W imieniu luminarzy Protsa i Halikaarna łączymy te dwa podejścia i mówimy, że model obliczeń kwantowych jest matematyczną abstrakcją odzwierciedlającą obiektywny proces. W szczególności liczby w wektorach i macierzach są zespolone, choć wcale nie zwiększa to mocy obliczeniowej modelu (byłoby tak samo potężne w przypadku liczb rzeczywistych), ale liczby zespolone zostały wybrane, ponieważ stwierdzono obiektywny proces fizyczny, który przeprowadza takie przekształcenia, jakie opisuje model i w których wykorzystuje się liczby zespolone. Proces ten nazywany jest jednolitą ewolucją układu kwantowego.
Model obliczeń kwantowych opiera się na koncepcji kubitu. Zasadniczo jest to to samo, co bit w klasycznej teorii informacji, ale kubit może przyjmować wiele wartości jednocześnie. Mówią, że kubit znajduje się w superpozycji swoich stanów, to znaczy wartość kubitu jest liniową kombinacją jego stanów podstawowych, a współczynniki stanów podstawowych są dokładnie liczbami zespolonymi. Stanami podstawowymi są wartości 0 i 1 znane z klasycznej teorii informacji (w informatyce kwantowej są one zwykle oznaczane |0> i |1>).
Nie jest jeszcze jasne, na czym polega ta sztuczka. I tu jest sztuczka. Superpozycję jednego kubitu zapisuje się jako A|0> + B|1>, gdzie A i B są liczbami zespolonymi, a jedynym ograniczeniem jest to, że suma kwadratów ich modułów musi zawsze wynosić 1. Co jeśli weźmiemy pod uwagę dwa kubity? Dwa bity mogą mieć 4 możliwe wartości: 00, 01, 10 i 11. Rozsądnie jest założyć, że te dwa kubity reprezentują superpozycję czterech wartości podstawowych: A|00> + B|01> + C|10> + D| 11>. I tak jest. Trzy kubity są superpozycją ośmiu podstawowych wartości. Innymi słowy, rejestr kwantowy składający się z N kubitów przechowuje jednocześnie 2N liczb zespolonych. Cóż, z matematycznego punktu widzenia jest to 2N-wymiarowy wektor w przestrzeni o wartościach zespolonych. To właśnie osiąga wykładniczą moc modelu obliczeń kwantowych.
Następna jest funkcja stosowana do danych wejściowych. Ponieważ dane wejściowe są teraz superpozycją wszystkich możliwych wartości argumentu wejściowego, funkcja musi zostać przekonwertowana, aby zaakceptować taką superpozycję i ją przetworzyć. Tutaj także wszystko jest mniej więcej proste. W modelu obliczeń kwantowych każda funkcja jest macierzą podlegającą jednemu ograniczeniu: musi być hermitowska. Oznacza to, że mnożąc tę macierz przez jej koniugat hermitowski, należy otrzymać macierz jednostkową. Macierz sprzężoną hermitowską uzyskuje się poprzez transpozycję macierzy pierwotnej i zastąpienie wszystkich jej elementów ich złożonymi koniugatami. Ograniczenie to wynika z wcześniej wspomnianego ograniczenia dotyczącego rejestru kwantowego. Faktem jest, że jeśli taką macierz pomnożymy przez wektor rejestru kwantowego, otrzymamy nowy rejestr kwantowy, którego suma kwadratów modułów współczynników o wartościach zespolonych dla stanów kwantowych jest zawsze równa do 1.
Pokazano, że dowolną funkcję można w specjalny sposób przekształcić w taką macierz. Pokazano również. że dowolną macierz hermitowską można wyrazić za pomocą iloczynu tensorowego małego zestawu macierzy bazowych reprezentujących podstawowe operacje logiczne. Wszystko tutaj jest w przybliżeniu takie samo jak w klasycznym modelu obliczeniowym. Jest to bardziej złożony temat, wykraczający poza zakres tego artykułu przeglądowego. Oznacza to, że teraz najważniejsze jest zrozumienie, że dowolną funkcję można wyrazić jako macierz odpowiednią do wykorzystania w modelu obliczeń kwantowych.
Co się potem dzieje? Tutaj mamy wektor wejściowy, który jest superpozycją różne opcje wartości parametru wejściowego funkcji. Istnieje funkcja w postaci macierzy hermitowskiej. Algorytm kwantowy polega na mnożeniu macierzy przez wektory. Rezultatem jest nowy wektor. Co to za nonsens?
Faktem jest, że w modelu obliczeń kwantowych istnieje jeszcze jedna operacja, tzw pomiar. Możemy zmierzyć wektor i uzyskać z niego określoną wartość kubitu. Oznacza to, że superpozycja zapada się w określoną wartość. Prawdopodobieństwo uzyskania tej lub innej wartości jest równe kwadratowi modułu współczynnika o wartościach zespolonych. I teraz jest jasne, dlaczego suma kwadratów powinna być równa 1, ponieważ podczas pomiaru zawsze zostanie uzyskana określona wartość, a zatem suma prawdopodobieństw ich uzyskania jest równa jedności.
Co się więc dzieje? Mając N kubitów, możesz jednocześnie przetwarzać 2N liczb zespolonych. A wektor wyjściowy będzie zawierał wyniki jednoczesnego przetwarzania wszystkich tych liczb. Na tym polega moc modelu obliczeń kwantowych. Ale możesz uzyskać tylko jedną wartość i za każdym razem może ona być inna w zależności od rozkładu prawdopodobieństwa. Jest to ograniczenie modelu obliczeń kwantowych.
Istota algorytmu kwantowego jest następująca. Tworzona jest równie prawdopodobna superpozycja wszystkich możliwych wartości parametru wejściowego. Ta superpozycja jest podawana na wejście funkcji. Ponadto na podstawie wyników jego wykonania wyciąga się wniosek na temat właściwości tej funkcji. Faktem jest, że nie możemy uzyskać wszystkich wyników, ale możemy całkowicie wyciągnąć wnioski na temat właściwości funkcji. W następnej sekcji pokażemy kilka przykładów.
W zdecydowanej większości źródeł dotyczących obliczeń kwantowych czytelnik znajdzie opisy kilku algorytmów, które tak naprawdę służą zwykle do wykazania mocy modelu obliczeniowego. Tutaj również krótko i powierzchownie przyjrzymy się takim algorytmom (dwóm z nich, które demonstrują różne podstawowe zasady obliczeń kwantowych). Cóż, dla szczegółowego zapoznania się z nimi, ponownie odsyłam do mojej nowej książki.
Algorytm Deutscha
Jest to pierwszy algorytm, który został opracowany w celu wykazania istoty i efektywności obliczeń kwantowych. Problem, który rozwiązuje ten algorytm, jest całkowicie oderwany od rzeczywistości, ale można go wykorzystać do pokazania podstawowa zasada, co stanowi podstawę modelu.
Niech więc istnieje funkcja, która otrzymuje jeden bit na wejściu i zwraca jeden bit na wyjściu. Szczerze mówiąc, mogłyby istnieć tylko 4 takie funkcje Dwie z nich są stałe, to znaczy jedna zawsze zwraca 0, a druga zawsze zwraca 1. Pozostałe dwie są zrównoważone, to znaczy zwracają 0 i 1 w równej liczbie przypadków. . Pytanie: jak w jednym wywołaniu tej funkcji określić, czy jest ona stała, czy zrównoważona?
Oczywiście nie da się tego zrobić w klasycznym modelu obliczeniowym. Należy wywołać funkcję dwukrotnie i porównać wyniki. Ale w modelu obliczeń kwantowych można to zrobić, ponieważ funkcja zostanie wywołana tylko raz. Zobaczmy…
Jak już napisano, przygotujemy równie prawdopodobną superpozycję wszystkich możliwych wartości parametru wejściowego funkcji. Ponieważ na wejściu mamy jeden kubit, jego superpozycję o równym prawdopodobieństwie przygotowujemy za pomocą jednego zastosowania bramki Hadamarda (jest to specjalna funkcja przygotowująca superpozycje o równym prawdopodobieństwie:). Następnie ponownie stosowana jest bramka Hadamarda, która działa w ten sposób, że jeśli na jej wejście zostanie podana superpozycja o równym prawdopodobieństwie, przekształca ją z powrotem w stany |0> lub |1> w zależności od fazy superpozycji o równym prawdopodobieństwie jest w. Następnie mierzy się kubit i jeśli jest równy |0>, to dana funkcja jest stała, a jeśli |1>, to jest zrównoważona.
Co się dzieje? Jak już wspomniano, podczas pomiaru nie możemy uzyskać wszystkich wartości funkcji. Możemy jednak wyciągnąć pewne wnioski na temat jego właściwości. Problem Deutscha dotyczy własności funkcji. A ta właściwość jest bardzo prosta. W końcu jak to działa? Jeśli funkcja jest stała, to dodanie modulo 2 wszystkich jej wartości wyjściowych zawsze daje 0. Jeśli funkcja jest zrównoważona, to dodanie wszystkich jej wartości wyjściowych modulo 2 zawsze daje 1. Jest to dokładnie wynik, który otrzymaliśmy jako w wyniku wykonania algorytmu Deutscha. Nie wiemy dokładnie, jaką wartość zwróciła funkcja z równie prawdopodobnej superpozycji wszystkich wartości wejściowych. Wiemy tylko, że jest to również superpozycja wyników i jeśli teraz tę superpozycję przekształcimy w specjalny sposób, wówczas wyciągniemy jednoznaczne wnioski na temat własności funkcji.
Coś w tym stylu.
Algorytm Grovera
Inny algorytm, który wykazuje zysk kwadratowy w porównaniu z klasycznym modelem obliczeniowym, rozwiązuje problem bliższy rzeczywistości. To algorytm Grovera, czyli, jak sam to nazywa Love Grover, algorytm znajdowania igły w stogu siana. Algorytm ten opiera się na innej zasadzie leżącej u podstaw obliczeń kwantowych, a mianowicie wzmocnienie.
Wspomnieliśmy już o pewnej fazie, jaką może mieć stan kwantowy w kubicie. W modelu klasycznym nie ma fazy jako takiej; jest to coś nowego w ramach obliczeń kwantowych. Fazę można rozumieć jako znak współczynnika stanu kwantowego w superpozycji. Algorytm Grovera opiera się na fakcie, że specjalnie przygotowana funkcja zmienia fazę stanu |1>.
Algorytm Grovera rozwiązuje problem odwrotny. Jeśli masz nieuporządkowany zbiór danych, w którym musisz znaleźć jeden element spełniający kryterium wyszukiwania, algorytm Grovera pomoże Ci to zrobić wydajniej niż zwykła brutalna siła. Jeżeli proste wyliczenie rozwiązuje problem w wywołaniach funkcji O(N), to algorytm Grovera skutecznie odnajduje dany element w wywołaniach funkcji O(√N).
Algorytm Grovera składa się z następujących kroków:
1. Inicjalizacja stanu początkowego. Ponownie przygotowywana jest superpozycja wszystkich wejściowych kubitów z równym prawdopodobieństwem.
2. Stosowanie iteracji Grovera. Iteracja ta polega na sekwencyjnym zastosowaniu funkcji wyszukiwania (określa ona kryterium wyszukiwania elementu) oraz specjalnej bramce dyfuzyjnej. Bramka dyfuzyjna zmienia współczynniki stanów kwantowych, obracając je wokół średniej. Powoduje to wzmocnienie, to znaczy wzrost amplitudy pożądanej wartości. Sztuczka polega na tym, że konieczne jest zastosowanie iteracji określoną liczbę razy (√2 N), w przeciwnym razie algorytm zwróci błędne wyniki.
3. Pomiar. Po zmierzeniu wejściowego rejestru kwantowego prawdopodobnie zostanie uzyskany pożądany wynik. Jeżeli zachodzi potrzeba zwiększenia wiarygodności odpowiedzi, algorytm jest uruchamiany kilkukrotnie i obliczane jest skumulowane prawdopodobieństwo prawidłowej odpowiedzi.
Ciekawostką w tym algorytmie jest to, że pozwala on rozwiązać dowolny problem (na przykład dowolną klasę NP-zupełną), zapewniając wprawdzie nie wykładniczy, ale znaczący wzrost wydajności w porównaniu z klasycznym modelem obliczeniowym. W następnym artykule pokażemy, jak można to zrobić.
Nie można już jednak powiedzieć, że naukowcy nadal siedzą w swojej wieży z kości słoniowej. Pomimo tego, że wiele algorytmów kwantowych opracowano dla niektórych dziwnych i niezrozumiałych problemów typu Mathan (na przykład wyznaczenie rzędu ideału skończonego pierścienia), opracowano już szereg algorytmów kwantowych, które rozwiązują bardzo stosowane problemy. Przede wszystkim są to zadania z zakresu kryptografii (kompromitujące różne systemy i protokoły kryptograficzne). Następnie pojawiają się typowe problemy matematyczne na wykresach i macierzach, a problemy te mają bardzo szerokie zastosowanie. Cóż, istnieje wiele algorytmów aproksymacji i emulacji, które wykorzystują komponent analogowy modelu obliczeń kwantowych.