O código genético é codificado. O que é o código genético: informações gerais
Aula 5 Código genético
Definição do conceito
O código genético é um sistema para registrar informações sobre a sequência de aminoácidos em proteínas usando a sequência de nucleotídeos no DNA.
Como o DNA não está diretamente envolvido na síntese de proteínas, o código é escrito na linguagem do RNA. O RNA contém uracil em vez de timina.
Propriedades do código genético
1. Triplicidade
Cada aminoácido é codificado por uma sequência de 3 nucleotídeos.
Definição: Um tripleto ou códon é uma sequência de três nucleotídeos que codifica um aminoácido.
O código não pode ser monopleto, pois 4 (o número de nucleotídeos diferentes no DNA) é menor que 20. O código não pode ser dublado, porque 16 (o número de combinações e permutações de 4 nucleotídeos por 2) é menor que 20. O código pode ser tripleto, porque 64 (o número de combinações e permutações de 4 a 3) é maior que 20.
2. Degeneração.
Todos os aminoácidos, com exceção da metionina e do triptofano, são codificados por mais de um tripleto:
2 AKs para 1 trio = 2.
9 AKs x 2 trigêmeos = 18.
1 AK 3 trigêmeos = 3.
5 AKs x 4 trigêmeos = 20.
3 AKs x 6 trigêmeos = 18.
Um total de 61 códigos tripletos para 20 aminoácidos.
3. A presença de sinais de pontuação intergênicos.
Definição:
Gene é um segmento de DNA que codifica uma cadeia polipeptídica ou uma molécula tPHK, rRNA ousPHK.
GenestPHK, rPHK, sPHKproteínas não codificam.
No final de cada gene que codifica um polipeptídeo, há pelo menos um dos 3 tripletos que codificam códons de terminação de RNA ou sinais de parada. No mRNA eles se parecem com isso: UAA, UAG, UGA . Eles terminam (terminam) a transmissão.
Convencionalmente, o códon também se aplica a sinais de pontuação AGO - o primeiro após a sequência líder. (Ver aula 8) Desempenha a função de uma letra maiúscula. Nesta posição, codifica a formilmetionina (em procariontes).
4. Singularidade.
Cada tripleto codifica apenas um aminoácido ou é um terminador de tradução.
A exceção é o códon AGO . Nos procariontes, na primeira posição (letra maiúscula) codifica a formilmetionina, e em qualquer outra posição codifica a metionina.
5. Compacidade ou ausência de pontuações intragênicas.
Dentro de um gene, cada nucleotídeo é parte de um códon significativo.
Em 1961, Seymour Benzer e Francis Crick provaram experimentalmente que o código é triplo e compacto.
A essência do experimento: mutação "+" - a inserção de um nucleotídeo. Mutação "-" - perda de um nucleotídeo. Uma única mutação "+" ou "-" no início de um gene corrompe o gene inteiro. Uma mutação dupla "+" ou "-" também estraga todo o gene.
Uma mutação tripla "+" ou "-" no início do gene estraga apenas parte dele. Uma mutação quádrupla "+" ou "-" novamente estraga todo o gene.
O experimento prova que o código é tripleto e não há sinais de pontuação dentro do gene. O experimento foi realizado em dois genes de fagos adjacentes e mostrou, além disso, a presença de sinais de pontuação entre os genes.
6. Versatilidade.
O código genético é o mesmo para todas as criaturas que vivem na Terra.
Em 1979 Burrell abriu ideal código mitocondrial humano.
Definição:
"Ideal" é chamado Código genético, em que a regra de degenerescência do código quasi-duplo é cumprida: se os dois primeiros nucleotídeos em dois trigêmeos coincidem e os terceiros nucleotídeos pertencem à mesma classe (ambos são purinas ou ambos são pirimidinas), então esses trigêmeos codificam o mesmo aminoácido.
Há duas exceções a essa regra no código genérico. Ambos os desvios do código ideal no universal dizem respeito aos pontos fundamentais: o início e o fim da síntese proteica:
códon | Universal o código | Códigos mitocondriais |
|||
Vertebrados | Invertebrados | Fermento | Plantas |
||
PARE | PARE |
||||
Com UA | |||||
A G A | PARE | ||||
PARE | 230 substituições não alteram a classe do aminoácido codificado. à rasgabilidade. Em 1956, Georgy Gamov propôs uma variante do código sobreposto. De acordo com o código Gamow, cada nucleotídeo, a partir do terceiro no gene, faz parte de 3 códons. Quando o código genético foi decifrado, descobriu-se que não havia sobreposição, ou seja, cada nucleotídeo faz parte de apenas um códon. Vantagens do código genético sobreposto: compacidade, menor dependência da estrutura da proteína na inserção ou deleção de um nucleotídeo. Desvantagem: alta dependência da estrutura da proteína na substituição de nucleotídeos e restrição aos vizinhos. Em 1976, o DNA do fago φX174 foi sequenciado. Possui um DNA circular de fita simples de 5375 nucleotídeos. O fago era conhecido por codificar 9 proteínas. Para 6 deles, foram identificados genes localizados um após o outro. Descobriu-se que há uma sobreposição. O gene E está completamente dentro do gene D . Seu códon de iniciação aparece como resultado de um deslocamento de um nucleotídeo na leitura. Gene J começa onde o gene termina D . Códon de iniciação do gene J sobrepõe-se ao códon de terminação do gene D devido a um deslocamento de dois nucleotídeos. O design é chamado de "mudança de quadro de leitura" por um número de nucleotídeos que não é um múltiplo de três. Até o momento, a sobreposição foi mostrada apenas para alguns fagos. Capacidade de informação do DNA Existem 6 bilhões de pessoas na Terra. Informações hereditárias sobre eles 4x10 13 páginas do livro. Estas páginas ocupariam o volume de 6 edifícios NSU. 6x10 9 espermatozoides ocupam metade de um dedal. Seu DNA ocupa menos de um quarto de dedal. | ||||
Composição química e organização estrutural da molécula de DNA.
moléculas ácidos nucleicos são cadeias muito longas, consistindo de muitas centenas e até milhões de nucleotídeos. Qualquer ácido nucleico contém apenas quatro tipos de nucleotídeos. As funções das moléculas de ácido nucleico dependem de sua estrutura, seus nucleotídeos constituintes, seu número na cadeia e a sequência do composto na molécula.
Cada nucleotídeo é composto por três componentes: uma base nitrogenada, um carboidrato e ácido fosfórico. NO composto cada nucleotídeo ADN um dos quatro tipos de bases nitrogenadas (adenina - A, timina - T, guanina - G ou citosina - C) está incluído, bem como um carbono desoxirribose e um resíduo de ácido fosfórico.
Assim, os nucleotídeos de DNA diferem apenas no tipo de base nitrogenada.
A molécula de DNA consiste em um grande número de nucleotídeos conectados em uma cadeia em uma determinada sequência. Cada tipo de molécula de DNA tem seu próprio número e sequência de nucleotídeos.
As moléculas de DNA são muito longas. Por exemplo, para escrever a sequência de nucleotídeos em moléculas de DNA de uma célula humana (46 cromossomos), seria necessário um livro de cerca de 820.000 páginas. A alternância de quatro tipos de nucleotídeos pode formar conjunto infinito variantes de moléculas de DNA. Essas características da estrutura das moléculas de DNA permitem que elas armazenem uma enorme quantidade de informações sobre todos os sinais dos organismos.
Em 1953, o biólogo americano J. Watson e o físico inglês F. Crick criaram um modelo para a estrutura da molécula de DNA. Os cientistas descobriram que cada molécula de DNA consiste em duas fitas interconectadas e torcidas em espiral. Parece uma dupla hélice. Em cada cadeia, quatro tipos de nucleotídeos se alternam em uma sequência específica.
Nucleotídeo Composição do DNAé diferente de tipos diferentes bactérias, fungos, plantas, animais. Mas não muda com a idade, depende pouco das mudanças. meio Ambiente. Os nucleotídeos são pareados, ou seja, o número de nucleotídeos de adenina em qualquer molécula de DNA é igual ao número de nucleotídeos de timidina (A-T), e o número de nucleotídeos de citosina é igual ao número de nucleotídeos de guanina (C-G). Isso se deve ao fato de que a ligação de duas cadeias entre si em uma molécula de DNA obedece a uma certa regra, a saber: a adenina de uma cadeia está sempre ligada por duas ligações de hidrogênio apenas com a timina da outra cadeia, e a guanina por três pontes de hidrogênio. ligações com citosina, ou seja, as cadeias de nucleotídeos de uma molécula de DNA são complementares, complementam-se.
Moléculas de ácido nucleico - DNA e RNA são compostos de nucleotídeos. A composição dos nucleotídeos de DNA inclui uma base nitrogenada (A, T, G, C), um carboidrato desoxirribose e um resíduo de uma molécula de ácido fosfórico. A molécula de DNA é dupla hélice, constituído por duas cadeias ligadas por pontes de hidrogénio segundo o princípio da complementaridade. A função do DNA é armazenar informações hereditárias.
Propriedades e funções do DNA.
ADNé um portador Informação genética, escrito como uma sequência de nucleotídeos usando o código genético. As moléculas de DNA estão associadas a dois propriedades de vida organismos - hereditariedade e variabilidade. Durante um processo chamado replicação do DNA, duas cópias da cadeia original são formadas, que são herdadas pelas células filhas quando se dividem, de modo que as células resultantes são geneticamente idênticas às originais.
A informação genética é realizada durante a expressão gênica nos processos de transcrição (síntese de moléculas de RNA em um molde de DNA) e tradução (síntese de proteínas em um molde de RNA).
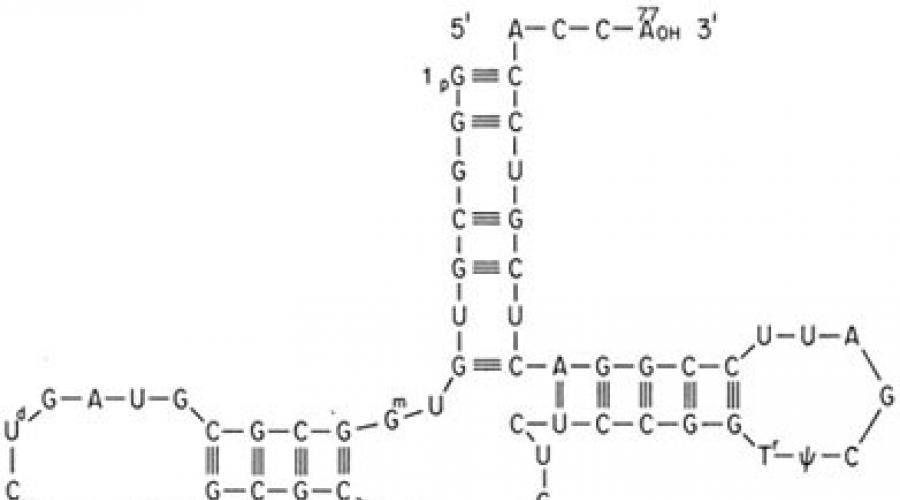
A sequência de nucleotídeos "codifica" informações sobre Vários tipos RNA: informação, ou matriz (mRNA), ribossomal (rRNA) e transporte (tRNA). Todos esses tipos de RNA são sintetizados a partir do DNA durante o processo de transcrição. Seu papel na biossíntese de proteínas (processo de tradução) é diferente. O RNA mensageiro contém informações sobre a sequência de aminoácidos em uma proteína, o RNA ribossômico serve como base para os ribossomos (complexos complexos de nucleoproteínas, cuja principal função é montar uma proteína a partir de aminoácidos individuais com base no mRNA), o RNA de transferência fornece aminoácidos ácidos para o local de montagem da proteína - para o centro ativo do ribossomo, "rastejando" ao longo do mRNA.
Código genético, suas propriedades.
Código genético- um método inerente a todos os organismos vivos para codificar a sequência de aminoácidos de proteínas usando uma sequência de nucleotídeos. PROPRIEDADES:
- Triplicidade- uma unidade significativa do código é uma combinação de três nucleotídeos (tripleto ou códon).
- Continuidade- não há sinais de pontuação entre os trigêmeos, ou seja, a informação é lida continuamente.
- não sobreposto- o mesmo nucleotídeo não pode fazer parte de dois ou mais trigêmeos ao mesmo tempo (não observado para alguns genes sobrepostos de vírus, mitocôndrias e bactérias que codificam várias proteínas de mudança de quadro).
- Sem ambiguidade (especificidade)- um certo códon corresponde a apenas um aminoácido (no entanto, o códon UGA em Euplotes crasso códigos para dois aminoácidos - cisteína e selenocisteína)
- Degeneração (redundância) Vários códons podem corresponder ao mesmo aminoácido.
- Versatilidade- o código genético funciona da mesma forma em organismos de diferentes níveis de complexidade - de vírus a humanos (métodos Engenharia genética; existem várias exceções, mostradas na tabela na seção "Variações do código genético padrão" abaixo).
- Imunidade a ruídos- mutações de substituições de nucleotídeos que não levam a uma mudança na classe do aminoácido codificado são chamadas conservador; As mutações de substituição de nucleotídeos que levam a uma mudança na classe do aminoácido codificado são chamadas radical.
5. Autorreprodução do DNA. Replicon e seu funcionamento .
O processo de auto-reprodução de moléculas de ácido nucleico, acompanhado por herança (de célula para célula) cópias exatas Informação genética; R. realizado com a participação de um conjunto de enzimas específicas (helicase<helicase>, que controla o desenrolamento da molécula ADN, ADN-polimerase<DNA polimerase> I e III, ADN-ligase<DNA ligase>), passa por um tipo semiconservativo com a formação de uma forquilha de replicação<garfo de replicação>; em uma das correntes<vertente principal> a síntese da cadeia complementar é contínua, e por outro<fio atrasado> ocorre devido à formação de fragmentos de Dkazaki<Fragmentos de Okazaki>; R. - processo de alta precisão, cuja taxa de erro não excede 10 -9; em eucariotos R. pode ocorrer em vários pontos da mesma molécula ao mesmo tempo ADN; Rapidez R. os eucariotos têm cerca de 100 e as bactérias têm cerca de 1.000 nucleotídeos por segundo.
6. Níveis de organização do genoma eucariótico .
Em organismos eucarióticos, o mecanismo de regulação da transcrição é muito mais complexo. Como resultado da clonagem e sequenciamento de genes eucarióticos, foram encontradas sequências específicas envolvidas na transcrição e tradução.
Uma célula eucariótica é caracterizada por:
1. A presença de íntrons e éxons na molécula de DNA.
2. Maturação de i-RNA - excisão de íntrons e sutura de éxons.
3. A presença de elementos reguladores que regulam a transcrição, tais como: a) promotores - 3 tipos, cada um dos quais assenta uma polimerase específica. Pol I replica genes ribossômicos, Pol II replica genes estruturais de proteínas, Pol III replica genes que codificam pequenos RNAs. Os promotores Pol I e Pol II estão a montante do sítio de iniciação da transcrição, o promotor Pol III está dentro da estrutura do gene estrutural; b) moduladores - sequências de DNA que aumentam o nível de transcrição; c) intensificadores - sequências que aumentam o nível de transcrição e atuam independentemente de sua posição em relação à parte codificadora do gene e do estado do ponto de partida da síntese de RNA; d) terminadores - sequências específicas que interrompem tanto a tradução quanto a transcrição.
Essas sequências diferem das sequências procarióticas em sua estrutura primária e localização em relação ao códon de iniciação, e a RNA polimerase bacteriana não as "reconhece". Assim, para a expressão de genes eucarióticos em células procarióticas, os genes devem estar sob o controle de elementos reguladores procarióticos. Esta circunstância deve ser levada em consideração ao construir vetores para expressão.
7. Composição química e estrutural dos cromossomos .
Químico composição cromossômica - DNA - 40%, proteínas histonas - 40%. Não-histona - 20% um pouco de RNA. Lipídios, polissacarídeos, íons metálicos.
A composição química de um cromossomo é um complexo de ácidos nucléicos com proteínas, carboidratos, lipídios e metais. A regulação da atividade gênica e sua restauração em caso de dano químico ou de radiação ocorre no cromossomo.
ESTRUTURAL????
Cromossomos- nucleoproteína elementos estruturais núcleos celulares contendo DNA, que contém a informação hereditária do organismo, são capazes de auto-reprodução, possuem individualidade estrutural e funcional e a retêm em várias gerações.
no ciclo mitótico, as seguintes características da organização estrutural dos cromossomos são observadas:
Existem formas mitóticas e interfásicas da organização estrutural dos cromossomos, passando mutuamente umas nas outras no ciclo mitótico - são transformações funcionais e fisiológicas
8. Níveis de empacotamento de material hereditário em eucariotos .
Níveis estruturais e funcionais de organização do material hereditário de eucariotos
A hereditariedade e a variabilidade fornecem:
1) herança individual (discreta) e mudanças nas características individuais;
2) reprodução em indivíduos de cada geração de todo o complexo de características morfológicas e funcionais de organismos de uma determinada espécie biológica;
3) redistribuição em espécies com reprodução sexuada no processo de reprodução de inclinações hereditárias, como resultado da qual a prole tem uma combinação de caracteres diferente da combinação nos pais. Padrões de herança e variabilidade de traços e suas combinações seguem os princípios da organização estrutural e funcional do material genético.
Existem três níveis de organização do material hereditário de organismos eucarióticos: gênico, cromossômico e genômico (nível genótipo).
estrutura elementar nível genético serve como gene. A transferência de genes de pais para filhos é necessária para o desenvolvimento de certas características nele. Embora várias formas de variabilidade biológica sejam conhecidas, apenas uma ruptura na estrutura dos genes altera o significado da informação hereditária, de acordo com a qual características e propriedades específicas são formadas. Devido à presença do nível do gene, herança individual, separada (discreta) e independente e mudanças nas características individuais são possíveis.
Os genes das células eucarióticas são distribuídos em grupos ao longo dos cromossomos. Essas são as estruturas do núcleo celular, caracterizadas pela individualidade e pela capacidade de se reproduzirem com a preservação de características estruturais individuais em várias gerações. A presença de cromossomos determina a alocação do nível cromossômico de organização do material hereditário. A colocação de genes em cromossomos afeta a herança relativa de características, torna possível influenciar a função de um gene de seu ambiente genético imediato - genes vizinhos. A organização cromossômica do material hereditário serve Condição necessaria redistribuição das inclinações hereditárias dos pais na prole durante a reprodução sexual.
Apesar da distribuição em diferentes cromossomos, todo o conjunto de genes comporta-se funcionalmente como um todo, formando sistema único, representando o nível genômico (genotípico) de organização do material hereditário. Nesse nível, há uma ampla interação e influência mútua de inclinações hereditárias, localizadas tanto em um quanto em diferentes cromossomos. O resultado é a correspondência mútua da informação genética de diferentes inclinações hereditárias e, consequentemente, o desenvolvimento de traços equilibrados em tempo, lugar e intensidade no processo de ontogênese. A atividade funcional dos genes, o modo de replicação e as mudanças mutacionais no material hereditário também dependem das características do genótipo do organismo ou da célula como um todo. Isso é evidenciado, por exemplo, pela relatividade da propriedade de dominância.
Eu - e heterocromatina.
Alguns cromossomos aparecem condensados e intensamente coloridos durante a divisão celular. Tais diferenças foram chamadas de heteropicnose. O termo " heterocromatina". Existem eucromatina - a parte principal dos cromossomos mitóticos, que sofre o ciclo usual de compactação descompactação durante a mitose, e heterocromatina- regiões de cromossomos que estão constantemente em estado compacto.
Na maioria das espécies eucarióticas, os cromossomos contêm UE- e regiões heterocromáticas, sendo esta última parte significativa do genoma. Heterocromatina localizadas nas regiões centroméricas, às vezes nas teloméricas. Regiões heterocromáticas foram encontradas nos braços eucromáticos dos cromossomos. Eles se parecem com intercalações (intercalações) de heterocromatina em eucromatina. Tal heterocromatina chamado intercalar. Compactação da cromatina. Eucromatina e heterocromatina diferem nos ciclos de compactação. Euh. passa por um ciclo completo de compactação-descompactação de interfase para interfase, hetero. mantém um estado de compacidade relativa. Coloração diferencial. Diferentes seções de heterocromatina são coradas com diferentes corantes, algumas áreas - com algumas, outras - com várias. Usando vários corantes e usando rearranjos cromossômicos que quebram regiões heterocromáticas, muitas pequenas regiões em Drosophila foram caracterizadas onde a afinidade pela cor é diferente das regiões vizinhas.
10. Características morfológicas do cromossomo metafásico .
O cromossomo metafásico consiste em duas fitas longitudinais de desoxirribonucleoproteína - cromátides, conectadas uma à outra na região da constrição primária - o centrômero. Centrômero - de uma maneira especial site organizado cromossomo que é comum a ambas as cromátides irmãs. O centrômero divide o corpo do cromossomo em dois braços. Dependendo da localização da constrição primária, existem os seguintes tipos cromossomos: braços iguais (metacêntricos), quando o centrômero está localizado no meio, e os braços são aproximadamente comprimento igual; braços desiguais (submetacêntricos), quando o centrômero está deslocado do meio do cromossomo e os braços são de comprimento desigual; em forma de bastonete (acrocêntrico), quando o centrômero é deslocado para uma extremidade do cromossomo e um braço é muito curto. Existem também cromossomos pontuais (telocêntricos), eles não têm um braço, mas não estão no cariótipo humano (conjunto cromossômico). Em alguns cromossomos, pode haver constrições secundárias que separam uma região chamada satélite do corpo do cromossomo.
CÓDIGO GENÉTICO, um sistema de registro de informações hereditárias na forma de uma sequência de bases nucleotídicas em moléculas de DNA (em alguns vírus - RNA), que determina a estrutura primária (arranjo de resíduos de aminoácidos) em moléculas de proteínas (polipeptídeos). O problema do código genético foi formulado após provar o papel genético do DNA (microbiologistas americanos O. Avery, K. McLeod, M. McCarthy, 1944) e decifrar sua estrutura (J. Watson, F. Crick, 1953), após estabelecer que os genes determinam a estrutura e as funções das enzimas (o princípio de "um gene - uma enzima" de J. Beadle e E. Tatema, 1941) e que existe uma dependência da estrutura espacial e da atividade de uma proteína em sua estrutura primária (F. Senger, 1955). A questão de como as combinações de 4 bases de ácidos nucleicos determinam a alternância de 20 resíduos de aminoácidos comuns em polipeptídeos foi levantada pela primeira vez por G. Gamow em 1954.
Com base em um experimento no qual as interações de inserções e deleções de um par de nucleotídeos foram estudadas, em um dos genes do bacteriófago T4, F. Crick e outros cientistas em 1961 determinaram propriedades gerais código genético: tripleto, ou seja, cada resíduo de aminoácido na cadeia polipeptídica corresponde a um conjunto de três bases (tripleto ou códon) no DNA do gene; a leitura de códons dentro de um gene parte de um ponto fixo, em uma direção e "sem vírgulas", ou seja, os códons não são separados por nenhum sinal entre si; degeneração, ou redundância, - o mesmo resíduo de aminoácido pode codificar vários códons (códons sinônimos). Os autores sugeriram que os códons não se sobrepõem (cada base pertence a apenas um códon). O estudo direto da capacidade de codificação de trigêmeos foi continuado usando um sistema de síntese de proteínas livre de células sob o controle de RNA mensageiro sintético (mRNA). Em 1965, o código genético foi completamente decifrado nas obras de S. Ochoa, M. Nirenberg e H. G. Korana. Desvendar o mistério do código genético foi uma das realizações notáveis da biologia no século 20.
A implementação do código genético na célula ocorre no curso de dois processos matriciais - transcrição e tradução. O mediador entre um gene e uma proteína é o mRNA, que é formado durante a transcrição em uma das fitas de DNA. Nesse caso, a sequência de bases de DNA, que carrega informações sobre a estrutura primária da proteína, é "reescrita" na forma de uma sequência de bases de mRNA. Então, durante a tradução nos ribossomos, a sequência de nucleotídeos do mRNA é lida pelo RNA de transferência (tRNA). Estes últimos possuem uma extremidade aceptora, à qual está ligado um resíduo de aminoácido, e uma extremidade adaptadora, ou anticódon tripleto, que reconhece o códon de mRNA correspondente. A interação de códon e anti-códon ocorre com base no pareamento de bases complementares: Adenina (A) - Uracila (U), Guanina (G) - Citosina (C); neste caso, a sequência de bases do mRNA é traduzida na sequência de aminoácidos da proteína sintetizada. Vários organismos usam diferentes códons-sinônimos para o mesmo aminoácido com diferentes frequências. A leitura do mRNA que codifica a cadeia polipeptídica começa (inicia) a partir do códon AUG correspondente ao aminoácido metionina. Menos comumente em procariontes, os códons de iniciação são GUG (valina), UUG (leucina), AUU (isoleucina), em eucariotos - UUG (leucina), AUA (isoleucina), ACG (treonina), CUG (leucina). Isso define o chamado quadro, ou fase, de leitura durante a tradução, ou seja, toda a sequência de nucleotídeos do mRNA é lida triplo por tripleto de tRNA até que qualquer um dos três códons terminadores, freqüentemente chamados de códons de terminação, seja encontrado no mRNA: UAA, UAG, UGA (tabela). A leitura desses trigêmeos leva à conclusão da síntese da cadeia polipeptídica.
Os códons AUG e de parada estão localizados no início e no final das regiões de mRNA que codificam polipeptídeos, respectivamente.
O código genético é quase universal. Isso significa que existem pequenas variações no significado de alguns códons em objetos diferentes, e isso diz respeito, em primeiro lugar, aos códons terminadores, que podem ser significativos; por exemplo, nas mitocôndrias de alguns eucariotos e em micoplasmas, UGA codifica o triptofano. Além disso, em alguns mRNAs de bactérias e eucariotos, UGA codifica um aminoácido incomum, selenocisteína, e UAG, em uma das arqueobactérias, codifica pirrolisina.
Há um ponto de vista segundo o qual o código genético surgiu por acaso (a hipótese do “caso congelado”). É mais provável que ele tenha evoluído. Essa suposição é apoiada pela existência de uma versão mais simples e, aparentemente, mais antiga do código, que é lida nas mitocôndrias de acordo com a regra “dois de três”, quando apenas duas das três bases do tripleto determinam o aminoácido. ácido.
Lit.: Crick F. N. a. cerca de. Natureza geral do código genético das proteínas // Natureza. 1961 Vol. 192; O código genético. N.Y., 1966; Ichas M. Código biológico. M., 1971; Inge-Vechtomov S. G. Como o código genético é lido: regras e exceções // Ciências naturais modernas. M., 2000. T. 8; Ratner V. A. Código genético como sistema // Soros Educational Journal. 2000. V. 6. Não. 3.
S. G. Inge-Vechtomov.
O código genético é um sistema de registro de informações hereditárias em moléculas de ácidos nucléicos, baseado em certa alternância de sequências de nucleotídeos em DNA ou RNA que formam códons correspondentes a aminoácidos em uma proteína.
Propriedades do código genético.
O código genético tem várias propriedades.
Triplicidade.
Degeneração ou redundância.
Sem ambiguidade.
Polaridade.
Não sobreposto.
Compacidade.
Versatilidade.
Deve-se notar que alguns autores também oferecem outras propriedades do código relacionadas a características químicas nucleotídeos incluídos no código ou com a frequência de ocorrência de aminoácidos individuais nas proteínas do corpo, etc. No entanto, essas propriedades seguem do acima, então vamos considerá-las lá.
uma. Triplicidade. O código genético é como um monte de complicado sistema organizado tem a menor unidade estrutural e a menor unidade funcional. Um trio é a menor unidade estrutural do código genético. É composto por três nucleotídeos. códon é o menor unidade funcional Código genético. Como regra, trigêmeos de mRNA são chamados de códons. No código genético, um códon desempenha várias funções. Primeiro, sua principal função é codificar um aminoácido. Segundo, um códon pode não codificar um aminoácido, mas neste caso tem uma função diferente (veja abaixo). Como pode ser visto a partir da definição, um trio é um conceito que caracteriza elementar unidade estrutural código genético (três nucleotídeos). códon caracteriza unidade semântica elementar genoma - três nucleotídeos determinam a ligação à cadeia polipeptídica de um aminoácido.
A unidade estrutural elementar foi primeiro decifrada teoricamente, e então sua existência foi confirmada experimentalmente. De fato, 20 aminoácidos não podem ser codificados por um ou dois nucleotídeos. os últimos são apenas 4. Três dos quatro nucleotídeos dão 4 3 = 64 variantes, o que mais do que cobre o número de aminoácidos presentes nos organismos vivos (ver Tabela 1).
As combinações de nucleotídeos apresentadas na Tabela 64 têm duas características. Primeiro, das 64 variantes de trigêmeos, apenas 61 são códons e codificam qualquer aminoácido, são chamados códons de sentido. Três trigêmeos não codificam
aminoácidos a são sinais de parada que marcam o fim da tradução. Existem três trigêmeos UAA, UAG, UGA, eles também são chamados de "sem sentido" (códons sem sentido). Como resultado de uma mutação, que está associada à substituição de um nucleotídeo em um tripleto por outro, um códon sem sentido pode surgir de um códon de sentido. Esse tipo de mutação é chamado mutação sem sentido. Se esse sinal de parada for formado dentro do gene (em sua parte informativa), durante a síntese de proteínas neste local, o processo será constantemente interrompido - apenas a primeira parte (antes do sinal de parada) da proteína será sintetizada. Uma pessoa com tal patologia experimentará falta de proteína e apresentará sintomas associados a essa falta. Por exemplo, esse tipo de mutação foi encontrado no gene que codifica a cadeia beta da hemoglobina. Uma cadeia de hemoglobina inativa encurtada é sintetizada, que é rapidamente destruída. Como resultado, uma molécula de hemoglobina desprovida de uma cadeia beta é formada. É claro que é improvável que tal molécula cumpra plenamente suas funções. Existe uma doença grave que se desenvolve de acordo com o tipo de anemia hemolítica (talassemia beta-zero, da palavra grega "Talas" - o Mar Mediterrâneo, onde esta doença foi descoberta).
O mecanismo de ação dos códons de terminação é diferente do mecanismo de ação dos códons de sentido. Isso decorre do fato de que para todos os códons que codificam aminoácidos, os tRNAs correspondentes foram encontrados. Nenhum tRNA foi encontrado para códons sem sentido. Portanto, o tRNA não participa do processo de interrupção da síntese de proteínas.
códonAGO (às vezes GUG em bactérias) não apenas codifica o aminoácido metionina e valina, mas também éiniciador de transmissão .
b. Degeneração ou redundância.
61 dos 64 tripletos codificam 20 aminoácidos. Esse excesso de três vezes o número de trigêmeos sobre o número de aminoácidos sugere que duas opções de codificação podem ser usadas na transferência de informações. Em primeiro lugar, nem todos os 64 códons podem estar envolvidos na codificação de 20 aminoácidos, mas apenas 20 e, em segundo lugar, os aminoácidos podem ser codificados por vários códons. Estudos mostraram que a natureza usou a última opção.
Sua preferência é clara. Se apenas 20 das 64 variantes de tripleto estivessem envolvidas na codificação de aminoácidos, então 44 tripletos (de 64) permaneceriam não codificantes, ou seja, sem sentido (códons sem sentido). Anteriormente, indicamos o quão perigoso para a vida da célula é a transformação de um tripleto de codificação como resultado de uma mutação em um códon sem sentido - isso viola significativamente trabalho normal RNA polimerase, levando ao desenvolvimento de doenças. Existem atualmente três códons sem sentido em nosso genoma, e agora imagine o que aconteceria se o número de códons sem sentido aumentasse cerca de 15 vezes. É claro que em tal situação a transição de códons normais para códons sem sentido será imensamente maior.
Um código no qual um aminoácido é codificado por vários trigêmeos é chamado de degenerado ou redundante. Quase todo aminoácido tem vários códons. Assim, o aminoácido leucina pode ser codificado por seis trigêmeos - UUA, UUG, CUU, CUC, CUA, CUG. A valina é codificada por quatro trigêmeos, a fenilalanina por dois e apenas triptofano e metionina codificado por um códon. A propriedade que está associada à gravação da mesma informação com diferentes caracteres é chamada degeneração.
O número de códons atribuídos a um aminoácido correlaciona-se bem com a frequência de ocorrência do aminoácido nas proteínas.
E isso provavelmente não é acidental. Quanto maior a frequência de ocorrência de um aminoácido em uma proteína, mais frequentemente o códon desse aminoácido está presente no genoma, maior a probabilidade de seu dano por fatores mutagênicos. Portanto, é claro que um códon mutado tem maior probabilidade de codificar o mesmo aminoácido se for altamente degenerado. A partir dessas posições, a degeneração do código genético é um mecanismo que protege o genoma humano de danos.
Deve-se notar que o termo degenerescência é usado em genética molecular em outro sentido também. Como a parte principal da informação no códon recai sobre os dois primeiros nucleotídeos, a base na terceira posição do códon acaba sendo de pouca importância. Esse fenômeno é chamado de “degeneração da terceira base”. Último recurso minimiza o efeito de mutações. Por exemplo, sabe-se que a principal função dos glóbulos vermelhos é o transporte de oxigênio dos pulmões para os tecidos e dióxido de carbono dos tecidos para os pulmões. Esta função é realizada pelo pigmento respiratório - hemoglobina, que preenche todo o citoplasma do eritrócito. Consiste em uma parte da proteína - globina, que é codificada pelo gene correspondente. Além da proteína, a hemoglobina contém heme, que contém ferro. Mutações nos genes da globina resultam em várias opções hemoglobinas. Na maioria das vezes, as mutações estão associadas a substituição de um nucleotídeo por outro e o aparecimento de um novo códon no gene, que pode codificar um novo aminoácido na cadeia polipeptídica da hemoglobina. Em um tripleto, como resultado de uma mutação, qualquer nucleotídeo pode ser substituído - o primeiro, o segundo ou o terceiro. Várias centenas de mutações são conhecidas por afetar a integridade dos genes da globina. Aproximar 400 dos quais estão associados à substituição de nucleótidos únicos no gene e à correspondente substituição de aminoácidos no polipéptido. Destes, apenas 100 substituições levam à instabilidade da hemoglobina e vários tipos de doenças de leves a muito graves. 300 (aproximadamente 64%) mutações de substituição não afetam a função da hemoglobina e não levam a patologia. Uma das razões para isso é a já mencionada “degeneração da terceira base”, quando a substituição do terceiro nucleotídeo no tripleto que codifica serina, leucina, prolina, arginina e alguns outros aminoácidos leva ao aparecimento de um códon- codificação sinônima para o mesmo aminoácido. Fenotipicamente, tal mutação não se manifestará. Em contraste, qualquer substituição do primeiro ou segundo nucleotídeo em um trigêmeo em 100% dos casos leva ao aparecimento de uma nova variante de hemoglobina. Mas mesmo neste caso, pode não haver distúrbios fenotípicos graves. A razão para isso é a substituição de um aminoácido na hemoglobina por outro semelhante ao primeiro. propriedades físicas e químicas. Por exemplo, se um aminoácido com propriedades hidrofílicas for substituído por outro aminoácido, mas com as mesmas propriedades.
A hemoglobina consiste em um grupo de ferro porfirina de heme (moléculas de oxigênio e dióxido de carbono estão ligadas a ele) e uma proteína - globina. A hemoglobina adulta (HbA) contém duas - correntes e dois -correntes. Molécula -cadeia contém 141 resíduos de aminoácidos, - corrente - 146, - e As cadeias diferem em muitos resíduos de aminoácidos. A sequência de aminoácidos de cada cadeia de globina é codificada por seu próprio gene. O gene que codifica - a cadeia está localizada no braço curto do cromossomo 16, -gene - no braço curto do cromossomo 11. Mudança na codificação do gene - a cadeia de hemoglobina do primeiro ou segundo nucleotídeo quase sempre leva ao aparecimento de novos aminoácidos na proteína, interrupção das funções da hemoglobina e consequências graves para o paciente. Por exemplo, substituir "C" em um dos trigêmeos CAU (histidina) por "U" levará ao aparecimento de um novo trio UAU que codifica outro aminoácido - tirosina. Fenotipicamente, isso se manifestará em uma doença grave .. A substituição semelhante na posição 63 A cadeia do polipeptídeo histidina em tirosina desestabilizará a hemoglobina. A doença metemoglobinemia desenvolve-se. Mudança, como resultado de mutação, de ácido glutâmico para valina na 6ª posição cadeia é a causa de uma doença grave - anemia falciforme. Não vamos continuar a lista triste. Observamos apenas que ao substituir os dois primeiros nucleotídeos, um aminoácido pode apresentar propriedades físico-químicas semelhantes ao anterior. Assim, a substituição do 2º nucleotídeo em um dos trigêmeos que codificam o ácido glutâmico (GAA) em -cadeia em "Y" leva ao aparecimento de um novo tripleto (GUA) que codifica a valina, e a substituição do primeiro nucleotídeo por "A" forma um tripleto AAA que codifica o aminoácido lisina. O ácido glutâmico e a lisina são semelhantes em propriedades físico-químicas - ambos são hidrofílicos. A valina é um aminoácido hidrofóbico. Portanto, a substituição do ácido glutâmico hidrofílico por valina hidrofóbica altera significativamente as propriedades da hemoglobina, o que acaba levando ao desenvolvimento da anemia falciforme, enquanto a substituição do ácido glutâmico hidrofílico por lisina hidrofílica altera em menor grau a função da hemoglobina - pacientes desenvolver uma forma leve de anemia. Como resultado da substituição da terceira base, o novo tripleto pode codificar os mesmos aminoácidos que o anterior. Por exemplo, se o uracil foi substituído por citosina no trio CAH e um trio CAC surgiu, praticamente nenhuma alteração fenotípica em uma pessoa será detectada. Isso é compreensível, porque Ambos os trigêmeos codificam o mesmo aminoácido, a histidina.
Em conclusão, é oportuno enfatizar que a degenerescência do código genético e a degenerescência da terceira base de uma posição biológica geral são mecanismos de defesa, que são incorporados na evolução na estrutura única de DNA e RNA.
dentro. Sem ambiguidade.
Cada trio (exceto os sem sentido) codifica apenas um aminoácido. Assim, na direção do códon - aminoácido, o código genético é inequívoco, na direção do aminoácido - códon - é ambíguo (degenerado).
inequívoco
códon aminoácido
degenerar
E neste caso, a necessidade de não ambiguidade no código genético é óbvia. Em outra variante, durante a tradução de um mesmo códon, diferentes aminoácidos seriam inseridos na cadeia protéica e, como resultado, seriam formadas proteínas com diferentes estruturas primárias e diferentes funções. O metabolismo da célula mudaria para o modo de operação "um gene - vários polipeptídeos". É claro que em tal situação a função reguladora dos genes seria completamente perdida.
g. Polaridade
A leitura de informações do DNA e do mRNA ocorre apenas em uma direção. A polaridade tem importância para definir estruturas de ordem superior (secundária, terciária, etc.). Anteriormente falamos sobre a estrutura ordem mais baixa definir estruturas de ordem superior. A estrutura terciária e as estruturas de ordem superior nas proteínas são formadas imediatamente assim que a cadeia de RNA sintetizada se afasta da molécula de DNA ou a cadeia polipeptídica se afasta do ribossomo. Enquanto a extremidade livre do RNA ou polipeptídeo adquire uma estrutura terciária, a outra extremidade da cadeia ainda continua a ser sintetizada no DNA (se o RNA for transcrito) ou ribossomo (se o polipeptídeo for transcrito).
Portanto, o processo unidirecional de leitura de informações (durante a síntese de RNA e proteína) é essencial não apenas para determinar a sequência de nucleotídeos ou aminoácidos na substância sintetizada, mas para a determinação rígida de secundários, terciários, etc. estruturas.
e. Não sobreposição.
O código pode ou não se sobrepor. Na maioria dos organismos, o código não se sobrepõe. Um código sobreposto foi encontrado em alguns fagos.
A essência de um código não sobreposto é que o nucleotídeo de um códon não pode ser o nucleotídeo de outro códon ao mesmo tempo. Se o código estivesse sobreposto, então a sequência de sete nucleotídeos (GCUGCUG) poderia codificar não dois aminoácidos (alanina-alanina) (Fig. 33, A) como no caso de um código não sobreposto, mas três (se um nucleotídeo é comum) (Fig. 33, B) ou cinco (se dois nucleotídeos são comuns) (veja Fig. 33, C). Nos dois últimos casos, uma mutação de qualquer nucleotídeo levaria a uma violação na sequência de dois, três, etc. aminoácidos.
No entanto, descobriu-se que uma mutação de um nucleotídeo sempre interrompe a inclusão de um aminoácido em um polipeptídeo. Este é um argumento significativo a favor do fato de que o código não é sobreposto.
Vamos explicar isso na Figura 34. As linhas em negrito mostram trigêmeos codificando aminoácidos no caso de código não sobreposto e sobreposto. Experimentos mostraram inequivocamente que o código genético não se sobrepõe. Sem entrar nos detalhes do experimento, notamos que, se substituirmos o terceiro nucleotídeo na sequência de nucleotídeos (veja a Fig. 34)No (marcado com um asterisco) para algum outro então:
1. Com um código não sobreposto, a proteína controlada por esta sequência teria um substituto para um (primeiro) aminoácido (marcado com asteriscos).
2. Com um código sobreposto na opção A, ocorreria uma substituição em dois (primeiro e segundo) aminoácidos (marcados com asteriscos). Na opção B, a substituição afetaria três aminoácidos (marcados com asteriscos).
No entanto, vários experimentos mostraram que quando um nucleotídeo no DNA é quebrado, a proteína sempre afeta apenas um aminoácido, o que é típico para um código não sobreposto.
ГЦУГЦУГ ГЦУГЦУГ ГЦУГЦУГ
HCC HCC HCC UHC CUG HCC CUG UGC HCC CUG
*** *** *** *** *** ***
Alanina - Alanina Ala - Cys - Lei Ala - Lei - Lei - Ala - Lei
A B C
código não sobreposto código sobreposto
Arroz. 34. Esquema explicando a presença de um código não sobreposto no genoma (explicação no texto).
A não sobreposição do código genético está associada a outra propriedade - a leitura da informação começa a partir de um determinado ponto - o sinal de iniciação. Tal sinal de iniciação no mRNA é o códon que codifica a metionina AUG.
Deve-se notar que uma pessoa ainda tem um pequeno número de genes que se desviam regra geral e sobreposição.
e. Compacidade.
Não há sinais de pontuação entre os códons. Em outras palavras, os tripletos não são separados uns dos outros, por exemplo, por um nucleotídeo sem sentido. A ausência de "pontuações" no código genético foi comprovada em experimentos.
e. Versatilidade.
O código é o mesmo para todos os organismos que vivem na Terra. A prova direta da universalidade do código genético foi obtida comparando sequências de DNA com sequências de proteínas correspondentes. Descobriu-se que os mesmos conjuntos de valores de código são usados em todos os genomas bacterianos e eucarióticos. Há exceções, mas não muitas.
As primeiras exceções à universalidade do código genético foram encontradas nas mitocôndrias de algumas espécies animais. Isso dizia respeito ao códon terminador UGA, que lê o mesmo que o códon UGG que codifica o aminoácido triptofano. Outros desvios mais raros da universalidade também foram encontrados.
Sistema de código de DNA.
O código genético do DNA consiste em 64 tripletos de nucleotídeos. Esses trigêmeos são chamados de códons. Cada códon codifica um dos 20 aminoácidos usados na síntese de proteínas. Isso dá alguma redundância no código: a maioria dos aminoácidos é codificada por mais de um códon.
Um códon desempenha duas funções inter-relacionadas: sinaliza o início da tradução e codifica a incorporação do aminoácido metionina (Met) na cadeia polipeptídica em crescimento. O sistema de código de DNA é projetado para que o código genético possa ser expresso como códons de RNA ou como códons de DNA. Os códons de RNA ocorrem no RNA (mRNA) e esses códons são capazes de ler informações durante a síntese de polipeptídeos (um processo chamado tradução). Mas cada molécula de mRNA adquire uma sequência de nucleotídeos na transcrição do gene correspondente.
Todos, exceto dois aminoácidos (Met e Trp) podem ser codificados por 2 a 6 códons diferentes. No entanto, o genoma da maioria dos organismos mostra que certos códons são favorecidos em relação a outros. Em humanos, por exemplo, a alanina é codificada pelo GCC quatro vezes mais frequentemente do que no GCG. Isso provavelmente indica uma maior eficiência de tradução do aparelho de tradução (por exemplo, o ribossomo) para alguns códons.

O código genético é quase universal. Os mesmos códons são atribuídos ao mesmo trecho de aminoácidos e os mesmos sinais de início e término são predominantemente os mesmos em animais, plantas e microorganismos. No entanto, algumas exceções foram encontradas. A maioria deles envolve a atribuição de um ou dois dos três códons de parada a um aminoácido.
Gene- uma unidade estrutural e funcional de hereditariedade que controla o desenvolvimento de uma determinada característica ou propriedade. Os pais transmitem um conjunto de genes para seus descendentes durante a reprodução. Uma grande contribuição para o estudo do gene foi feita por cientistas russos: Simashkevich E.A., Gavrilova Yu.A., Bogomazova O.V. (2011)
Atualmente, em biologia molecular, foi estabelecido que genes são seções de DNA que carregam qualquer informação integral - sobre a estrutura de uma molécula de proteína ou de uma molécula de RNA. Essas e outras moléculas funcionais determinam o desenvolvimento, crescimento e funcionamento do corpo.
Ao mesmo tempo, cada gene é caracterizado por uma série de sequências de DNA reguladoras específicas, como promotores, que estão diretamente envolvidos na regulação da expressão do gene. As sequências reguladoras podem estar localizadas na vizinhança imediata do quadro de leitura aberta que codifica a proteína, ou no início da sequência de RNA, como é o caso dos promotores (os chamados cis elementos reguladores cis), e a uma distância de muitos milhões de pares de bases (nucleotídeos), como no caso de intensificadores, isolantes e supressores (às vezes classificados como trans-elementos regulatórios elementos transregulatórios). Assim, o conceito de gene não se limita à região codificadora do DNA, mas é um conceito mais amplo que inclui sequências regulatórias.
Originalmente o termo gene apareceu como uma unidade teórica para a transmissão de informações hereditárias discretas. A história da biologia lembra disputas sobre quais moléculas podem ser portadoras de informações hereditárias. A maioria dos pesquisadores acreditava que apenas as proteínas podem ser tais carreadores, já que sua estrutura (20 aminoácidos) permite criar mais opções do que a estrutura do DNA, que é composta de apenas quatro tipos nucleotídeos. Mais tarde foi provado experimentalmente que é o DNA que inclui informações hereditárias que tem sido expresso como o dogma central da biologia molecular.
Os genes podem sofrer mutações - mudanças aleatórias ou propositais na sequência de nucleotídeos na cadeia de DNA. As mutações podem levar a uma mudança na sequência e, portanto, uma mudança características biológicas proteína ou RNA, que, por sua vez, pode resultar em um funcionamento alterado ou anormal geral ou local do corpo. Tais mutações em alguns casos são patogênicas, já que seu resultado é uma doença, ou letais em nível embrionário. No entanto, nem todas as alterações na sequência nucleotídica levam a uma alteração na estrutura da proteína (devido ao efeito da degenerescência do código genético) ou a uma alteração significativa na sequência e não são patogénicas. Em particular, o genoma humano é caracterizado por polimorfismos de nucleotídeo único e variações no número de cópias. variações de número de cópias), como deleções e duplicações, que compõem cerca de 1% de toda a sequência nucleotídica humana. Os polimorfismos de nucleotídeo único, em particular, definem diferentes alelos do mesmo gene.
Os monômeros que compõem cada fita de DNA são complexos compostos orgânicos, incluindo bases nitrogenadas: adenina (A) ou timina (T) ou citosina (C) ou guanina (G), um açúcar-pentose-desoxirribose de cinco átomos, após o qual o próprio DNA foi nomeado, bem como um resíduo de ácido fosfórico. Esses compostos são chamados de nucleotídeos.
Propriedades do gene
- discrição - imiscibilidade de genes;
- estabilidade - a capacidade de manter uma estrutura;
- labilidade - a capacidade de mutar repetidamente;
- alelismo múltiplo - muitos genes existem em uma população em uma variedade de formas moleculares;
- alelismo - no genótipo de organismos diplóides, apenas duas formas do gene;
- especificidade - cada gene codifica sua própria característica;
- pleiotropia - efeito múltiplo de um gene;
- expressividade - o grau de expressão de um gene em uma característica;
- penetrância - a frequência de manifestação de um gene no fenótipo;
- amplificação - um aumento no número de cópias de um gene.
Classificação
- Os genes estruturais são componentes únicos do genoma, representando uma única sequência que codifica uma proteína específica ou alguns tipos de RNA. (Veja também o artigo genes doméstico).
- Genes funcionais - regulam o trabalho dos genes estruturais.
Código genético- um método inerente a todos os organismos vivos para codificar a sequência de aminoácidos de proteínas usando uma sequência de nucleotídeos.
Quatro nucleotídeos são usados no DNA - adenina (A), guanina (G), citosina (C), timina (T), que na literatura de língua russa são denotados pelas letras A, G, C e T. Essas letras compõem o alfabeto do código genético. No RNA, os mesmos nucleotídeos são usados, com exceção da timina, que é substituída por um nucleotídeo semelhante - uracil, indicado pela letra U (U na literatura em russo). Nas moléculas de DNA e RNA, os nucleotídeos se alinham em cadeias e, assim, são obtidas sequências de letras genéticas.
Código genético
Existem 20 aminoácidos diferentes usados na natureza para construir proteínas. Cada proteína é uma cadeia ou várias cadeias de aminoácidos em uma sequência estritamente definida. Essa sequência determina a estrutura da proteína e, portanto, toda a sua propriedades biológicas. O conjunto de aminoácidos também é universal para quase todos os organismos vivos.
A implementação da informação genética em células vivas (ou seja, a síntese de uma proteína codificada por um gene) é realizada por meio de dois processos matriciais: transcrição (ou seja, a síntese de mRNA em um molde de DNA) e tradução do código genético em uma sequência de aminoácidos (síntese de uma cadeia polipeptídica no mRNA). Três nucleotídeos consecutivos são suficientes para codificar 20 aminoácidos, assim como o sinal de parada, que significa o fim da sequência da proteína. Um conjunto de três nucleotídeos é chamado de tripleto. Abreviaturas aceitas correspondentes a aminoácidos e códons são mostrados na figura.
Propriedades
- Triplicidade- uma unidade significativa do código é uma combinação de três nucleotídeos (tripleto ou códon).
- Continuidade- não há sinais de pontuação entre os trigêmeos, ou seja, a informação é lida continuamente.
- não sobreposto- o mesmo nucleotídeo não pode fazer parte de dois ou mais trigêmeos ao mesmo tempo (não observado para alguns genes sobrepostos de vírus, mitocôndrias e bactérias que codificam várias proteínas de mudança de quadro).
- Sem ambiguidade (especificidade)- um certo códon corresponde a apenas um aminoácido (no entanto, o códon UGA em Euplotes crasso códigos para dois aminoácidos - cisteína e selenocisteína)
- Degeneração (redundância) Vários códons podem corresponder ao mesmo aminoácido.
- Versatilidade- o código genético funciona da mesma maneira em organismos de diferentes níveis de complexidade - de vírus a humanos (os métodos de engenharia genética são baseados nisso; há várias exceções, mostradas na tabela em "Variações do código genético padrão " seção abaixo).
- Imunidade a ruídos- mutações de substituições de nucleotídeos que não levam a uma mudança na classe do aminoácido codificado são chamadas conservador; As mutações de substituição de nucleotídeos que levam a uma mudança na classe do aminoácido codificado são chamadas radical.
Biossíntese de proteínas e suas etapas
Biossíntese de proteínas- um processo complexo de vários estágios de síntese de uma cadeia polipeptídica a partir de resíduos de aminoácidos, ocorrendo nos ribossomos de células de organismos vivos com a participação de moléculas de mRNA e tRNA.
A biossíntese de proteínas pode ser dividida em etapas de transcrição, processamento e tradução. Durante a transcrição, a informação genética criptografada em moléculas de DNA é lida e essa informação é gravada em moléculas de mRNA. Durante uma série de estágios sucessivos de processamento, alguns fragmentos desnecessários em estágios subsequentes são removidos do mRNA e as sequências de nucleotídeos são editadas. Depois que o código é transportado do núcleo para os ribossomos, a síntese real das moléculas de proteína ocorre pela ligação de resíduos de aminoácidos individuais à cadeia polipeptídica em crescimento.
Entre a transcrição e a tradução, a molécula de mRNA sofre uma série de mudanças sucessivas que garantem a maturação de um molde funcional para a síntese da cadeia polipeptídica. Uma tampa é anexada à extremidade 5' e uma cauda poli-A é anexada à extremidade 3', o que aumenta a vida útil do mRNA. Com o advento do processamento em uma célula eucariótica, tornou-se possível combinar éxons gênicos para obter uma maior variedade de proteínas codificadas por uma única sequência de nucleotídeos de DNA - splicing alternativo.
A tradução consiste na síntese de uma cadeia polipeptídica de acordo com a informação codificada no RNA mensageiro. A sequência de aminoácidos é organizada usando transporte RNA (tRNA), que formam complexos com aminoácidos - aminoacil-tRNA. Cada aminoácido tem seu próprio tRNA, que possui um anticódon correspondente que “corresponde” ao códon do mRNA. Durante a tradução, o ribossomo se move ao longo do mRNA, à medida que a cadeia polipeptídica se acumula. A energia para a síntese de proteínas é fornecida pelo ATP.
A molécula de proteína acabada é então clivada do ribossomo e transportada para Lugar certo células. Algumas proteínas requerem modificação pós-traducional adicional para atingir seu estado ativo.