Mga posibilidad ng paggamit ng machine translation sa trabaho ng isang translator sa propesyonal na larangan. Paksa: Pagsasalin sa makina. Sistema ng pagsasalin ng makina ng PROMT
Basahin din
Lektura Blg. 8 Paksa: Ang layunin ng mga sistema ng pagsasalin ng makina.
Layunin ng pagsasalin ng makina
Ang machine translation (MT), o awtomatikong pagsasalin (AT), ay isang masinsinang umuunlad na lugar siyentipikong pananaliksik, mga eksperimentong pag-unlad at gumagana nang mga sistema (SMP), kung saan ang isang computer ay kasangkot sa proseso ng pagsasalin mula sa isang natural na wika (NL) patungo sa isa pa. Ang SMT ay nagbukas ng mabilis at sistematikong pag-access sa impormasyon sa isang wikang banyaga, nagbibigay ng kahusayan at pagkakapareho sa pagsasalin ng mga malalaking stream ng mga teksto, pangunahin ang siyentipiko at teknikal. Ang mga SMP na tumatakbo sa isang pang-industriya na antas ay umaasa sa malalaking terminolohiyang database at karaniwang nangangailangan ng paglahok ng isang tao bilang isang pre-, inter- o post-editor. Ang mga modernong SMP, lalo na ang mga nakabatay sa mga base ng kaalaman sa isang partikular na lugar ng paksa, ay inuri bilang mga sistema artificial intelligence(AI).
Ang mga pangunahing lugar ng paggamit ng MC
1. Sa mga serbisyo ng impormasyon ng sangay sa pagkakaroon ng isang malaking hanay o isang patuloy na stream ng mga mapagkukunan ng wikang banyaga. Kung ang mga SMP ay ginagamit upang maglabas ng impormasyon sa pagbibigay ng senyas, hindi kinakailangan ang post-editing.
2. Sa malaki mga internasyonal na organisasyon pagharap sa isang multilinggwal na polythematic na hanay ng mga dokumento. Ito ang mga kondisyon sa pagtatrabaho sa Commission of the European Communities sa Brussels, kung saan ang lahat ng dokumentasyon ay dapat lumabas nang sabay-sabay sa siyam na wikang gumagana. Dahil mataas ang mga kinakailangan sa pagsasalin dito, ang MT ay nangangailangan ng post-editing.
3. Sa mga serbisyo ng pagsasalin teknikal na dokumentasyon kasamang mga produktong iniluluwas. Hindi makayanan ng mga tagasalin ang malawak na dokumentasyon sa loob ng kinakailangang takdang panahon (halimbawa, ang mga detalye para sa sasakyang panghimpapawid at iba pang kumplikadong bagay ay maaaring tumagal ng hanggang 10,000 o higit pang mga pahina). Ang istraktura at wika ng teknikal na dokumentasyon ay medyo pamantayan, na nagpapadali sa MT at kahit na ginagawa itong mas kanais-nais kaysa sa manu-manong pagsasalin, dahil ginagarantiyahan nito ang isang pare-parehong istilo.
ang buong array. Dahil dapat kumpleto at tumpak ang pagsasalin ng mga pagtutukoy, kailangang ma-post-edit ang mga produkto ng MT.
4. Para sa sabay-sabay o halos sabay-sabay na pagsasalin ng ilang patuloy na daloy ng mga mensahe ng parehong uri. Ganito ang daloy ng mga ulat ng panahon sa Canada, na dapat lumabas nang sabay-sabay sa Ingles at Pranses.
Bilang karagdagan sa praktikal na pangangailangan ng mundo ng negosyo para sa SMP, mayroon ding mga pang-agham na insentibo para sa pagpapaunlad ng SMP: ang mga matatag na eksperimentong sistema ng SMP ay pang-eksperimentong larangan upang subukan ang iba't ibang aspeto ng pangkalahatang teorya ng pag-unawa, komunikasyon sa pagsasalita, pagbabago ng impormasyon, gayundin upang lumikha ng bago, mas epektibong mga modelo ng MT mismo.
Mula sa punto ng view ng sukat at antas ng pag-unlad, ang NSR ay maaaring nahahati sa tatlong pangunahing klase: pang-industriya, pagbuo at pang-eksperimentong.
Suporta sa wika ng mga sistema ng pagsasalin ng makina
Ang proseso ng MT ay isang pagkakasunud-sunod ng mga pagbabagong inilapat sa input text at ginagawa itong isang teksto sa output na wika, na dapat ay lubos na muling likhain ang kahulugan at, bilang panuntunan, ang istraktura ng pinagmulang teksto, ngunit sa pamamagitan ng output na wika. . Kasama sa suportang pangwika ng SMP ang buong complex ng wastong linguistic, metalinguistic at tinatawag na "extralinguistic" na kaalaman na ginagamit sa naturang pagbabago.
Sa classical na SMP, na nagsasagawa ng hindi direktang pagsasalin ng mga indibidwal na pangungusap (phrase-by-phrase translation), ang bawat pangungusap ay dumadaan sa pagkakasunud-sunod ng mga pagbabagong binubuo ng tatlong bahagi (yugto): pagsusuri -> paglilipat (interlingual na operasyon) -> synthesis. Sa turn, ang bawat isa sa mga yugtong ito ay sapat na kumplikadong sistema mga intermediate na pagbabago.
Ang layunin ng yugto ng pagsusuri ay bumuo ng isang istrukturang paglalarawan (intermediate na representasyon, panloob na representasyon) ng input na pangungusap, | Ang gawain ng yugto ng paglilipat (aktwal na pagsasalin) ay upang baguhin ang istruktura ng input na pangungusap sa panloob na istruktura ng output na pangungusap. Kasama rin sa yugtong ito ang pagpapalit ng mga lexeme ng input na wika sa mga katumbas ng pagsasalin nito (mga lexical interlanguage transformations). Ang layunin ng yugto ng synthesis ay bumuo ng tamang pangungusap sa output na wika batay sa istrukturang nakuha bilang resulta ng pagsusuri.
Ang suportang pangwika ng karaniwang modernong NSR ay kinabibilangan ng:
1) mga diksyunaryo;
2) gramatika;
3) pormal na mga intermediate na representasyon ng mga yunit ng pagsusuri para sa iba't ibang yugto mga pagbabagong-anyo.
Bilang karagdagan sa mga karaniwan, ang ilang hindi karaniwang mga bahagi ay maaari ding naroroon sa mga indibidwal na SMP. Kaya, ang kaalaman ng eksperto tungkol sa software ay maaaring tukuyin gamit ang mga espesyal na konseptwal na network, at hindi sa anyo ng mga diksyunaryo at grammar.
Ang mga mekanismo (algorithms, procedures) para sa pagpapatakbo gamit ang mga kasalukuyang diksyunaryo, grammar at structural representation ay tinutukoy bilang mathematical at algorithmic na suporta ng SMP.
Isa sa kinakailangang mga kinakailangan sa modernong SMP-high modularity. Mula sa isang makabuluhang pananaw sa linggwistika, nangangahulugan ito na ang pagsusuri at ang mga prosesong sumusunod dito ay binuo na isinasaalang-alang ang teorya ng mga antas ng linggwistika. Sa pagsasagawa ng paglikha ng isang SMP, ang mga sumusunod na antas ng pagsusuri ay nakikilala:
Pre-syntactic analysis (kabilang dito ang morphological analysis - MorfAn, pagsusuri ng mga parirala, hindi kilalang mga elemento ng teksto, atbp.);
Syntactic analysis SinAn (bumubuo ng syntactic na representasyon ng isang pangungusap, o SinP); sa loob ng mga limitasyon nito, maaaring makilala ang isang bilang ng mga sublevel, na nagbibigay ng pagsusuri ng iba't ibang uri ng syntactic unit;
Semantic analysis SemAn, o logical-semantic analysis (bumubuo ng argument-predicate structure ng mga pahayag o ibang uri ng semantic
presentasyon ng mga pangungusap at teksto);
Pagsusuri ng konsepto (pagsusuri sa mga tuntunin ng mga istrukturang pangkonsepto na nagpapakita ng mga semantika ng software). Ang antas ng pagsusuri na ito ay ginagamit sa mga SMP na nagta-target ng napakalimitadong software. Sa katunayan, ang konseptong istruktura ay isang projection ng software schema papunta sa linguistic structures, madalas hindi kahit na semantic, ngunit syntactic. Para lamang sa napakakitid na software at limitadong klase ng mga teksto ang istrukturang konseptwal ay tumutugma sa semantiko; sa pangkalahatang kaso, hindi dapat magkaroon ng kumpletong tugma, dahil ang teksto ay mas detalyado kaysa sa alinman
mga konseptwal na diagram.
Ang synthesis ay theoretically dumadaan sa parehong mga antas ng pagsusuri, ngunit sa kabaligtaran ng direksyon. Sa mga gumaganang sistema, ang landas lamang mula sa SynP hanggang sa word chain ng output na pangungusap ang karaniwang ipinapatupad.
Ang linguistic na pagkakaiba sa pagitan ng iba't ibang antas ay maaari ding maipakita sa pagkakaiba sa pagitan ng mga pormal na paraan na ginagamit sa kaukulang mga paglalarawan (ang hanay ng mga paraan na ito ay tinukoy para sa bawat antas nang hiwalay). Sa pagsasagawa, ang linguistic na paraan ng MorphAn ay madalas na tinutukoy nang hiwalay at ang mga paraan ng SinAn at SemAn ay pinagsama. Ngunit ang pagkakaiba-iba ng mga antas ay maaari lamang manatiling makabuluhan kung sila ay gagamit ng isang pormalismo sa kanilang mga paglalarawan na angkop para sa paglalahad ng impormasyon sa lahat ng mga natatanging antas.
Mula sa teknikal na pananaw, ang modularity ng suportang pangwika ay nangangahulugan ng paghihiwalay ng istrukturang representasyon ng mga parirala at teksto (bilang kasalukuyang, pansamantalang kaalaman tungkol sa teksto) mula sa "permanenteng" kaalaman tungkol sa wika, gayundin ang kaalaman sa wika mula sa kaalaman sa software; paghihiwalay ng mga diksyunaryo mula sa grammar, grammar mula sa mga algorithm para sa kanilang pagproseso, mga algorithm mula sa mga programa. Ang mga tiyak na ratio ng iba't ibang mga module ng system (mga diksyunaryo ng grammar, grammar - algorithm, algorithm - mga programa, deklaratibo - kaalaman sa pamamaraan, atbp.), kabilang ang pamamahagi ng data ng linguistic ayon sa mga antas, ay ang pangunahing bagay na tumutukoy sa mga detalye ng SMP.
Mga diksyunaryo. Karaniwang monolingual ang mga diksyunaryo ng pagsusuri. Dapat maglaman ang mga ito ng lahat ng impormasyong kinakailangan upang maisama ang isang ibinigay na lexical unit (LE) sa representasyong istruktura. Madalas nilang pinaghihiwalay ang mga diksyunaryo ng mga base (na may morphological at syntactic na impormasyon: bahagi ng pananalita, uri ng inflection, subclass na nagpapakilala sa syntactic na pag-uugali ng LU, atbp.) at mga diksyunaryo ng mga kahulugan ng salita na naglalaman ng semantic at conceptual na impormasyon: semantic class LU, semantic hopes ( valencies), kundisyon ang kanilang pagpapatupad sa isang parirala, atbp.
Sa maraming sistema, pinaghihiwalay ang mga diksyunaryo ng karaniwan at terminolohikal na bokabularyo. Ang ganitong dibisyon ay ginagawang posible, kapag lumipat sa mga teksto ng ibang paksa, na limitado lamang sa pamamagitan ng pagpapalit ng mga terminolohikal na diksyunaryo. Ang mga diksyunaryo ng mga kumplikadong LU (turnovers, constructions) ay karaniwang bumubuo ng isang hiwalay na hanay, ang impormasyon ng diksyunaryo sa mga ito ay nagpapahiwatig kung paano "nakolekta" ang naturang yunit sa panahon ng pagsusuri. Ang bahagi ng impormasyon sa bokabularyo ay maaaring tukuyin sa paraan ng pamamaraan, halimbawa, ang mga polysemantic na salita ay maaaring iugnay sa mga algorithm para sa paglutas ng kaukulang uri ng kalabuan. Ang mga bagong uri ng organisasyon ng impormasyon sa bokabularyo para sa mga layunin ng MT ay inaalok ng tinatawag na "lexical knowledge bases". Ang pagkakaroon ng magkakaibang impormasyon tungkol sa salita (tinatawag na lexical na uniberso ng salita) ay nagdadala ng gayong diksyunaryo na mas malapit sa isang encyclopedia kaysa sa mga tradisyonal na linguistic na mga diksyunaryo.
Mga gramatika at algorithm. Tinutukoy ng gramatika at bokabularyo ang modelo ng linggwistika, na bumubuo sa karamihan ng data ng linggwistika. Ang mga algorithm para sa kanilang pagpoproseso, ibig sabihin, mga ugnayan sa mga unit ng teksto, ay tinutukoy bilang ang mathematical at algorithmic na suporta ng system.
Ang paghihiwalay ng mga grammar at algorithm ay mahalaga sa praktikal na kahulugan dahil pinapayagan ka nitong baguhin ang mga panuntunan sa grammar nang hindi binabago ang mga algorithm (at, nang naaayon, mga programa) na gumagana sa mga grammar. Ngunit ang gayong paghihiwalay ay hindi laging posible. Kaya, para sa isang sistemang may procedural specification ng grammar, at higit pa sa isang procedural na representasyon ng impormasyon sa diksyunaryo, ang naturang dibisyon ay hindi nauugnay. Ang mga algorithm sa paggawa ng desisyon sa kaso ng hindi sapat (incompleteness of input data) o redundant (analysis variant) na impormasyon ay mas empirical, ang kanilang pagbabalangkas ay nangangailangan ng linguistic intuition. Ang pagtatakda ng isang karaniwang control algorithm na kumokontrol sa pagkakasunud-sunod ng pagtawag sa iba't ibang grammar (kung may ilan sa mga ito sa isang system) ay nangangailangan din ng linguistic na pagbibigay-katwiran. Gayunpaman, ang kasalukuyang kalakaran ay ang paghiwalayin ang mga gramatika mula sa mga algorithm upang ang lahat ng makabuluhang impormasyon sa wika ay maibigay sa static na anyo ng mga grammar, at upang gawing abstract ang mga algorithm na maaari silang mag-invoke at magproseso ng iba't ibang mga modelo ng linguistic.
Ang paghihiwalay ng mga grammar at algorithm ay pinakamalinaw na nakikita sa mga system na gumagana sa context-free grammars (CSGs), kung saan ang modelo ng wika ay isang grammar na may limitadong bilang ng mga estado, at ang algorithm ay dapat magbigay ng isang arbitraryong kinuhang pangungusap isang puno ng kanyang derivation ayon sa mga tuntunin ng gramatika, at kung mayroong ilang mga naturang derivasyon, ilista ang mga ito. Ang ganitong algorithm, na isang pormal (sa matematikal na kahulugan) na sistema, ay tinatawag na isang analyzer. Ang paglalarawan ng gramatika ay nagsisilbi para sa analyzer, pagkakaroon ng universality, ang parehong input bilang nasuri na pangungusap. Ang mga parser ay binuo para sa mga klase ng grammar, bagama't ang pagsasaalang-alang sa mga partikular na feature ng grammar ay maaaring magpapataas ng kahusayan ng parser.
Ang mga gramatika ng antas ng syntactic ay ang pinaka-binuo na bahagi kapwa mula sa punto ng view ng linggwistika at mula sa punto ng view ng kanilang probisyon na may mga pormalismo.
Mga pangunahing uri ng grammar at algorithm na nagpapatupad ng mga ito:
Inaayos ng chain grammar ang pagkakasunud-sunod ng mga elemento, ibig sabihin, mga linear na istruktura ng pangungusap, na tumutukoy sa mga ito sa mga tuntunin ng mga klase ng gramatika ng mga salita (artikulo + pangngalan + pang-ukol) o sa mga tuntunin ng mga functional na elemento (paksa + panaguri);
Ang gramatika ng mga nasasakupan (o ang gramatika ng mga direktang nasasakupan - NSG) ay kumukuha ng linguistic na impormasyon tungkol sa pagpapangkat ng mga elemento ng gramatika, halimbawa, isang pariralang pangngalan (binubuo ng isang pangngalan, isang artikulo,
pang-uri at iba pang mga modifier), pangkat ng pang-ukol (binubuo ng pang-ukol at pariralang pangngalan), atbp. hanggang sa antas ng pangungusap. Ang grammar ay binuo bilang isang hanay ng mga tuntunin sa pagpapalit, o isang calculus ng mga produksyon ng anyong A-»B...C. NSG
ay mga gramatika ng isang generative na uri at maaaring magamit kapwa sa pagsusuri at sa synthesis: ang mga pangungusap sa wika ay nabuo sa pamamagitan ng paulit-ulit na paggamit ng mga naturang tuntunin;
Tinutukoy ng dependency grammar (GZ) ang hierarchy ng mga relasyon sa pagitan ng mga elemento ng isang pangungusap (tinutukoy ng pangunahing salita ang anyo ng mga dependent). Ang analyzer sa GZ ay batay sa pagkakakilanlan ng mga masters at kanilang mga dependent (servants). Ang pangunahing bagay sa pangungusap ay ang pandiwa sa personal na anyo, dahil tinutukoy nito ang bilang at likas na katangian ng mga dependent na pangngalan. Ang diskarte sa pagsusuri sa GC ay top-down: ang mga master ay nakilala muna, pagkatapos ay ang mga tagapaglingkod, o bottom-up: ang mga master ay nakikilala sa pamamagitan ng proseso ng pagpapalit;
Ang Bar-Hillel categorical grammar ay isang bersyon ng grammar ng mga nasasakupan, mayroon lamang itong dalawang kategorya - mga pangungusap S at pangalan n. Ang natitira ay tinukoy sa mga tuntunin ng kakayahang isama sa mga pangunahing ito sa istruktura ng NN. Kaya, ang pandiwang pandiwa ay tinukoy bilang n\S, dahil ito ay pinagsama sa pangalan at sa kaliwa nito, na bumubuo ng isang S pangungusap.
Mayroong maraming mga paraan upang isaalang-alang ang mga kondisyon sa konteksto: mga gramatika ng metamorphosis at ang kanilang mga variant. Ang lahat ng mga ito ay mga extension ng CF-rules. Sa mga pangkalahatang termino, nangangahulugan ito na ang mga panuntunan sa produksyon ay muling isinulat tulad ng sumusunod: A [a]-> B[b], ..., C [c], kung saan ang mga kundisyon, pagsubok, tagubilin, atbp., na nagpapalawak sa orihinal na mahigpit na mga panuntunan at pagbibigay ng flexibility at kahusayan ng gramatika.
Sa grammar ng mga pangkalahatang bahagi-TCS, ipinakilala ang mga meta-rules, na isang generalization ng mga regularidad ng mga patakaran ng CS1.
Ang mga grammar ng extended transition networks-CPN ay nagbibigay ng mga pagsubok at kundisyon para sa mga arc, pati na rin ang mga tagubilin na dapat isagawa kung ang pagsusuri ay sumasabay sa arc na ito. Sa iba't ibang mga pagbabago ng CPN, ang mga timbang ay maaaring italaga sa mga arko, at pagkatapos ay maaaring piliin ng analyzer ang landas na may pinakamataas na timbang. Maaaring hatiin ang mga kundisyon sa dalawang bahagi: walang konteksto at sensitibo sa konteksto.
Ang iba't ibang RSPG ay cascade RSPG. Ang cascade ay isang RSP na nilagyan ng aksyon na 1shshsh1. Ang pagkilos na ito ay nagiging sanhi ng paghinto ng proseso sa cascade na ito, pag-imbak ng kasalukuyang impormasyon ng configuration sa stack, at tumalon sa mas malalim na cascade at pagkatapos ay bumalik sa orihinal nitong estado. Ang CPN ay may ilang mga tampok ng pagbabagong gramatika. Maaari rin itong gamitin bilang isang sistema ng pagbuo.
Ang paraan ng pagsusuri gamit ang isang scheme ng graph ay nagbibigay-daan sa iyo upang i-save ang mga bahagyang resulta at ipakita ang mga pagpipilian sa pagsusuri.
Ang isang bago at agad na sikat na paraan ng paglalarawan ng gramatika ay ang lexsho-functional grammar (LFG). Tinatanggal nito ang pangangailangan para sa mga tuntunin sa pagbabago. Bagama't ang LFG ay nakabatay sa QSG, ang mga kondisyon ng pagsubok sa loob nito ay hiwalay sa mga tuntunin ng pagpapalit at "nalutas" bilang mga autonomous equation.
Kinakatawan ng mga unification grammar (UG) ang susunod na yugto ng generalization ng modelo ng pagsusuri pagkatapos ng mga graph-scheme: nagagawa nilang isama ang mga grammar iba't ibang uri. Ang CG ay naglalaman ng apat na bahagi: isang unification package, isang interpreter para sa mga panuntunan at lexical na paglalarawan, mga programa para sa pagproseso ng mga direktang graph, at isang graph-scheme analyzer. Pinagsasama ng mga CG ang mga tuntunin sa gramatika sa mga paglalarawan ng diksyunaryo, mga syntactic valencies na may mga semantiko.
Ang pangunahing problema ng anumang sistema ng pagsusuri ng NL ay ang problema sa pagpili ng mga opsyon. Upang malutas ito, ang mga gramatika ng antas ng syntactic ay pupunan ng mga auxiliary na grammar at mga pamamaraan para sa pag-parse ng mga kumplikadong sitwasyon. Gumagamit ang mga NN-grammar ng filter at heuristic na pamamaraan. Ang paraan ng filter ay na sa una ang lahat ng mga variant ng pagsusuri ng pangungusap ay natatanggap, at pagkatapos ay ang mga hindi nakakatugon sa isang tiyak na sistema ng mga kundisyon ng filter ay tinatanggihan. Sa simula pa lang, ang heuristic na pamamaraan ay bumubuo lamang ng isang bahagi ng mga opsyon na mas kapani-paniwala sa mga tuntunin ng ibinigay na pamantayan. Ang paggamit ng mga timbang upang pumili ng mga opsyon ay isang halimbawa ng paggamit ng mga heuristic na pamamaraan sa pagsusuri.
Ang antas ng semantiko ay hindi gaanong binibigyan ng teorya at praktikal na mga pag-unlad. Ang tradisyunal na gawain ng semantics ay ang pag-alis ng kalabuan ng syntactic analysis - istruktura at lexical. Para dito, ginagamit ang apparatus ng mga piling paghihigpit, na nakatali sa balangkas ng mga pangungusap, ibig sabihin, umaangkop sa modelong sintaktik. Ang pinakakaraniwang uri ng SemAn ay batay sa tinatawag na case grammars. Ang grammar ay batay sa konsepto ng malalim, o semantiko, kaso. Ang case frame ng isang pandiwa ay isang extension ng konsepto ng valence: ito ay isang set ng semantic relations na maaaring (mandatoryo o opsyonal) samahan ang pandiwa at ang mga pagkakaiba-iba nito sa teksto. Sa loob ng parehong wika, ang parehong malalim na kaso ay natanto ng iba't ibang mga mababaw na anyo ng prepositional-case. Ang mga malalim na kaso, sa prinsipyo, ay nagbibigay-daan sa iyo na lumampas sa pangungusap, at ang pagpunta sa teksto ay nangangahulugang isang paglipat sa antas ng semantiko ng pagsusuri.
Dahil ang semantikong impormasyon, sa kaibahan sa syntactic na impormasyon na pangunahing nakabatay sa mga gramatika, ay pangunahing nakatuon sa mga diksyunaryo, ang mga grammar ay masinsinang binuo noong 1980s, na nagpapahintulot sa "lexicalization" ng mga CSG. Ang pagbuo ng mga gramatika batay sa pag-aaral ng mga katangian ng diskurso ay isinasagawa.
Mga Tagapagsalita: Irina Rybnikova at Anastasia Ponomareva.
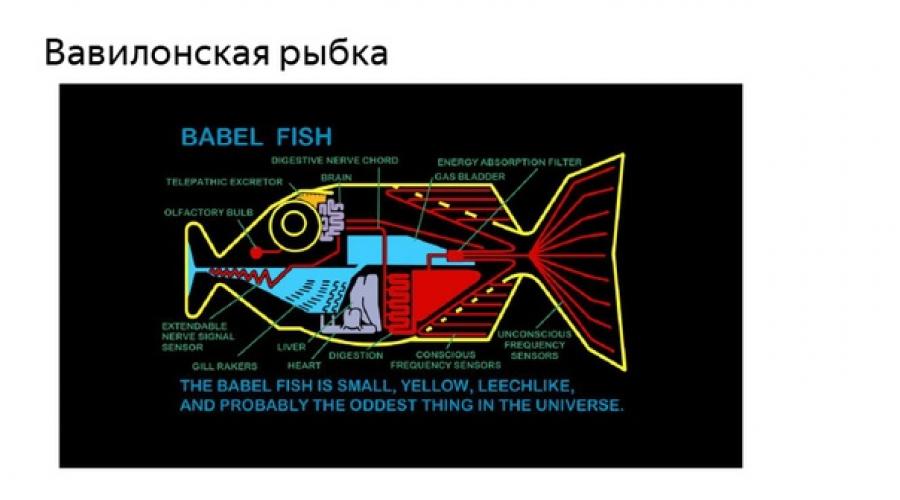
Pag-uusapan natin ang kasaysayan ng pagsasalin ng makina at kung paano natin ito ginagamit sa Yandex.
Noong ika-17 siglo, ang mga siyentipiko ay nag-isip tungkol sa pagkakaroon ng ilang uri ng wika na nag-uugnay sa iba pang mga wika, at ito ay malamang na matagal na ang nakalipas. Bumalik tayo ng mas malapit. Nais nating lahat na maunawaan ang mga tao sa paligid - kahit saan tayo dumating - gusto nating makita kung ano ang nakasulat sa mga karatula, gusto nating magbasa ng mga anunsyo, impormasyon tungkol sa mga konsyerto. Ang ideya ng isang Babylonian na isda ay nag-aararo sa isip ng mga siyentipiko, ay matatagpuan sa panitikan, sinehan - kahit saan. Gusto naming bawasan ang oras na kinakailangan para ma-access namin ang impormasyon. Gusto naming magbasa ng mga artikulo tungkol sa teknolohiyang Tsino, maunawaan ang anumang mga site na nakikita namin, at gusto naming matanggap ito dito at ngayon.

Sa konteksto nito, imposibleng hindi pag-usapan ang tungkol sa pagsasalin ng makina. Ito ang nakakatulong upang malutas ang problemang ito.

Ang panimulang punto ay itinuturing na 1954, nang ang 60 pangungusap sa mga pangkalahatang paksa ay isinalin sa USA sa isang makina ng IBM 701. organikong kimika mula sa Ruso hanggang Ingles, at lahat ng ito ay batay sa 250 glossary na termino at anim na panuntunan sa gramatika. Tinawag itong Georgetown Experiment, at labis na ikinagulat nito ang katotohanan na ang mga pahayagan ay puno ng mga ulo ng balita na isa pang tatlo hanggang limang taon, at ang problema ay ganap na malulutas, lahat ay magiging masaya. Ngunit tulad ng alam mo, ang mga bagay ay naging medyo iba.
Ang pagsasalin ng makina na nakabatay sa panuntunan ay lumitaw noong 1970s. Nakabatay din ito sa mga bilingual na diksyunaryo, ngunit sa mismong hanay ng mga panuntunan na tumulong sa paglalarawan ng anumang wika. Anuman, ngunit may mga paghihigpit.

Ang mga seryosong dalubhasang lingguwista ay kinakailangang isulat ang mga patakaran. Ito ay medyo mahirap na trabaho, hindi pa rin nito maaaring isaalang-alang ang konteksto, ganap na sumasaklaw sa anumang wika, ngunit sila ay mga eksperto, at hindi kinakailangan ang mataas na kapangyarihan sa pag-compute noon.

Sa pagsasalita ng kalidad, klasikong halimbawa- isang quote mula sa Bibliya, na pagkatapos ay isinalin tulad nito. Hindi pa sapat. Samakatuwid, ang mga tao ay patuloy na nagtatrabaho sa kalidad. Noong 1990s, lumitaw ang isang istatistikal na modelo ng pagsasalin, ang SMT, na nag-uusap tungkol sa probabilistikong pamamahagi ng mga salita, pangungusap, at ang sistemang ito ay sa panimula ay naiiba dahil wala itong alam sa lahat tungkol sa mga tuntunin at tungkol sa linggwistika. Nakatanggap siya ng malaking bilang ng magkaparehong teksto bilang input, ipinares sa isang wika at isa pa, at pagkatapos ay siya mismo ang gumawa ng mga desisyon. Madali itong mapanatili, hindi kailangan ng grupo ng mga eksperto, hindi na kailangang maghintay. Posibleng i-download at matanggap ang resulta.

Ang mga kinakailangan para sa papasok na data ay medyo karaniwan, mula 1 hanggang 10 milyong mga segment. Mga Segment - mga pangungusap, maliliit na parirala. Ngunit mayroong ilang mga paghihirap at ang konteksto ay hindi isinasaalang-alang, ang lahat ay hindi napakadali. At sa Russia, halimbawa, may mga ganitong kaso.

Gusto ko rin ang halimbawa ng mga pagsasalin ng mga laro ng GTA, ang resulta ay mahusay. Wala sa lugar ang lahat. Isang medyo mahalagang milestone ang 2016, nang ilunsad ang neural machine translation. Ito ay isang ganap na kaganapan sa paggawa ng panahon na lubos na nagpabaligtad sa buhay. Ang aking kasamahan, pagkatapos tingnan ang mga salin at kung paano namin ginagamit ang mga ito, ay nagsabi: "Astig, nagsasalita siya sa aking mga salita." At ito ay talagang mahusay.
Ano ang mga tampok? Mataas na kinakailangan sa pasukan, materyal sa pagsasanay. Sa panloob, mahirap mapanatili, ngunit isang makabuluhang pagtaas sa kalidad ang kung bakit ito nagsimula. Tanging ang de-kalidad na pagsasalin lamang ang makakalutas sa mga itinakdang gawain at magpapagaan ng buhay para sa lahat ng kalahok sa proseso, para sa mga tagapagsalin na ayaw magtama ng masamang pagsasalin, gusto nilang gumawa ng mga bagong gawaing malikhain, at magbigay ng mga karaniwang template ng parirala sa makina .
Sa loob ng machine translation, mayroong dalawang approach. Pagsusuri ng eksperto/ linguistic analysis ng mga teksto, iyon ay, pagsuri ng mga tunay na linguist, mga eksperto para sa pagsunod sa kahulugan, literacy ng wika. Sa ilang mga kaso, ang mga eksperto ay nakulong din, pinahintulutan silang i-proofread ang isinalin na teksto at tinasa kung gaano ito kabisa mula sa puntong ito.

Ano ang mga tampok ng pamamaraang ito? Ang isang sample na pagsasalin ay hindi kinakailangan, tinitingnan namin ang natapos na isinalin na teksto ngayon at sinusuri ito nang may layunin sa anumang aspeto. Ngunit ito ay mahal at matagal.

Mayroong pangalawang diskarte - mga awtomatikong sukatan ng sanggunian. Marami, bawat isa ay may kalamangan at kahinaan. Hindi ako lalalim, maaari mong basahin ang tungkol sa mga keyword na ito nang mas detalyado sa ibang pagkakataon.
Ano ang tampok? Sa katunayan, ito ay isang paghahambing ng mga isinalin na teksto ng makina na may ilang uri ng huwarang pagsasalin. Ito ay mga quantitative metric na nagpapakita ng pagkakaiba sa pagitan ng huwarang pagsasalin at kung ano ang nangyari. Ito ay mabilis, mura, at maaaring gawin nang maginhawa. Ngunit may mga tampok.

Sa katunayan, ang mga hybrid na pamamaraan ay madalas na ginagamit ngayon. Ito ay kapag ang isang bagay sa una ay awtomatikong sinusuri, pagkatapos ay ang error matrix ay nasuri, pagkatapos ay ang ekspertong linguistic analysis ay isinasagawa sa isang mas maliit na katawan ng mga teksto.

Kamakailan, ang kasanayan ay laganap pa rin kapag hindi namin tinatawag na mga linguist doon, ngunit simpleng mga gumagamit. Gumagawa ng interface - ipakita kung aling pagsasalin ang pinakagusto mo. O kapag pumunta ka sa mga online na tagapagsalin, naglalagay ka ng teksto, at madalas kang makakaboto sa kung ano ang pinakagusto mo, kung ang diskarte na ito ay angkop o hindi. Sa katunayan, sinasanay na nating lahat ang mga makinang ito, at lahat ng ibinibigay namin sa kanila para sa pagsasalin, ginagamit nila para sa pagsasanay at gumagana sa kanilang kalidad.
Gusto kong sabihin sa iyo kung paano namin ginagamit ang machine translation sa aming trabaho. Ibinigay ko ang sahig kay Anastasia.
Kami sa Yandex sa departamento ng lokalisasyon ay mabilis na napagtanto na ang mga posibilidad ng teknolohiya ng pagsasalin ng makina ay mahusay, at nagpasya kaming subukang gamitin ito sa aming mga pang-araw-araw na gawain. Saan tayo nagsimula? Nagpasya kaming gumawa ng isang maliit na eksperimento. Napagpasyahan naming isalin ang parehong mga teksto sa pamamagitan ng isang maginoo na tagasalin ng neural network, at gayundin na mag-ipon ng isang sinanay na tagasalin ng makina. Para magawa ito, naghanda kami ng corpora ng mga teksto sa pares ng Russian-English para sa mga taon na kami sa Yandex ay naglo-localize ng mga teksto sa mga wikang ito. Pagkatapos ay dinala namin ang grupo ng mga text na ito sa aming mga kasamahan mula sa Yandex.Translate at hiniling na sanayin ang makina.

Kapag ang makina ay sinanay, isinalin namin ang susunod na batch ng mga teksto, at, tulad ng sinabi ni Irina, sinuri namin ang mga resulta sa tulong ng mga eksperto. Hiniling namin sa mga tagasalin na tingnan ang literacy, istilo, spelling, paglipat ng kahulugan. Ngunit ang pinakanagbabagong punto ay noong sinabi ng isa sa mga tagapagsalin na "Kinikilala ko ang aking istilo, kinikilala ko ang aking mga pagsasalin."
Upang mapalakas ang mga damdaming ito, nagpasya kaming kalkulahin ang mga istatistikal na tagapagpahiwatig. Una, kinakalkula namin ang koepisyent ng BLEU para sa mga paglilipat na ginawa sa pamamagitan ng isang maginoo na neural network engine, at nakuha ang figure na ito (0.34). Mukhang dapat itong ihambing sa isang bagay. Muli kaming pumunta sa aming mga kasamahan mula sa Yandex.Translate at hiniling sa kanila na ipaliwanag kung anong BLEU coefficient ang itinuturing na threshold para sa mga pagsasaling ginawa ng isang tunay na tao. Ito ay mula sa 0.6.
Pagkatapos ay nagpasya kaming suriin ang mga resulta sa mga sinanay na pagsasalin. Nakakuha ng 0.5. Ang mga resulta ay talagang nakapagpapatibay.

Nagbibigay ako ng isang halimbawa. Ito ay isang tunay na pariralang Ruso mula sa dokumentasyon ng Yandex.Direct. Pagkatapos ay isinalin ito sa pamamagitan ng isang regular na neural network engine, at pagkatapos ay sa pamamagitan ng isang sinanay na neural network engine sa aming mga teksto. Nasa pinakaunang linya na, napansin namin na ang tradisyunal na uri ng advertising para sa Yandex.Direct ay hindi kinikilala. At nasa sinanay na neural network engine, lumilitaw ang aming pagsasalin, at kahit na ang pagdadaglat ay halos tama.
Tuwang-tuwa kami sa mga resulta, at nagpasya na malamang na sulit na gamitin ang makina ng makina sa iba pang mga pares, sa iba pang mga teksto, hindi lamang sa pangunahing hanay ng teknikal na dokumentasyong iyon. Pagkatapos ay isang serye ng mga eksperimento ang isinagawa sa loob ng ilang buwan. Nahaharap sa malaking dami mga feature at problema, ito ang mga pinakakaraniwang problema na kailangan naming lutasin.

Sasabihin ko sa iyo ang higit pa tungkol sa bawat isa.

Kung ikaw, tulad namin, ay gagawa ng customized na makina, kakailanganin mo ng sapat malaking bilang ng kalidad ng parallel data. Ang isang malaking makina ay maaaring sanayin sa dami ng 10,000 o higit pang mga pangungusap, sa aming kaso, naghanda kami ng 135,000 parallel na mga pangungusap.

Hindi sa lahat ng uri ng teksto ang iyong makina ay magpapakita ng parehong magagandang resulta. Sa teknikal na dokumentasyon kung saan may mahahabang pangungusap, istraktura, dokumentasyon ng user, at maging sa interface kung saan may maikli ngunit hindi malabo na mga pindutan, malamang na magagawa mo nang maayos. Ngunit marahil, tulad namin, makakatagpo ka ng mga problema sa marketing.
Nagsagawa kami ng isang eksperimento, nagsasalin ng mga playlist ng musika, at nakakuha ng ganitong halimbawa.

Narito kung ano ang iniisip ng isang machine translator tungkol sa mga star factory ladies. Ano ang mga tambol ng paggawa.

Kapag nagsasalin sa pamamagitan ng makina ng makina, hindi isinasaalang-alang ang konteksto. Ito ay hindi tulad ng isang nakakatawang halimbawa, ngunit medyo totoo, mula sa teknikal na dokumentasyon ng Yandex.Direct. Mukhang mauunawaan ang mga iyon kapag nagbasa ka ng teknikal na dokumentasyon, mga teknikal. Ngunit hindi, hindi tumama ang makina ng makina.

Dapat mo ring isaalang-alang na ang kalidad at kahulugan ng pagsasalin ay lubos na nakasalalay sa orihinal na wika. Isinasalin namin ang parirala sa Pranses mula sa Ruso, nakakakuha kami ng isang resulta. Nakakakuha kami ng katulad na parirala na may parehong kahulugan, ngunit mula sa Ingles, at nakakuha kami ng ibang resulta.

Kung ikaw, tulad ng sa aming teksto, ay may isang malaking bilang ng mga tag, markup, ilang mga teknikal na tampok, malamang na kakailanganin mong subaybayan ang mga ito, i-edit at magsulat ng ilang mga script.
Narito ang mga halimbawa ng isang tunay na parirala mula sa browser. Ang mga panaklong ay mga teknikal na impormasyon na hindi dapat isalin, sa partikular na mga plural na anyo. Sa Ingles sila ay nasa Ingles, at sa Aleman dapat din silang manatili sa Ingles, ngunit sila ay isinalin. Kailangan mong subaybayan ang mga sandaling ito.

Walang alam ang native engine tungkol sa iyong mga convention sa pagbibigay ng pangalan. Halimbawa, mayroon kaming kasunduan na tinatawag naming Yandex.Disk kahit saan sa Latin sa lahat ng wika. Ngunit sa Pranses ito ay nagiging isang disc sa Pranses.

Ang mga pagdadaglat ay minsan nakikilala nang tama, minsan hindi. Sa halimbawang ito, ang BY, na nagsasaad na kabilang sa mga teknikal na kinakailangan ng Belarus para sa advertising, ay nagiging isang preposisyon sa Ingles.

Isa sa mga paborito kong halimbawa ay ang mga bago at hiram na salita. Narito ang isang cool na halimbawa, ang salitang disclaimer, "primordially Russian." Ang mga terminolohiya ay kailangang ma-verify para sa bawat bahagi ng teksto.
At isa pa, hindi na ganoon ka makabuluhang problema - hindi napapanahong spelling.

Dati, ang Internet ay isang bago, sa lahat ng mga teksto ito ay isinulat na may malaking titik, at noong sinanay namin ang aming makina, ang Internet ay nasa lahat ng dako na may malaking titik. Ngayon ay isang bagong panahon, ang Internet ay sumusulat na gamit ang isang maliit na titik. Kung gusto mong patuloy na gamitin ng iyong makina ang internet, kakailanganin mong sanayin itong muli.

Hindi kami nawalan ng pag-asa, nalutas namin ang mga problemang ito. Una, binago namin ang corpora ng mga teksto, sinubukan naming isalin sa ibang mga paksa. Ipinasa namin ang aming mga komento sa aming mga kasamahan mula sa Yandex.Translate, muling sinanay ang neural network at tiningnan ang mga resulta, sinuri ang mga ito, at humingi ng mga pagpapabuti. Halimbawa, pagkilala sa tag, pagpoproseso ng HTML markup.
ipapakita ko tunay na mga pagpipilian gamitin. Mahusay kami sa machine translation para sa teknikal na dokumentasyon. Ito ay isang tunay na kaso.

Narito ang parirala sa Ingles at Ruso. Ang tagasalin na humawak ng dokumentasyong ito ay labis na hinikayat ng sapat na pagpili ng terminolohiya. Isa pang halimbawa.

Pinahahalagahan ng tagasalin ang pagpili ng ay sa halip na isang gitling, na nagpabago sa istruktura ng parirala sa Ingles, isang sapat na pagpili ng termino, na tama, at ang salitang ikaw, na wala sa orihinal, ngunit ginagawa nitong pagsasalin eksaktong Ingles, natural.

Ang isa pang kaso ay ang mga pagsasalin ng interface on the fly. Nagpasya ang isa sa mga serbisyo na huwag mag-abala sa lokalisasyon at magsalin ng mga teksto sa oras ng pag-download. Ngunit pagkatapos na baguhin ang makina, halos isang beses sa isang buwan, ang salitang "paghahatid" ay nagbago sa isang bilog. Iminungkahi namin na ang koponan ay hindi kumonekta sa isang maginoo na neural network engine, ngunit sa amin, sinanay sa teknikal na dokumentasyon, upang ang parehong termino ay palaging ginagamit, sumang-ayon sa koponan, na nasa dokumentasyon na.

Paano nakakaapekto ang lahat ng ito sa pera? Ayon sa kaugalian, nangyari na sa pares ng Russian-Ukrainian, kinakailangan ang minimal na pag-edit ng pagsasalin ng Ukrainian. Kaya nagpasya kaming ilang buwan na ang nakalipas na lumipat sa isang post-editing system. Ganito ang paglago ng ating ekonomiya. Hindi pa tapos ang Setyembre, ngunit tinatantya namin na nabawasan namin ang aming mga gastos sa post-editing ng humigit-kumulang isang katlo sa Ukrainian, at ie-edit namin ang halos lahat maliban sa mga teksto sa marketing. Isang salita kay Irina para sa pagbubuod.
Irina:
- Ito ay nagiging halata sa lahat na ito ay kinakailangan upang gamitin ito, ito ay ang aming katotohanan, at hindi ito maaaring ibukod sa aming mga proseso at interes. Ngunit kailangan mong mag-isip tungkol sa ilang mga bagay.

Magpasya sa mga uri ng mga dokumento, ang konteksto kung saan ka nagtatrabaho. Tama ba sa iyo ang teknolohiyang ito?
Pangalawang sandali. Napag-usapan namin ang tungkol sa Yandex.Translate, dahil kami ay nasa magandang relasyon, mayroon kaming direktang access sa mga developer, at iba pa, ngunit sa katunayan kailangan mong magpasya kung alin sa mga makina ang magiging pinakamainam para sa iyo partikular, para sa iyong wika, sa iyong paksa. Ang paksang ito ang magiging pokus ng susunod na ulat. Maging handa na may mga paghihirap pa rin, ang mga developer ng makina ay nagtutulungan upang malutas ang mga paghihirap, ngunit sa ngayon sila ay nakatagpo pa rin.

Gusto naming maunawaan kung ano ang nakalaan para sa amin sa hinaharap. Ngunit sa katunayan, hindi na ito higit pa, kundi atin. ngayon ano ang nangyayari dito at ngayon. Mas kailangan nating lahat ang pagpapasadya para sa ating terminolohiya, para sa ating mga teksto, at ito ang nagiging pampubliko ngayon. Ngayon lahat ay nagtatrabaho upang matiyak na hindi ka papasok sa loob ng kumpanya, huwag makipag-ayos sa mga developer ng isang partikular na makina, kung paano ito i-optimize para sa iyo. Makukuha mo ito sa mga pampublikong bukas na makina sa pamamagitan ng API.
Napupunta ang pagpapasadya hindi lamang sa mga teksto, kundi pati na rin sa terminolohiya, sa pagpapasadya ng terminolohiya para sa iyong sariling mga pangangailangan. Ito ay isang mahalagang punto. Ang pangalawang tema ay interactive na pagsasalin. Kapag nagsalin ang isang tagasalin ng teksto, pinapayagan siya ng teknolohiya na mahulaan ang mga susunod na salita na ibinigay sa pinagmulang wika, ang pinagmulang teksto. Maaari nitong gawing mas madali ang trabaho.
Tungkol sa kung ano ang talagang mahal ngayon. Ang bawat tao'y nag-iisip kung paano sanayin ang ilang mga makina nang mas mahusay na may mas maliit na dami ng teksto. Ito ay isang bagay na nangyayari sa lahat ng dako at inilunsad kahit saan. Sa tingin ko ang paksa ay napaka-interesante, at higit pa ito ay magiging mas kawili-wili.
Machine Translation: Isang Maikling Kasaysayan
Sinubukan ng isa pang namumukod-tanging matematiko noong ika-19 na siglo, si Charles Babbage, na kumbinsihin ang gobyerno ng Britanya sa pangangailangang gastusan ang kanyang pananaliksik upang mapaunlad ang " kompyuter". Sa iba pang mga benepisyo, ipinangako niya na balang araw ang makinang ito ay awtomatikong makapagsasalin ng kolokyal na pananalita. Gayunpaman, ang ideyang ito ay nanatiling hindi natutupad [Chaliapina 1996: 105].
Ang petsa ng kapanganakan ng machine translation bilang isang larangan ng pananaliksik ay karaniwang itinuturing na Marso 1947. Noon ang cryptographer na si Warren Weaver, sa kanyang liham kay Norbert Wiener, ay unang nagbigay ng problema sa machine translation, na inihambing ito sa problema ng decryption.
Ang parehong Weaver, pagkatapos ng isang serye ng mga talakayan, ay nag-compile ng isang memorandum noong 1949, kung saan ayon sa teorya ay pinatunayan niya ang pangunahing posibilidad ng paglikha ng mga sistema ng pagsasalin ng makina. Sumulat si W. Weaver: "Mayroon akong isang text sa harap ko na nakasulat sa Russian ngunit magpapanggap ako na ito ay talagang nakasulat sa Ingles at na ito ay na-code sa ilang kakaibang mga simbolo. Ang kailangan ko lang gawin ay hubarin off the code in order to retrieve the information contained in the text" ("Mayroon akong isang text na nakasulat sa Russian bago ang aking mga mata, ngunit ako ay magpapanggap na ito ay aktwal na nakasulat sa Ingles at naka-encode gamit ang medyo kakaibang mga character. All I kailangan ay basagin ang code upang kunin ang impormasyong nakapaloob sa teksto") [Slocum 1989: 56-58].
Ang mga ideya ni Weaver ay naging batayan ng isang diskarte sa MT batay sa konsepto interlingua: Ang yugto ng paglilipat ng impormasyon ay nahahati sa dalawang yugto. Sa unang yugto, ang pinagmulang pangungusap ay isinalin sa isang intermediary na wika (nilikha batay sa pinasimpleng Ingles), at pagkatapos ay ang resulta ng pagsasaling ito ay ipinakita sa pamamagitan ng target na wika.
Noong mga panahong iyon, ang ilang mga computer ay pangunahing ginagamit para sa paglutas ng mga problema sa militar, kaya hindi nakakagulat na sa USA ang pangunahing pansin ay binabayaran sa Russian-English, at sa USSR - sa pagsasalin ng English-Russian. Sa simula ng 1950s, maraming grupo ng pananaliksik ang nahihirapan sa problema ng awtomatikong pagsasalin.
Noong 1952, ang unang kumperensya sa MT ay ginanap sa Massachusetts Institute of Technology, at noong 1954 ang unang ganap na sistema ng pagsasalin ng makina ay ipinakilala - ang IBM Mark II, na binuo ng IBM kasama ng Georgetown University (ang kaganapang ito ay bumagsak sa kasaysayan bilang ang eksperimento sa Georgetown). Ang system, na napakalimitado sa mga kakayahan nito, ay perpektong isinalin ang 49 na espesyal na piniling mga pangungusap mula sa Russian patungo sa Ingles gamit ang isang 250-salitang diksyunaryo at anim na panuntunan sa gramatika.
Isa sa mga bagong pag-unlad noong 1970s at 1980s ay ang TM (translation memory) na teknolohiya, na gumagana sa prinsipyo ng akumulasyon: sa panahon ng proseso ng pagsasalin, ang orihinal na segment (pangungusap) at ang pagsasalin nito ay nai-save, na nagreresulta sa pagbuo ng isang database ng lingguwistika; kung ang isang kapareho o katulad na segment ay makikita sa bagong isinaling teksto, ito ay ipapakita kasama ng pagsasalin at isang indikasyon ng porsyento na tugma. Ang tagasalin pagkatapos ay gumawa ng desisyon (upang i-edit, tanggihan o tanggapin ang pagsasalin), ang resulta nito ay iniimbak ng system.
Mula noong simula ng 80s, nang ang mga personal na computer ay may kumpiyansa at malakas na nagsimulang sakupin ang mundo, ang kanilang oras ng pagpapatakbo ay naging mas mura, at maaari silang ma-access anumang oras. Ang MP ay naging matipid sa ekonomiya. Bilang karagdagan, sa mga ito at sa mga sumunod na taon, ang pagpapabuti ng mga programa ay naging posible upang maisalin ang maraming uri ng mga teksto nang tumpak, ngunit ang ilang mga problema ng MT ay nanatiling hindi nalutas hanggang sa araw na ito.
Ang 1990s ay maaaring ituring na isang tunay na renaissance sa pagbuo ng MT, na nauugnay hindi lamang sa mataas na antas ng mga kakayahan ng mga personal na computer, kundi pati na rin sa pagkalat ng Internet, na humantong sa isang tunay na pangangailangan para sa MT. Muli itong naging isang kaakit-akit na lugar para sa pamumuhunan, kapwa para sa mga pribadong mamumuhunan at para sa mga istruktura ng estado.
Mula noong unang bahagi ng 1990s, ang mga developer ng Russia ay pumapasok sa merkado ng mga sistema ng PC.
Noong Hulyo 1990, ang unang komersyal na sistema ng pagsasalin ng makina sa Russia na tinatawag na PROMT (Programmer's Machine Translation) ay ipinakita sa PC Forum sa Moscow. Nanalo ang PROMT sa kompetisyon ng NASA para sa supply ng mga MP system (PROMT ang tanging kumpanyang hindi Amerikano sa kompetisyong ito. ) [Kulangin 1979: 324].
Tulad ng para sa mga sistema ng pagsasalin ng makina mismo, dapat tandaan na dumaan sila sa tatlong yugto ng kanilang pag-unlad:
- 1. "Mga elektronikong tagapagsalin" ng unang henerasyon - direktang mga sistema ng pagsasalin (NTS)- ay mga sistema ng software at hardware at sinuri ang teksto na "salita sa salita" (mga koneksyon sa semantiko at mga nuances ay halos hindi isinasaalang-alang). Ang mga kakayahan ng SPP ay tinutukoy ng mga magagamit na laki ng mga diksyunaryo, na direktang nakasalalay sa dami ng memorya ng computer. Ang IBM Mark II, na ginawang posible ang eksperimento sa Georgetown, ay kabilang sa kategorya ng NGN.
- 2. Sa paglipas ng panahon, ang SPP ay napalitan ng T-mga sistema(mula sa English Transfer - "pagbabagong-anyo"), kung saan isinagawa ang pagsasalin sa antas ng mga istrukturang sintaktik (ito ay kung paano itinuro ang wika sa mataas na paaralan). Nagsagawa sila ng isang hanay ng mga operasyon na nagpapahintulot, sa pamamagitan ng pagsusuri sa isinaling parirala, upang matukoy ang syntactic na istraktura nito ayon sa mga tuntunin ng grammar ng input na wika, at pagkatapos ay ibahin ito sa syntactic na istraktura ng output na pangungusap at mag-synthesize ng isang bagong parirala, na pinapalitan ang mga kinakailangang salita mula sa diksyunaryo ng output na wika. Ang gawain sa direksyon na ito ay hindi na isinasagawa: ang pagsasanay ay napatunayan na ang tunay na sistema ng mga sulat ay mas kumplikado at ang isang sapat na pagsasalin ay nangangailangan ng isang panimula na naiibang algorithm ng mga aksyon.
- 3. Makalipas ang ilang sandali, ang dumaraming sistema ng pagsasalin ng makina, depende sa prinsipyo ng kanilang gawain, ay nagsimulang hatiin sa MT-mga programa(mula sa Machine Translation - "pagsasalin ng makina") at TM-mga complex(mula sa Translation Memory - "translation memory"). Bilang isang tunay na matagumpay na halimbawa ng isang MT program, pangalanan natin ang sikat na Canadian system na METEO, na nagsasalin ng mga pagtataya ng panahon mula sa French sa English at vice versa (ito ay nilikha halos tatlumpung taon na ang nakakaraan at gumagana pa rin ngayon). Ang mga developer ng METEO ay tumaya na ang tunay na awtomatikong pagsasalin ng makina ay posible lamang sa ilalim ng mga kundisyong artipisyal na limitado (tulad ng sa bokabularyo, at gramatika) ng wika. At sila ay nagtagumpay. Ang pinakasikat na propesyonal sa mundo TM-kasangkapan ay ang TRADOS Translation "s Workbench package. Pangunahing ginagamit ang mga naturang programa mga propesyonal na tagapagsalin na natanto ang pakinabang ng bahagyang pag-automate ng kanilang trabaho sa tulong ng isang computer kapag nagsasalin ng mga paulit-ulit na teksto na magkapareho sa paksa at istruktura.
Ang pangunahing ideya ng Translation Memory ay hindi upang isalin ang parehong teksto nang dalawang beses. Nakabatay ang teknolohiyang ito sa paghahambing ng dokumentong isasalin sa data na nakaimbak sa isang naunang ginawang database ng "input". Kapag nakahanap ang system ng isang fragment na nakakatugon sa mga paunang natukoy na pamantayan, ang pagsasalin nito ay kinuha mula sa "output" na base. Ang resultang teksto ay napapailalim sa intensive human post-editing [Marchuk 1997: 21-22].
Kabanata 1 Mga Konklusyon
Sa Kabanata 1, tiningnan namin kung ano ang pagsasalin. Iniisa-isa namin ang mga uri, anyo at genre nito. Isinaalang-alang din namin ang pagsasalin ng makina. Nang matugunan ang paksa ng pagsasalin ng makina, sinuri namin ang maikling kasaysayan nito, pati na rin ang lugar na kinaroroonan nito. Pangkalahatang pag-uuri pagsasalin. Nalaman namin kung paano gumagana ang translator program.
Ang mga unang eksperimento sa pagsasalin ng makina, na nakumpirma ang pangunahing posibilidad ng pagpapatupad nito, ay isinagawa noong 1954 sa Georgetown University (Washington, USA). Di-nagtagal pagkatapos noon, nagsimula ang pananaliksik at pag-unlad sa mga industriyalisadong bansa sa mundo na naglalayong lumikha ng mga sistema ng pagsasalin ng makina. At bagaman mahigit kalahating siglo na ang lumipas mula noon, ang problema sa pagsasalin ng makina ay hindi pa rin nalulutas sa tamang antas. Ito ay naging mas mahirap kaysa sa naisip ng mga pioneer at mahilig sa machine translation noong huling bahagi ng limampu at unang bahagi ng ikaanimnapung taon. Samakatuwid, ang pagtatasa ng katotohanan ngayon, ang isang tao ay kailangang pag-usapan ang parehong mga tagumpay at pagkabigo.
Nasabi na namin na upang turuan ang makina na magsalin, isang semantikong modelo ng pagsasalin ang nilikha batay sa "generative semantics" at ang kasalukuyang modelo ng wika na "nangangahulugang ↔ text". Ang gawain ay magbigay elektronikong utak sapat na bilang ng mga kasingkahulugan, converses, syntactic derivatives at semantic parameters na maaari niyang manipulahin sa proseso ng pagsasalin. At ang pagsasalin noong panahong iyon ay naunawaan lamang bilang isang proseso ng pagpapalit ng mga salita at parirala ng isang wika para sa mga salita at parirala ng ibang wika.
Ito rin ang panahon kung kailan sinusubukan ng mga linguist na nagtatrabaho sa larangan ng machine translation na ilarawan ang natural na wika gamit ang mga simbolo ng matematika. Hindi tulad nina Retzker at Fedorov, na naghangad na itatag ang umiiral na mga pattern sa batayan ng mga praktikal na obserbasyon, itinakda nila bilang kanilang layunin ang paglikha ng isang deduktibong teorya. Ito ay tungkol sa pagbuo ng isang hanay ng mga tuntunin, ang paglalapat nito sa isang tiyak na hanay ng mga yunit ng wika ay maaaring humantong sa pagbuo ng isang makabuluhang teksto. Mga yunit ng wika kumilos bilang mga simbolo ng matematika, na, bilang resulta ng paglalapat sa kanila ng mga tuntunin sa itaas, na ipinahayag din sa matematika, ay maaaring isaayos sa isang tiyak na paraan. Pagkatapos ng pag-decode, ang kumbinasyon ng mga character ay naging teksto.
Lumikha ang mga siyentipiko ng isang espesyal na wika, na binubuo ng mga simbolo ng matematika, na maaaring gamitin ng isang makina bilang isang tagapamagitan sa paglipat mula sa pinagmulang teksto patungo sa target na teksto. Ang wikang tagapamagitan ay ang "metal-language" ng teorya ng pagsasalin. Sa linguistics, ang metalanguage ay karaniwang nauunawaan bilang isang "pangalawang-order na wika", iyon ay, ang wika kung saan ang pangangatwiran tungkol sa natural na wika o anumang iba pang mga phenomena ay binuo. Kaya, kapag nagsasalita tungkol sa gramatika, gumagamit kami ng mga espesyal na salita, o termino, at expression, at kapag tinatalakay ang larangan ng medisina, gumagamit kami ng ibang terminological apparatus. Sa madaling salita, ang metalanguage, o "intermediary language", ng pagsasalin ay isang kumplikado ng istruktura at linguistic na katangian na nagbibigay-daan sa paglalarawan ng proseso ng pagsasalin na may sapat na pagkakumpleto.
Ayon sa layunin ng mga may-akda ng teorya ng pagsasalin ng makina, ang intermediary na wika ay batay sa konseptwal na kagamitan ng "pagbuo ng semantics" at ang modelo ng "sense ↔ text". Isang hanay ng mga panuntunan ang inihanda upang gawing mga pangunahing pangungusap ang mga istrukturang pang-ibabaw ng wikang Ingles. Inaasahan pa ng mga siyentipiko na, sa tulong ng isang intermediary na wika, madaling i-convert ng makina ang malalalim na istruktura ng pinagmulang wika sa malalim na istruktura ng target na wika at pagkatapos ay sa mga istrukturang pang-ibabaw nito. Ngunit ang mga resultang nakuha ay hindi lubos na kasiya-siya. Ang kalidad ng pagsasalin ng makina ay naging napakahina at ang kasunod na mga pagtatangka upang mapabuti ito ay hindi nagtagumpay. Ano ang dahilan?
Tulad ng nabanggit kanina, ang mga siyentipiko sa oras na iyon, iyon ay, sa unang bahagi ng ikalimampu at kalagitnaan ng ikaanimnapung taon ng huling siglo, ay ginagabayan ng linguistic theory of structuralism, batay sa paglalarawan at interpretasyon ng linguistic phenomena na mahigpit sa loob ng balangkas ng intralinguistic na relasyon. at hindi pagpayag na lumampas sa mga limitasyon ng istrukturang pangwika sa pagsusuri ng mga penomena na ito. Tiyak na alam nila kung ano ang alam ng bawat praktikal na tagasalin. Ibig sabihin, ang kahalagahan ng pagsasaalang-alang sa tiyak na sitwasyon kung saan nagaganap ang akto ng interlingual na komunikasyon, gayundin ang sitwasyong inilarawan sa mensaheng isinasalin. Ang impormasyong ito, mula sa punto ng view ng kalidad ng isinalin na teksto, ay gumaganap ng hindi bababa sa isang papel kaysa sa aktwal na linguistic phenomena.
Upang maitugma ang sitwasyong ito sa pangangailangang huwag lumampas sa mga ugnayang intralinggwistiko, iminungkahi na hatiin ang aktibidad ng pagsasalin sa dalawang bahagi - ang pagsasalin mismo, na isinasagawa ayon sa ibinigay na mga tuntunin nang hindi gumagamit ng extralinguistic na realidad na makikita sa karanasan o persepsyon ng tagasalin, at interpretasyon, kabilang ang paglahok ng extralinguistic na data.
Ngunit malinaw na sumasalungat ito sa nalalaman natin tunay na proseso conventional, iyon ay, hindi-machine translation. Para sa pagsasalin na isinasagawa ng isang tao, isang organiko at hindi mapaghihiwalay na pagkakaisa ng wastong linggwistiko at extralinguistic na mga salik ay katangian. Ang katotohanan ay na sa anumang gawain sa pagsasalita, hindi lahat ay ipinahayag nang tahasan, o, tulad ng sinasabi ng mga linggwista, tahasan. Karamihan ay karaniwang nananatiling hindi ipinahayag, ipinahiwatig. Ang bawat pahayag ay naka-address sa isang partikular na tao o isang partikular na madla. Ang may-akda ng pahayag ay nagpapatuloy mula sa katotohanan na ang kanyang mga tagapakinig o mga mambabasa ay may sapat na kaalaman upang malinaw na bigyang-kahulugan ito o ang mensaheng iyon nang walang paglilinaw ng mga detalye.
Kaya, ang pagsasalin ng makina, batay lamang sa pagsusuri ng mga pormal at istruktural na mga pattern ng pinagmulang teksto, ay hindi nagpapahintulot na ibunyag ang interaksyon ng linguistic at extralinguistic na mga kadahilanan at, sa gayon, iniiwan ang pinakamahalagang bahagi ng interlingual na komunikasyon. Ito ang pangunahing dahilan ng hindi kasiya-siyang kalidad nito.
Maraming mga mananaliksik ang umamin na, kahit na sa kasalukuyang panahon, walang mga tagumpay sa pagsasalin ng makina sa pagpapatupad ng iba pang mga modelo, sa kabila ng katotohanan na ang mga kakayahan ng mga computer ay tumaas nang maraming beses kumpara sa simula ng trabaho sa pagsasalin ng makina, at ang mga bagong programming language ay lumitaw, mas maginhawa para sa pagpapatupad ng mga programa para sa paglikha ng machine translation. Ang buong punto, tila, ay ang interpretasyon ng mga linguistic sign na may kaugnayan sa extralinguistic na realidad sa maraming aspeto ay intuitive sa likas na katangian at isinasagawa nang hindi sinasadya, o, gaya ng sinasabi nila, "sa subcortex", at kung ano ang ginagawa nang hindi sinasadya ay hindi maaaring. pormal at inilipat sa makina sa anyo ng software. Samakatuwid, ang pagsasalin ng makina ay nangangailangan pa rin ng isang editor ng tao pagkatapos nito at nagsisilbing mapagkukunan ng maraming biro sa pagsasalin.
Kaya, sa sandaling ang makina ay hiniling na isalin sa Ingles, at pagkatapos ay agad na bumalik sa Russian, ang kasabihan na "Wala sa paningin, wala sa isip." Ang huling bersyon ay: "The Invisible Idiot." Bakit? Dahil ang katumbas na salawikain sa Ingles ay nagsasabing: "Outofsight- outofmind". Nahanap ito ng makina nang walang kahirap-hirap. Ngunit sa baligtad na pagsasalin ng salawikain na ito sa Ruso, napunta siya sa maling paraan. Ang katotohanan ay sa Russian mayroong mga direktang sulat sa parehong mga bahagi pariralang Ingles: Wala sa paningin - ay inihatid ng salitang "invisible", habang ang English outofmind ay tumutugma sa mga salitang Ruso na "crazy, insane, idiot". Sinamantala ng makina ang mga sulat na ito. Hindi lang niya nahulaan na ang parehong pinangalanang mga bahagi ng pariralang Ingles ay hindi dapat ipadala nang hiwalay, ngunit sa kabuuan. Dahil sa kawalan niya ng "human factor".
Sa pangkalahatan, ang antas ng kalidad ng machine translation ng mga teksto, kontrata, tagubilin, siyentipikong ulat, atbp. higit na mataas kaysa sa mga tekstong may likas na peryodista. Narito ang ilang mga halimbawa:
Ang mga pagbabayad sa ilalim ng kontratang ito para sa kagamitang nakalista sa suplemento 1 sa kontrata ay dapat isagawa bilang mga sumusunod.
Ang mga pagbabayad sa ilalim ng kontratang ito para sa kagamitang nakalista sa Appendix 1 sa kontrata ay dapat gawin bilang mga sumusunod.
Ngunit maraming bitag ang naghihintay kay Mr. Bush kung susubukan niyang gawin itong mag-isa.
Ngunit maraming mga kalamnan ng trapezius ang naghihintay kay Mr. Bush kung susubukan niyang lakarin ito nang mag-isa.
Ang mga merkado, na binigyan ng higit pa at mas maaga kaysa sa anumang dahilan na inaasahan nila, ay nagulat lahat.
Ang mga merkado na ibinigay nang higit pa at mas maaga kaysa sa kanilang inaasahan, nagulat nang husto.
Ang lahat ng nasa itaas ay nagbibigay-daan sa amin na maghinuha na ang mga pioneer ng machine translation at ang kanilang mga agarang kahalili ay nakamit ang makabuluhang tagumpay sa larangang ito. Ngunit nabigo pa rin silang malutas ang marami sa pinakamahahalagang problema. Kaugnay nito, ang pahayag ng pinuno ng mga Hapon programa ng estado pagsasalin ng makina ni Propesor Makoto Nagao ng Kyoto University. Sa isa sa kanyang mga artikulo na inilathala noong 1982, ginawa niya ang sumusunod na pahayag: "Ang bawat pag-unlad ng mga sistema ng pagsasalin ng makina ay darating sa isang dead end. Ang aming pag-unlad ay makakarating din sa isang patay na dulo, ngunit susubukan naming gawin ito nang huli hangga't maaari.
Sa parehong taon, inilathala ni Propesor Nagao ang isang artikulo kung saan iminungkahi niya ang isang bagong konsepto para sa pagsasalin ng makina. Ayon sa konseptong ito, ang mga pagsusulit ay dapat na isalin sa pamamagitan ng pagkakatulad sa iba pang mga teksto na dati nang isinalin sa pamamagitan ng kamay, iyon ay, hindi ng isang makina, ngunit ng isang tagasalin. Para sa layuning ito, dapat na mabuo ang isang malaking hanay ng mga tekstong may katulad na tema at ang kanilang mga pagsasalin (bilingual), na pagkatapos ay ipasok sa isang napakalakas na multiprocessor na computer. Sa proseso ng pagsasalin ng mga bagong teksto, ang mga analogue ng mga fragment ng mga tekstong ito ay dapat mapili mula sa hanay ng mga bilingual, na maaaring magamit upang mabuo ang huling teksto. Tinawag ni M. Nagao ang kanyang diskarte sa pagsasalin ng makina na "Examplebasedtranslation" (pagsasalin batay sa mga halimbawa), at ang tradisyunal na diskarte - "Rulebasedtranslation" (translation according to the rules).
Ang konsepto ni Makoto Nagao ay sumasalamin sa kamakailang malawak na ginamit na konsepto ng "TranslationMemory" (translation memory), kung minsan ay tinutukoy bilang "SentenceMemory" (imbakan ng pangungusap). Ang kakanyahan ng konseptong ito ay ang mga sumusunod. Kapag naghahanda ng mga bersyon sa wikang banyaga ng anumang mga dokumento (halimbawa, dokumentasyon ng pagpapatakbo para sa mga produkto ng isang planta ng paggawa ng makina) sa una ang kanilang pagsasalin ay isinasagawa nang manu-mano ng mga tagapagsalin ng pinakamataas na kwalipikasyon. Pagkatapos ang mga orihinal na dokumento at ang kanilang mga pagsasalin sa isang wikang banyaga ay ipinasok sa isang computer, nahahati sa magkakahiwalay na mga pangungusap o mga fragment ng mga pangungusap, at isang database ay binuo mula sa mga elementong ito, na pagkatapos ay ikinarga sa isang search engine. Kapag nagsasalin ng mga bagong teksto, ang search engine ay naghahanap ng mga pangungusap at mga bahagi ng mga pangungusap sa mga ito na katulad ng mayroon ito at ipinapasok ang mga ito sa tamang lugar isinalin na teksto. Kaya, sa awtomatikong mode, ang isang mataas na kalidad na pagsasalin ng mga fragment ng bagong teksto na magagamit sa database ay nakuha.
Ang hindi natukoy na mga fragment ng teksto ay manu-manong isinalin sa isang wikang banyaga. Sa kasong ito, maaari mong gamitin ang pamamaraan para sa isang tinatayang paghahanap para sa mga fragment na ito sa database, at gamitin ang mga resulta ng paghahanap bilang isang pahiwatig. Ang mga resulta ng manu-manong pagsasalin ng mga bagong fragment ng teksto ay muling ipinasok sa database. Habang dumarami ang mga dokumentong isinasalin, unti-unting napapayaman ang "translation memory" at tataas ang kahusayan nito.
Ang hindi mapag-aalinlanganang bentahe ng teknolohiyang "translation memory" ay mataas na kalidad mga pagsasalin ng klase ng mga teksto kung saan ito nilikha. Ngunit ang batayan ng mga pagsusulatan sa pagsasalin na binuo para sa mga homogenous na teksto ng isang negosyo ay angkop lamang para sa mga homogenous na teksto ng mga negosyo na malapit sa profile, dahil ang mga pangungusap at malalaking fragment ng mga pangungusap na nakuha mula sa mga teksto ng isang dokumento, bilang panuntunan, ay hindi nangyayari o napaka bihirang makita sa mga teksto ng iba pang mga dokumento.
Upang malampasan ang limitasyong ito ng "memorya ng pagsasalin" at, pinaka-mahalaga, upang makawala sa hindi pagkakasundo kung saan, tila, ang teoryang semantiko ay pumasok, isang bagong konsepto ng pagsasalin ng makina, na tinatawag na "teorya ng parirala ng pagsasalin ng makina", ay itinuro. Pangunahing Tampok Ang konseptong ito ay ang ideya na kapag isinasalin bilang pangunahing at pinaka-matatag na mga yunit ng kahulugan, hindi dapat isaalang-alang ang mga semantikong sangkap na mahalagang bahagi ng wika, ngunit ang mga konseptong nauugnay sa wika sa pamamagitan ng mga kahulugang pangwika, ngunit sa parehong oras ay kumikilos bilang malayang anyo pag-unawa ng tao sa kapaligiran materyal na mundo. Kaya, ang unang hakbang ay ginawa upang turuan ang makina na gumana hindi lamang sa linguistic, kundi pati na rin sa mga extralinguistic na aspeto ng pagsasalin.
Hayaan mong ipaalala ko sa iyo na ang kamalayan ng tao ay kayang ipakita ang mundo sa paligid sa anyo ng dalawang signal system. Ang unang signal system ay nakikita ang mundo sa paligid sa pamamagitan ng mga pandama. Bilang resulta ng pagkakalantad sa isa sa mga organo ng pandama (paningin, pandinig, hawakan, amoy, panlasa), isang sensasyon ang lumitaw. Batay sa kabuuan ng mga sensasyon na nauugnay sa isang partikular na bagay, ang isang tao ay may holistic na pang-unawa sa bagay na ito. Ang pinaghihinalaang bagay ay maaaring maimbak sa memorya sa anyo ng isang kaukulang representasyon nito nang walang direktang pandama na kontak.
Ang pangalawang sistema ng signal ay nagpapahintulot sa isang tao, na nag-abstract mula sa mga partikular na bagay, na bumuo ng mga pangkalahatang konsepto tungkol sa mundo sa paligid niya. Ang konsepto ay naiiba sa dami nito, iyon ay, ang klase ng mga bagay na pangkalahatan sa konsepto, at ang nilalaman ng konsepto - mga palatandaan ng mga bagay kung saan isinasagawa ang pangkalahatan. Ang mga tao ay nagpapatakbo gamit ang mga konsepto sa proseso ng komunikasyon. Upang gawin ito, ang ilang mga label ay itinalaga sa bawat konsepto - ang kanilang mga pangalan sa anyo ng magkahiwalay na mga salita o (na mas madalas) na mga parirala. At sa iba't ibang wika maaaring gamitin upang sumangguni sa parehong mga konsepto iba't ibang palatandaan(snowdrop - snowdrop, mata - aso - gabay na aso, vacuum cleaner - vacuum cleaner).
Isinasaalang-alang ang mga nakasaad na prinsipyo, ang sistema ng phraseological machine translation in sa mga pangkalahatang tuntunin tulad ng sumusunod. Tulad ng nabanggit na, ang pinaka-matatag na elemento ng teksto ay ang mga pangalan ng mga konsepto. Sa proseso ng pagsasalin, ang mga pangalan ng mga konsepto ng pinagmulang teksto ay pinalitan ng mga pangalan ng mga yunit ng kahulugan na ito sa target na wika at ang disenyo ng bagong teksto na nakuha ay isinasagawa alinsunod sa mga pamantayan sa gramatika ng target. wika. Tulad ng sa mga sistema ng "Translationmemory", ang prinsipyo ng pagkakatulad ay ginagamit - ang mga salita, parirala at parirala na nagpapakita ng mga tipikal na sitwasyon ay isinalin sa pamamagitan ng pagkakatulad sa mga naunang isinagawa na pagsasalin ng mga yunit na ito. Ang pagkakaiba sa pagitan ng mga ito ay nakasalalay sa katotohanan na sa mga sistema ng uri ng "memorya ng pagsasalin", hindi ganoong matatag na mga segment ng teksto bilang mga konsepto at karaniwang mga sitwasyon ang ginagamit, ngunit ang lahat ng mga pangungusap na matatagpuan sa pinagmulang teksto.
Ito ay sumusunod mula sa itaas na ang mga diksyunaryo ng makina ay ang pinakamahalagang bahagi ng mga sistema ng pagsasalin ng parirala ng makina. Ang bilang ng iba't ibang mga salita sa mga wika tulad ng Russian at Ingles ay lumampas sa isang milyon, at ang bilang ng medyo matatag pariralang parirala may bilang na daan-daang milyon. Ang mga diksyonaryo ng parirala ng gayong dami ay hindi maaaring mabilis na malikha. Kaya, ang dami ng diksyunaryo ng isa sa makabagong sistema Ang "RetransVista" ay 3 milyong 300 libong mga entry sa diksyunaryo.
Ang pag-compile ng mga phraseological na diksyunaryo ng malalaking volume ay mangangailangan ng malaking gastos sa oras, samakatuwid, sa mga machine translation system palagiang kasama magkakaroon ng magkakahiwalay na salita ang mga pariralang parirala. Para sa kanilang pagsasalin, tulad ng nabanggit, ang mga probisyon ng semantic model ay ginagamit, habang ang kalidad ng machine translation ay nagdudulot ng maraming reklamo.
Ito ay tiyak na totoo, ngunit salita-sa-salitang pagsasalin ng mga teksto ay higit na mas mahusay kaysa sa
ang kawalan ng anumang pagsasalin.
Kaya naman, gaya ng pinaniniwalaan ng maraming eksperto sa larangang ito, ang tanging makatwirang pag-asa para sa mga sistema ng pagsasalin ng makina sa ika-21 siglo ay isang kumbinasyon ng pagsasalin ng parirala at salita-by-salitang semantikong pagsasalin. Kasabay nito, ang bahagi ng pagsasalin ng parirala, tila, ay dapat na patuloy na tumaas, at ang bahagi ng pagsasalin ng semantiko ay dapat na patuloy na bumaba.
Gaya ng ipinapakita ng karanasan, ang mga sistema ng pagsasalin ng makina ay dapat na pangunahing nakatuon sa pagsasalin ng mga teksto ng negosyo sa larangan ng agham, teknolohiya, pulitika at ekonomiya. Pagsasalin mga tekstong pampanitikan ay isang mas mahirap na gawain. Ngunit kahit dito, sa hinaharap, ang ilang tagumpay ay maaaring makamit kung mayroong mga mahilig tulad ni Vladimir Dal na, sa tulong ng modernong teknikal na paraan kukuha ng hirap sa pag-iipon ng makapangyarihang mga diksyonaryo ng parirala para sa ganitong uri ng mga teksto.
Karagdagang panitikan.
1. Belonogov G.G. Sa paggamit ng prinsipyo ng pagkakatulad sa awtomatikong pagproseso ng tekstong impormasyon. Sab. "Mga Problema ng Cybernetics", No. 28, 1974.
2. Ubin I.I. Mga modernong tool sa automation ng pagsasalin: pag-asa, pagkabigo at katotohanan. Sab. "Ilipat sa modernong mundo”, M., VCP, 2001, pp. 60-69.
Sa kasalukuyan, mayroong tatlong uri ng machine translation system:
Mga sistemang batay sa mga tuntunin sa gramatika (Rule-Based Machine Translation, RBMT);
Mga sistema ng istatistika (Statistical Machine Translation, SMT);
hybrid system;
Sinusuri ng mga sistemang batay sa gramatika ang teksto na ginagamit sa proseso ng pagsasalin. Ginagawa ang pagsasalin batay sa mga built-in na diksyunaryo para sa isang partikular na pares ng wika, pati na rin ang mga gramatika na sumasaklaw sa semantic, morphological, syntactic pattern ng parehong wika. Batay sa lahat ng data na ito, ang pinagmulang teksto ay sunud-sunod, pangungusap sa pangungusap, na-convert sa teksto sa kinakailangang wika. Ang pangunahing prinsipyo ng pagpapatakbo ng naturang mga sistema ay ang koneksyon sa pagitan ng mga istruktura ng pinagmulan at mga huling teksto.
Ang mga sistemang batay sa mga tuntunin sa gramatika ay kadalasang nahahati sa tatlong higit pang mga subgroup - mga sistema ng pagsasalin ng salita-sa-salita, mga sistema ng paglilipat at mga sistemang interlinguistic.
Ang mga bentahe ng mga system batay sa mga tuntunin sa gramatika ay ang katumpakan ng gramatika at syntactic, katatagan ng resulta, at ang kakayahang mag-adjust sa isang partikular na lugar ng paksa. Kabilang sa mga disadvantage ng mga system na nakabatay sa mga panuntunan sa gramatika ang pangangailangang lumikha, magpanatili at mag-update ng mga database ng linguistic, ang pagiging kumplikado ng paglikha ng naturang sistema, pati na rin ang mataas na halaga nito.
Ang mga sistema ng istatistika sa kanilang trabaho ay gumagamit ng pagsusuri sa istatistika. Ang isang bilingual corpus ng mga teksto ay ini-load sa system (naglalaman ng isang malaking halaga ng teksto sa pinagmulang wika at ang "manual" na pagsasalin nito sa kinakailangang wika), pagkatapos nito ay sinusuri ng system ang mga istatistika ng mga interlingual na sulat, syntactic constructions, atbp. Ang ang sistema ay self-learning - kapag pumipili ng opsyon sa pagsasalin, umaasa ito sa mga nakaraang istatistika. Kung mas malaki ang bokabularyo sa loob ng isang pares ng wika at mas tumpak ito, mas maganda ang resulta ng statistical machine translation. Sa bawat bagong isinaling teksto, bumubuti ang kalidad ng mga kasunod na pagsasalin.
Mabilis na i-set up ang mga statistic system at madaling magdagdag ng mga bagong direksyon sa pagsasalin. Kabilang sa mga pagkukulang, ang pinakamahalaga ay ang pagkakaroon ng maraming pagkakamali sa gramatika at ang kawalang-tatag ng pagsasalin.
Pinagsasama ng mga hybrid system ang mga diskarte na inilarawan kanina. Inaasahan na pagsasamahin ng hybrid machine translation system ang lahat ng mga pakinabang na mayroon ang mga statistical system at rule-based system.
1.3 Pag-uuri ng mga sistema ng pagsasalin ng makina
Ang mga machine translation system ay mga program na gumaganap ng ganap na awtomatikong pagsasalin. Ang pangunahing pamantayan ng programa ay ang kalidad ng pagsasalin. Bilang karagdagan, ang mga mahahalagang punto para sa gumagamit ay ang kaginhawahan ng interface, ang kadalian ng pagsasama ng programa sa iba pang mga tool sa pagproseso ng dokumento, ang pagpili ng mga paksa, at ang utility sa muling pagdadagdag ng diksyunaryo. Sa pagdating ng Internet, ang mga pangunahing machine translation vendor ay nagsama ng mga Web interface sa kanilang mga produkto, habang isinasama rin ang mga ito sa iba pang software at email, na nagpapahintulot sa MT na magamit upang isalin ang mga Web page, email, at online na pag-uusap.
Ang mga bagong miyembro ng forum ng wikang banyaga ng CompuServe ay madalas na nagtatanong kung sinuman ang makakapagrekomenda ng isang mahusay na programa sa pagsasalin ng makina para sa isang makatwirang presyo.
Ang sagot sa tanong na ito ay palaging "hindi". Depende sa sumasagot, ang sagot ay maaaring maglaman ng dalawang pangunahing argumento: alinman na ang mga makina ay hindi maaaring magsalin, o ang machine na pagsasalin ay masyadong mahal.
Pareho sa mga argumentong ito ay may bisa sa isang tiyak na lawak. Gayunpaman, ang sagot ay malayo sa pagiging napakasimple. Kapag pinag-aaralan ang problema ng machine translation (MT), kinakailangang isaalang-alang nang hiwalay ang iba't ibang subsection ng problemang ito. Ang sumusunod na dibisyon ay batay sa mga lektura ni Larry Childs na ibinigay sa 1990 International Conference on Technical Communication:
Ganap na awtomatikong pagsasalin;
Automated machine translation na may partisipasyon ng tao;
Pagsasalin na isinagawa ng isang tao gamit ang isang computer.
Ganap na awtomatikong pagsasalin ng makina. Ang ganitong uri ng machine translation ang ibig sabihin ng karamihan sa mga tao kapag pinag-uusapan nila ang machine translation. Ang kahulugan dito ay simple: ang teksto sa isang wika ay ipinasok sa computer, ang tekstong ito ay pinoproseso at ang computer ay naglalabas ng parehong teksto sa ibang wika. Sa kasamaang palad, ang pagpapatupad ng ganitong uri ng awtomatikong pagsasalin ay nahaharap sa ilang mga hadlang na hindi pa nalalampasan.
Ang pangunahing problema ay ang pagiging kumplikado ng wika mismo. Kunin, halimbawa, ang mga kahulugan ng salitang "maaari". Bilang karagdagan sa pangunahing kahulugan ng modal auxiliary verb, ang salitang "maaari" ay may ilang mga opisyal at balbal na kahulugan bilang isang pangngalan: "bangko", "latrine", "kulungan". Bilang karagdagan, mayroong isang archaic na kahulugan ng salitang ito - "upang malaman o maunawaan." Ipagpalagay na ang target na wika ay may isang hiwalay na salita para sa bawat isa sa mga halagang ito, paano matukoy ng isang computer ang mga ito?
Sa lumalabas, ilang pag-unlad ang nagawa sa pagbuo ng mga programa sa pagsasalin na nagdidiskrimina ng kahulugan batay sa konteksto. Ang mga kamakailang pag-aaral sa pagsusuri ng mga teksto ay higit na umaasa sa teorya ng posibilidad. Gayunpaman, ang ganap na awtomatikong pagsasalin ng makina ng mga teksto na may malawak na paksa ay imposible pa ring gawain.
Automated machine translation na may partisipasyon ng tao. Ang ganitong uri ng pagsasalin ng makina ay medyo magagawa na ngayon. Sa pagsasalita tungkol sa pagsasalin ng makina na may partisipasyon ng isang tao, karaniwan nilang ibig sabihin ay pag-edit ng mga teksto bago at pagkatapos na maproseso ng isang computer. Ang mga tagapagsalin ng tao ay nagbabago ng mga teksto upang sila ay maunawaan ng mga makina. Matapos magawa ng computer ang pagsasalin, muling ine-edit ng mga tao ang magaspang na pagsasalin ng makina, na ginagawang tama ang teksto sa target na wika. Bilang karagdagan sa ganitong pagkakasunud-sunod ng trabaho, may mga MT system na nangangailangan ng patuloy na presensya ng isang taong tagapagsalin sa panahon ng pagsasalin upang matulungan ang computer na magsalin lalo na ang mga kumplikado o hindi maliwanag na istruktura.
Ang pagsasalin ng makina na tinulungan ng tao ay naaangkop sa mas malawak na lawak sa mga tekstong may limitadong bokabularyo ng limitadong limitadong mga paksa.
Ang ekonomiya ng paggamit ng human-assisted machine translation ay pinagtatalunan pa rin. Ang mga programa mismo ay karaniwang medyo mahal, at ang ilan sa mga ito ay nangangailangan ng espesyal na kagamitan upang gumana. Kailangang matutunan ang pre at post editing, at hindi ito isang magandang trabaho. Ang paglikha at pagpapanatili ng mga database ng mga salita ay isang matrabahong proseso at kadalasan ay nangangailangan ng mga espesyal na kasanayan. Gayunpaman, para sa isang organisasyong nagsasalin ng malalaking volume ng mga teksto sa isang mahusay na tinukoy na lugar ng paksa, ang pagsasalin ng makina na tinulungan ng tao ay maaaring maging isang medyo matipid na alternatibo sa tradisyonal na pagsasalin ng tao.
Pagsasalin na isinagawa ng isang tao gamit ang isang computer. Sa pamamaraang ito, ang tagapagsalin ng tao ay inilalagay sa gitna ng proseso ng pagsasalin, habang ang computer program ay itinuturing na isang tool na ginagawang mas mahusay ang proseso ng pagsasalin at tumpak ang pagsasalin. Ito ay mga kumbensyonal na elektronikong diksyonaryo na nagbibigay ng pagsasalin ng kinakailangang salita, na iniiwan ang taong responsable para sa pagpili. gustong opsyon at ang kahulugan ng isinalin na teksto. Ang ganitong mga diksyunaryo ay lubos na nagpapadali sa proseso ng pagsasalin, ngunit nangangailangan ng gumagamit na magkaroon ng isang tiyak na kaalaman sa wika at gumugol ng oras sa pagpapatupad nito. Gayunpaman, ang proseso ng pagsasalin mismo ay lubos na pinabilis at pinadali.
Sa mga sistemang tumutulong sa tagapagsalin sa kanyang gawain, ang pinakamahalagang lugar ay inookupahan ng tinatawag na Translation Memory (TM) system. Ang mga TM system ay isang interactive na tool para sa pag-iipon ng mga pares ng katumbas na mga segment ng teksto sa orihinal na wika at pagsasalin sa isang database na may posibilidad ng kanilang kasunod na paghahanap at pag-edit. Ang mga produktong ito ng software ay hindi nilayon na gumamit ng napakatalino na mga teknolohiya ng impormasyon, ngunit, sa kabaligtaran, ay batay sa paggamit ng potensyal na malikhain ng tagasalin. Sa proseso ng trabaho, ang tagasalin mismo ang bumubuo ng database (o natatanggap ito mula sa iba pang mga tagasalin o mula sa customer), at ang mas maraming mga yunit na nilalaman nito, mas malaki ang pagbabalik mula sa paggamit nito.
Narito ang isang listahan ng mga pinakasikat na sistema ng TM:
Transit Swiss kumpanya Star,
Trados (USA),
Tagapamahala ng Pagsasalin mula sa IBM,
Eurolang Optimizer ng kumpanyang Pranses na LANT,
DejaVu mula sa ATRIL (USA),
WordFisher (Hungary).
Ginagawang posible ng mga system ng TM na ibukod ang paulit-ulit na pagsasalin ng magkaparehong mga fragment ng teksto. Ang pagsasalin ng isang segment ay isasagawa lamang ng tagasalin, at pagkatapos ay ang bawat kasunod na segment ay susuriin para sa isang tugma (buo o malabo) sa database, at kung ang isang kapareho o katulad na segment ay natagpuan, pagkatapos ito ay inaalok bilang isang pagsasalin opsyon.
Sa kasalukuyan, ang mga pagpapaunlad ay isinasagawa upang mapabuti ang mga sistema ng TM. Halimbawa, ang core ng Star's Transit system ay batay sa neural network technology.
Sa kabila ng malawak na hanay ng mga sistema ng TM, nagbabahagi sila ng ilang karaniwang tampok:
Pag-andar ng pagkakahanay. Ang isa sa mga bentahe ng mga sistema ng TM ay ang kakayahang gumamit ng mga naisalin nang materyal sa paksang ito. Ang database ng TM ay maaaring makuha sa pamamagitan ng paghahambing ng segment-by-segment ng orihinal at mga file ng pagsasalin.
Availability ng mga filter ng import-export. Tinitiyak ng property na ito ang compatibility ng TM system na may iba't ibang word processor at publishing system at binibigyan ang tagasalin ng relatibong kalayaan mula sa customer.
Mekanismo para sa paghahanap ng malabo o kumpletong mga tugma. Ito ang mekanismong ito na kumakatawan sa pangunahing bentahe ng mga sistema ng TM. Kung, kapag nagsasalin ng isang text, ang system ay nakatagpo ng isang segment na kapareho o malapit sa naunang isinalin, kung gayon ang na-translate na segment ay iaalok sa tagasalin bilang isang variant ng pagsasalin ng kasalukuyang segment, na maaaring itama. Ang antas ng fuzzy na pagtutugma ay itinakda ng user.
Suporta para sa mga pampakay na diksyunaryo. Ang tampok na ito ay tumutulong sa tagasalin na manatili sa glossary. Bilang isang tuntunin, kung ang isang isinaling segment ay naglalaman ng isang salita o parirala mula sa isang pampakay na diksyunaryo, ito ay naka-highlight sa kulay at ang pagsasalin nito ay inaalok, na maaaring awtomatikong maipasok sa isinalin na teksto.
Paraan ng paghahanap ng mga fragment ng teksto. Napakadaling gamitin ng tool na ito kapag nag-e-edit ng pagsasalin. Kung higit sa magandang opsyon pagsasalin ng anumang fragment ng teksto, pagkatapos ang fragment na ito ay makikita sa lahat ng mga segment ng TM, pagkatapos nito ang mga kinakailangang pagbabago ay sunud-sunod na ginawa sa mga segment ng TM.
Siyempre, tulad ng anumang produkto ng software, ang mga sistema ng TM ay may kanilang mga pakinabang at disadvantages, at ang kanilang saklaw. Gayunpaman, tungkol sa mga sistema ng TM, ang pangunahing kawalan ay ang kanilang mataas na gastos.
Ito ay lalong maginhawang gumamit ng mga TM system kapag nagsasalin ng mga dokumento tulad ng mga manwal ng gumagamit, mga tagubilin sa pagpapatakbo, disenyo at dokumentasyon ng negosyo, mga katalogo ng produkto at iba pang mga dokumento ng parehong uri na may malaking bilang ng mga tugma.