Mogućnosti upotrebe mašinskog prevođenja u radu prevodioca u stručnoj oblasti. Tema: Mašinsko prevođenje PROMT sistem mašinskog prevođenja
Pročitajte također
Predavanje br. 8 Tema: Svrha sistema za mašinsko prevođenje.
Svrha mašinskog prevođenja
Mašinsko prevođenje (MT) ili automatsko prevođenje (AT) je oblast koja se intenzivno razvija naučno istraživanje, eksperimentalni razvoj i već funkcionalni sistemi (SMP), u kojima je kompjuter uključen u proces prevođenja s jednog prirodnog jezika (NL) na drugi. SMT otvara brz i sistematičan pristup informacijama na stranom jeziku, obezbjeđuje efikasnost i ujednačenost u prevođenju velikih tokova tekstova, uglavnom naučnih i tehničkih. SMP-ovi koji rade na industrijskom nivou oslanjaju se na velike terminološke baze podataka i obično zahtijevaju uključivanje čovjeka kao urednika prije, među ili poslije urednika. Savremeni SMP, posebno oni koji se zasnivaju na bazama znanja u određenoj predmetnoj oblasti, klasifikuju se kao sistemi umjetna inteligencija(AI).
Glavna područja upotrebe MC-a
1. U granskim informacionim službama u prisustvu velikog niza ili stalnog toka izvora na stranom jeziku. Ako se SMP-ovi koriste za izlaz signalnih informacija, naknadno uređivanje nije potrebno.
2. U velikom međunarodne organizacije baveći se višejezičnim politematskim nizom dokumenata. To su uslovi rada u Komisiji Evropskih zajednica u Briselu, gde sva dokumentacija mora da se pojavi istovremeno na devet radnih jezika. Pošto su ovdje zahtjevi za prijevodom visoki, MT je potrebno naknadno uređivanje.
3. U prevodilačkim uslugama tehnička dokumentacija pratećih izvezenih proizvoda. Prevodioci se ne mogu nositi sa obimnom dokumentacijom u potrebnom vremenskom okviru (na primjer, specifikacije za avione i druge složene objekte mogu zauzeti do 10.000 ili više stranica). Struktura i jezik tehničke dokumentacije je prilično standardan, što olakšava MT i čak ga čini poželjnijim od ručnog prevođenja, jer garantuje jedinstven stil.
cijeli niz. Budući da prijevod specifikacija mora biti potpun i tačan, MT proizvodi moraju biti naknadno uređivani.
4. Za simultano ili skoro simultano prevođenje nekog stalnog toka poruka istog tipa. Takav je tok vremenskih izvještaja u Kanadi, koji bi se trebali pojaviti istovremeno na engleskom i francuskom jeziku.
Pored praktične potrebe poslovnog svijeta za SMP-om, postoje i čisto naučni poticaji za razvoj MT-a: stabilni eksperimentalni MT sistemi su eksperimentalno polje da se testiraju različiti aspekti opšte teorije razumevanja, govorne komunikacije, transformacije informacija, kao i da se kreiraju novi, efikasniji modeli samog MT.
Sa stanovišta obima i stepena razvoja, NSR se može podijeliti u tri glavne klase: industrijski, razvojni i eksperimentalni.
Jezička podrška sistema mašinskog prevođenja
MT proces je niz transformacija koje se primjenjuju na ulazni tekst i pretvaraju ga u tekst na izlaznom jeziku, koji bi trebao maksimalno rekreirati značenje i, po pravilu, strukturu izvornog teksta, ali pomoću izlaznog jezika . Jezička podrška SMP-a uključuje čitav kompleks pravilnog jezičkog, metajezičkog i takozvanog „ekstralingvističkog“ znanja koji se koristi u takvoj transformaciji.
U klasičnom SMP-u, koji obavlja indirektno prevođenje pojedinačnih rečenica (prevođenje fraza po frazu), svaka rečenica prolazi kroz niz transformacija koji se sastoji od tri dijela (faze): analiza -> prijenos (međujezične operacije) -> sinteza. Zauzvrat, svaka od ovih faza je dovoljna složen sistem međutransformacije.
Cilj faze analize je da se izgradi strukturalni opis (srednja reprezentacija, interna reprezentacija) ulazne rečenice, | Zadatak faze prijenosa (stvarnog prijevoda) je transformacija strukture ulazne rečenice u unutrašnju strukturu izlazne rečenice. Ova faza uključuje i zamjenu leksema ulaznog jezika njihovim prevodnim ekvivalentima (leksičke međujezičke transformacije). Cilj faze sinteze je izgraditi ispravnu rečenicu u izlaznom jeziku na osnovu strukture dobijene kao rezultat analize.
Jezička podrška standardnog modernog NSR uključuje:
1) rečnici;
2) gramatika;
3) formalizovane međupredstave jedinica analize za različite faze transformacije.
Pored standardnih, u pojedinačnim SMP-ovima mogu biti prisutne i neke nestandardne komponente. Stoga se stručno znanje o softveru može specificirati korištenjem posebnih konceptualnih mreža, a ne u obliku rječnika i gramatika.
Mehanizmi (algoritmi, procedure) za rad sa postojećim rječnicima, gramatikama i strukturnim prikazima se nazivaju matematička i algoritamska podrška SMP-a.
Jedan od neophodne zahtjeve do moderne SMP-visoke modularnosti. Sa lingvistički smislene tačke gledišta, to znači da se analiza i procesi koji je prate grade uzimajući u obzir teoriju lingvističkih nivoa. U praksi kreiranja SMP-a razlikuju se sljedeći nivoi analize:
Predsintaksička analiza (obuhvata morfološku analizu - MorfAn, analizu fraza, neidentifikovanih elemenata teksta itd.);
Sintaksička analiza SinAn (gradi sintaksičku reprezentaciju rečenice, ili SinP); unutar njegovih granica može se izdvojiti više podnivoa koji pružaju analizu različitih tipova sintaksičkih jedinica;
Semantička analiza SemAn, ili logičko-semantička analiza (izgrađuje argument-predikatnu strukturu iskaza ili drugu vrstu semantičke
prezentacija rečenica i teksta);
Konceptualna analiza (analiza u smislu konceptualnih struktura koje odražavaju semantiku softvera). Ovaj nivo analize se koristi u SMP-ovima koji ciljaju na vrlo ograničen softver. U stvari, konceptualna struktura je projekcija softverskih šema na jezičke strukture, često ne čak ni semantičke, već sintaktičke. Samo za vrlo uski softver i ograničene klase tekstova konceptualna struktura se poklapa sa semantičkom; u opštem slučaju, ne bi trebalo da postoji potpuno podudaranje, pošto je tekst detaljniji od bilo kog
konceptualni dijagrami.
Sinteza teoretski prolazi kroz iste nivoe kao i analiza, ali u suprotnom smjeru. U radnim sistemima obično se implementira samo put od SynP-a do lanca riječi izlazne rečenice.
Jezička distinkcija između različitih nivoa može se očitovati i u razlikovanju formalnih sredstava koja se koriste u odgovarajućim opisima (skup ovih sredstava je specificiran za svaki nivo posebno). U praksi se jezička sredstva MorphAn često specificiraju odvojeno, a sredstva SinAn i SemAn se kombinuju. Ali diferencijacija nivoa može ostati smislena samo ako koriste jedan formalizam u svojim opisima koji je prikladan za predstavljanje informacija na svim istaknutim nivoima.
Sa tehničke tačke gledišta, modularnost lingvističke podrške znači odvajanje strukturne reprezentacije fraza i tekstova (kao trenutnog, privremenog znanja o tekstu) od "trajnog" znanja o jeziku, kao i znanja jezika od znanja softvera; odvajanje rečnika od gramatika, gramatika od algoritama za njihovu obradu, algoritama od programa. Specifični odnosi različitih modula sistema (gramatički rječnici, gramatike - algoritmi, algoritmi - programi, deklarativno - proceduralna znanja, itd.), uključujući distribuciju lingvističkih podataka po nivoima, glavna je stvar koja određuje specifičnosti sistema. SMP.
Rječnici. Analitički rječnici su obično jednojezični. Moraju sadržavati sve informacije potrebne za uključivanje date leksičke jedinice (LE) u strukturni prikaz. Često razdvajaju rječnike osnova (sa morfološkim i sintaksičkim informacijama: dio govora, tip fleksije, podklasu koja karakterizira sintaksičko ponašanje LU, itd.) i rječnike značenja riječi koji sadrže semantičke i konceptualne informacije: semantička klasa LU, semantičke nade ( valencije), uslovljava njihovu implementaciju u frazi itd.
U mnogim sistemima rječnici opšteg i terminološkog rječnika su razdvojeni. Takva podjela omogućava da se pri prelasku na tekstove druge predmetne oblasti ograniči samo promjenom terminoloških rječnika. Rečnici složenih jedinica (okretanja, strukture) obično formiraju poseban niz, a rečničke informacije u njima ukazuju na način na koji se takva jedinica „prikuplja” tokom analize. Dio informacija iz rječnika može se specificirati u proceduralnom obliku, na primjer, polisemantičke riječi mogu biti povezane s algoritmima za rješavanje odgovarajućeg tipa dvosmislenosti. Nove vrste organizacije vokabularnih informacija za potrebe MT-a nude takozvane "leksičke baze znanja". Prisustvo heterogenih informacija o riječi (nazvanih leksičkim univerzumom riječi) približava takav rječnik enciklopediji nego tradicionalnim lingvističkim rječnicima.
Gramatike i algoritmi. Gramatika i vokabular definiraju lingvistički model, čineći najveći dio lingvističkih podataka. Algoritmi za njihovu obradu, odnosno korelacije sa tekstualnim jedinicama, nazivaju se matematičkom i algoritamskom podrškom sistema.
Razdvajanje gramatika i algoritama je važno u praktičnom smislu jer vam omogućava da promijenite gramatička pravila bez promjene algoritama (i, shodno tome, programa) koji rade s gramatikama. Ali takvo razdvajanje nije uvijek moguće. Dakle, za sistem sa proceduralnim specifikacijama gramatike, a još više sa proceduralnim predstavljanjem rečničkih informacija, takva podela je irelevantna. Algoritmi odlučivanja u slučaju nedovoljnih (nepotpunost ulaznih podataka) ili suvišnih (varijanta analize) informacija su više empirijski, njihova formulacija zahtijeva lingvističku intuiciju. Postavljanje zajedničkog algoritma upravljanja koji kontroliše redosled pozivanja različitih gramatika (ako ih ima više u jednom sistemu) takođe zahteva lingvističko opravdanje. Međutim, trenutni trend je da se gramatike odvoje od algoritama tako da se sve lingvistički značajne informacije daju u statičkom obliku gramatika, te da se algoritmi učine toliko apstraktnim da mogu pozivati i obraditi različite lingvističke modele.
Razdvajanje gramatika i algoritama je najjasnije uočeno u sistemima koji rade sa gramatikama bez konteksta (CSG), gde je jezički model gramatika sa konačnim brojem stanja, a algoritam mora da obezbedi za proizvoljnu rečenicu stablo derivacije prema gramatička pravila, a ako postoji nekoliko takvih izvedenica, onda ih navedite. Takav algoritam, koji je formalni (u matematičkom smislu) sistem, naziva se analizator. Opis gramatike služi za analizator, koji ima univerzalnost, isti ulaz kao i analizirana rečenica. Parseri su napravljeni za klase gramatike, iako uzimanje u obzir specifičnih karakteristika gramatike može povećati efikasnost parsera.
Gramatike sintaksičkog nivoa su najrazvijeniji dio kako sa stanovišta lingvistike, tako i sa stanovišta njihovog obezbjeđenja formalizmima.
Glavne vrste gramatika i algoritama koji ih implementiraju:
Lančana gramatika fiksira redoslijed elemenata, tj. linearne strukture rečenica, specificirajući ih u smislu gramatičkih klasa riječi (član + imenica + prijedlog) ili u smislu funkcionalnih elemenata (subjekt + predikat);
Gramatika konstituenata (ili gramatika direktnih konstituenata - NSG) obuhvata lingvističke informacije o grupisanju gramatičkih elemenata, na primjer, imenički izraz (sastoji se od imenice, člana,
pridev i drugi modifikatori), predloška grupa (sastoji se od predloga i imeničke fraze) itd. do nivoa rečenice. Gramatika je konstruisana kao skup pravila zamene, ili račun produkcija oblika A->B...C. NSG
su gramatike generativnog tipa i mogu se koristiti i u analizi iu sintezi: jezičke rečenice se generišu ponovljenom primjenom takvih pravila;
Gramatika zavisnosti (GZ) definira hijerarhiju odnosa između elemenata rečenice (glavna riječ određuje oblik zavisnih). Analizator u GZ zasniva se na identifikaciji gospodara i njihovih zavisnih (sluga). Glavna stvar u rečenici je glagol u ličnom obliku, jer on određuje broj i prirodu zavisnih imenica. Strategija analize u GC-u je odozgo prema dolje: prvo se identificiraju gospodari, zatim sluge, ili odozdo prema gore: gospodari se identifikuju procesom zamjene;
Bar-Hillelova kategorička gramatika je verzija gramatike konstituenata, ima samo dvije kategorije - rečenice S i ime n. Ostale su definirane u smislu mogućnosti kombinovanja sa ovim glavnim u strukturi NN. Dakle, prelazni glagol je definiran kao n\S, budući da je u kombinaciji s imenom i lijevo od njega, formirajući S rečenicu.
Postoji mnogo načina da se uzmu u obzir kontekstualni uslovi: gramatike metamorfoze i njihove varijante. Sve su one proširenja CF-pravila. Uopšteno govoreći, ovo znači da se pravila proizvodnje prepisuju na sljedeći način: A [a]-> B[b], ..., C [c], gdje su uvjeti, testovi, upute itd., proširujući originalna kruta pravila i davanje gramatičke fleksibilnosti i efikasnosti.
U gramatiku generalizovanih komponenti-TCS uvode se meta-pravila, koja su generalizacija pravilnosti pravila CS1.
Gramatike proširenih tranzicionih mreža-CPN pružaju testove i uslove za lukove, kao i instrukcije koje se moraju izvršiti ako analiza ide duž ovog luka. U različitim modifikacijama CPN-a, težine se mogu dodijeliti lukovima, a zatim analizator može izabrati putanju s najvećom težinom. Uvjeti se mogu podijeliti u dva dijela: bez konteksta i kontekstualno osjetljivi.
Različiti RSPG su kaskadni RSPG. Kaskada je RSP opremljen akcijom 1shshsh1. Ova radnja uzrokuje zaustavljanje procesa u ovoj kaskadi, pohranjivanje informacija o trenutnoj konfiguraciji na stogu i skok na dublju kaskadu i vraćanje u prvobitno stanje. CPN ima niz karakteristika transformacionih gramatika. Može se koristiti i kao sistem za proizvodnju.
Metoda analize pomoću sheme grafa omogućava vam da sačuvate djelomične rezultate i predstavite opcije analize.
Nova i odmah popularna metoda gramatičkog opisa je leksšo-funkcionalna gramatika (LFG). To eliminira potrebu za transformacijskim pravilima. Iako je LFG baziran na QSG-u, uvjeti ispitivanja u njemu su odvojeni od pravila zamjene i "riješeni" su kao autonomne jednačine.
Gramatike objedinjavanja (UG) predstavljaju sljedeću fazu generalizacije modela analize nakon grafskih šema: one su u stanju da utjelovljuju gramatike razne vrste. CG sadrži četiri komponente: paket za objedinjavanje, tumač za pravila i leksičke opise, programe za obradu usmjerenih grafova i analizator koji koristi shemu grafa. CG kombinuju gramatička pravila s opisima rječnika, sintaktičke valencije sa semantičkim.
Centralni problem svakog sistema analize NL je problem izbora opcija. Da bi se to riješilo, gramatike sintaksičkog nivoa dopunjuju se pomoćnim gramatikama i metodama za raščlanjivanje složenih situacija. NN gramatike koriste filterske i heurističke metode. Metoda filtriranja je da se prvo primaju sve varijante analize rečenice, a zatim se odbacuju one koje ne zadovoljavaju određeni sistem filterskih uslova. Heuristički metod od samog početka gradi samo dio opcija koje su vjerodostojnije u smislu datih kriterija. Upotreba pondera za odabir opcija je primjer upotrebe heurističkih metoda u analizi.
Semantički nivo je mnogo manje opremljen teorijom i praktičnim razvojem. Tradicionalni zadatak semantike je otklanjanje dvosmislenosti sintaktičke analize – strukturalne i leksičke. Za to se koristi aparat selektivnih ograničenja, koji je vezan za okvir rečenica, odnosno uklapa se u sintaktički model. Najčešći tip SemAn baziran je na takozvanim gramatikama padeža. Gramatika se zasniva na konceptu dubokog ili semantičkog padeža. Padežni okvir glagola je proširenje koncepta valencije: to je skup semantičkih odnosa koji (obavezni ili neobavezni) mogu pratiti glagol i njegove varijacije u tekstu. Unutar istog jezika, isti duboki padež se ostvaruje različitim površnim predloško-padežnim oblicima. Duboki padeži vam u principu omogućavaju da se ide dalje od rečenice, a ulazak u tekst znači prijelaz na semantičku razinu analize.
Budući da su semantičke informacije, za razliku od sintaksičkih informacija zasnovanih prvenstveno na gramatikama, koncentrisane uglavnom u rečnicima, gramatike su se intenzivno razvijale 1980-ih, omogućavajući „leksikalizaciju“ CSG-a. U toku je razvoj gramatike zasnovane na proučavanju svojstava diskursa.
Govore: Irina Rybnikova i Anastasia Ponomarjova.
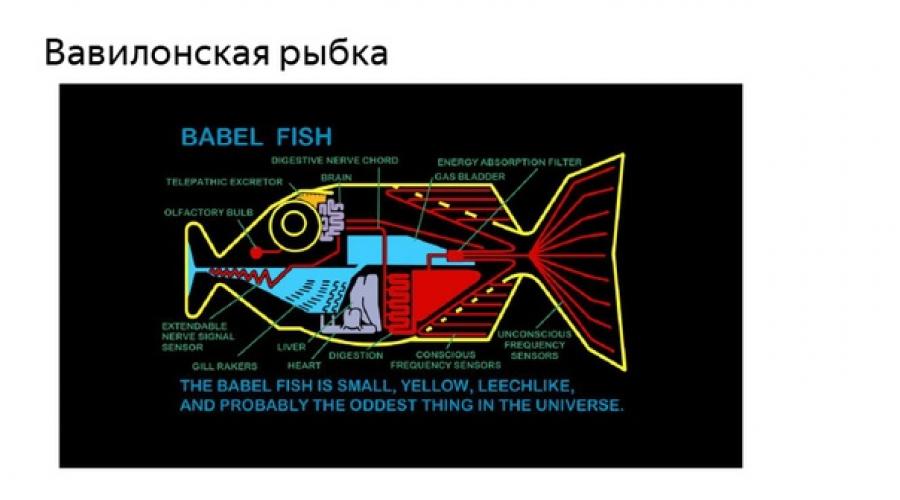
Pričaćemo o istoriji mašinskog prevođenja i kako ga koristimo u Yandexu.
Još u 17. veku naučnici su spekulisali o postojanju neke vrste jezika koji povezuje druge jezike, a to je verovatno davno. Vratimo se bliže. Svi želimo da razumemo ljude oko sebe – gde god da dođemo – želimo da vidimo šta piše na natpisima, želimo da čitamo najave, informacije o koncertima. Ideja o babilonskoj ribi preorava umove naučnika, nalazi se u literaturi, bioskopu - svuda. Želimo smanjiti vrijeme koje nam je potrebno za pristup informacijama. Želimo čitati članke o kineskoj tehnologiji, razumjeti sve stranice koje vidimo i želimo ih primati ovdje i sada.

U kontekstu ovoga, nemoguće je ne govoriti o mašinskom prevođenju. To je ono što pomaže u rješavanju ovog problema.

Polaskom se smatra 1954. godina, kada je u SAD na IBM 701 mašini prevedeno 60 rečenica opštih tema. organska hemija sa ruskog na engleski, a sve se to zasnivalo na 250 pojmova pojmovnika i šest gramatičkih pravila. Zvao se Džordžtaunski eksperiment i toliko je šokirao stvarnost da su novine bile pune naslova da bi još tri do pet godina, i problem bi bio potpuno rešen, svi bi bili srećni. Ali kao što znate, stvari su išle malo drugačije.
Mašinsko prevođenje zasnovano na pravilima pojavilo se 1970-ih. Također se zasnivao na dvojezičnim rječnicima, ali i na samim skupovima pravila koja su pomagala opisati bilo koji jezik. Bilo koji, ali sa ograničenjima.

Ozbiljni stručnjaci lingvisti morali su da zapišu pravila. Ovo je prilično težak posao, još uvijek nije mogao uzeti u obzir kontekst, u potpunosti pokriti bilo koji jezik, ali oni su bili stručnjaci, a velika računarska snaga tada nije bila potrebna.

Govoreći o kvalitetu, klasičan primjer- citat iz Biblije, koji je tada preveden ovako. Još nije dovoljno. Stoga su ljudi nastavili raditi na kvaliteti. Devedesetih godina pojavio se statistički model prevođenja, SMT, koji je govorio o probabilističkoj distribuciji riječi, rečenica, a ovaj sistem je bio fundamentalno drugačiji po tome što nije znao ništa o pravilima i o lingvistici. Dobila je ogroman broj identičnih tekstova kao ulaz, uparenih na jednom i drugom jeziku, a onda je sama donosila odluke. Bio je lak za održavanje, nije mu bila potrebna gomila stručnjaka, nije trebalo čekati. Bilo je moguće preuzeti i dobiti rezultat.

Zahtjevi za ulaznim podacima bili su prilično prosječni, od 1 do 10 miliona segmenata. Segmenti - rečenice, male fraze. Ali bilo je nekih poteškoća i kontekst nije uzet u obzir, nije sve bilo lako. I u Rusiji je, na primjer, bilo takvih slučajeva.

Sviđa mi se i primjer prijevoda GTA igrica, rezultat je bio odličan. Sve nije bilo na svom mestu. Prilično važna prekretnica bila je 2016., kada je pokrenuto neuronsko mašinsko prevođenje. Bio je to prilično epohalni događaj koji je uvelike preokrenuo život. Moj kolega je, nakon što je pogledao prevode i način na koji ih koristimo, rekao: „Kul, on govori mojim rečima“. I bilo je stvarno sjajno.
Koje su karakteristike? Visoki zahtjevi na ulazu, materijal za obuku. Interno, teško ga je održavati, ali značajno povećanje kvaliteta je ono zbog čega je započeto. Samo kvalitetan prevod će rešiti postavljene zadatke i olakšati život svim učesnicima u procesu, onim prevodiocima koji ne žele da isprave loš prevod, žele da rade nove kreativne zadatke, a mašini daju rutinske šablonske fraze .
Unutar mašinskog prevođenja postoje dva pristupa. Stručni pregled/ lingvistička analiza tekstova, odnosno provjera od strane stvarnih lingvista, stručnjaka za usklađenost sa značenjem, pismenost jezika. U pojedinim slučajevima i vještaci su zatvarani, dozvoljeno im je da lektorišu prevedeni tekst i ocjenjuju koliko je to djelotvorno sa ove tačke gledišta.

Koje su karakteristike ove metode? Uzorak prijevoda nije potreban, sada gledamo gotov prevedeni tekst i objektivno ga procjenjujemo u bilo kojem aspektu. Ali to je skupo i dugotrajno.

Postoji drugi pristup - automatska referentna metrika. Ima ih mnogo, svaki sa svojim prednostima i nedostacima. Neću ići duboko, o ovim ključnim riječima možete detaljnije pročitati kasnije.
Koja je karakteristika? U stvari, ovo je poređenje prevedenih mašinskih tekstova sa nekom vrstom primernog prevoda. Ovo su kvantitativne metrike koje pokazuju nesklad između uzornog prijevoda i onoga što se dogodilo. To je brzo, jeftino i može se obaviti prilično povoljno. Ali postoje karakteristike.

Zapravo, sada se najčešće koriste hibridne metode. To je kada se nešto prvo automatski procjenjuje, zatim se analizira matrica grešaka, zatim se na manjem broju tekstova vrši stručna lingvistička analiza.

U posljednje vrijeme i dalje je raširena praksa da tamo ne zovemo lingviste, već jednostavno korisnike. Izrađuje se interfejs - pokažite koji vam se prijevod najviše sviđa. Ili kada odete do online prevodilaca, unesete tekst i često možete glasati za ono što vam se najviše sviđa, bez obzira da li je ovaj pristup prikladan ili ne. Zapravo, svi mi sada treniramo ove motore, i sve što im damo za prevod, oni koriste za obuku i rad na njihovom kvalitetu.
Želio bih da vam kažem kako koristimo mašinsko prevođenje u našem radu. Dajem reč Anastasiji.
Mi u Yandexu u odjelu za lokalizaciju vrlo smo brzo shvatili da su mogućnosti tehnologije strojnog prevođenja velike i odlučili smo pokušati je koristiti u našim svakodnevnim zadacima. Gdje smo počeli? Odlučili smo da napravimo mali eksperiment. Odlučili smo da iste tekstove prevedemo putem konvencionalnog prevodioca neuronske mreže, kao i da sastavimo obučenog mašinskog prevodioca. Da bismo to učinili, pripremili smo korpuse tekstova u rusko-engleskom paru za godine koje mi u Yandexu lokalizujemo tekstove na ove jezike. Onda smo došli sa ovim korpusom tekstova našim kolegama iz Yandex.Translatea i tražili da treniramo motor.

Kada je motor osposobljen, preveli smo sljedeću seriju tekstova i, kako je rekla Irina, procijenili smo rezultate uz pomoć stručnjaka. Zamolili smo prevodioce da pogledaju pismenost, stil, pravopis, prenos značenja. No, prekretnica je bila kada je jedan od prevoditelja rekao da "prepoznajem svoj stil, prepoznajem svoje prijevode".
Kako bismo pojačali ove osjećaje, odlučili smo izračunati statističke pokazatelje. Prvo smo izračunali BLEU koeficijent za transfere napravljene putem konvencionalnog mehanizma neuronske mreže i dobili ovu cifru (0,34). Čini se da to treba uporediti sa nečim. Opet smo otišli kod kolega iz Yandex.Translatea i zamolili ih da nam objasne koji se BLEU koeficijent smatra pragom za prevode koje je napravila stvarna osoba. Ovo je od 0.6.
Tada smo odlučili provjeriti rezultate na obučenim prijevodima. Dobio 0,5. Rezultati su zaista ohrabrujući.

Dajem primjer. Ovo je prava ruska fraza iz dokumentacije Yandex.Directa. Zatim je to prevedeno kroz obični motor neuronske mreže, a zatim kroz obučeni motor neuronske mreže na naše tekstove. Već u prvom redu primjećujemo da tradicionalni tip oglašavanja za Yandex.Direct nije prepoznat. I već u obučenom motoru neuronske mreže pojavljuje se naš prijevod, a čak je i skraćenica gotovo tačna.
Bili smo jako uzbuđeni zbog rezultata i odlučili smo da se vjerovatno isplati koristiti mašinski motor u drugim parovima, na drugim tekstovima, ne samo na tom osnovnom kompletu tehničke dokumentacije. Zatim je izvedena serija eksperimenata u trajanju od nekoliko mjeseci. Suočen sa velika količina karakteristike i problemi, to su najčešći problemi koje smo morali rješavati.

Reći ću vam više o svakom.

Ako ćete, kao i mi, napraviti prilagođeni motor, trebat će vam dovoljno veliki broj kvalitetnih paralelnih podataka. Veliki motor se može trenirati na količinu od 10.000 ili više rečenica, u našem slučaju smo pripremili 135.000 paralelnih rečenica.

Neće na svim vrstama teksta vaš motor pokazati jednako dobre rezultate. U tehničkoj dokumentaciji gdje postoje dugačke rečenice, struktura, korisnička dokumentacija, pa čak i u interfejsu gdje postoje kratke, ali nedvosmislene tipke, najvjerovatnije ćete dobro proći. Ali možda ćete, kao i mi, naići na probleme u marketingu.
Proveli smo eksperiment, prevodeći muzičke liste za reprodukciju, i dobili takav primjer.

Evo šta mašinski prevodilac misli o damama iz fabrike zvezda. Šta su bubnjari rada.

Prilikom prevođenja putem strojnog stroja kontekst se ne uzima u obzir. Ovo nije tako smiješan primjer, ali sasvim stvaran, iz tehničke dokumentacije Yandex.Directa. Čini se da je to razumljivo kada čitate tehničku dokumentaciju, to je tehničko. Ali ne, motor mašine nije udario.

Također morate uzeti u obzir da će kvalitet i značenje prijevoda uvelike ovisiti o izvornom jeziku. Prevodimo frazu na francuski sa ruskog, dobijamo jedan rezultat. Dobijamo sličnu frazu sa istim značenjem, ali iz engleskog, i dobijemo drugačiji rezultat.

Ako, kao u našem tekstu, imate veliki broj oznaka, markupa, nekih tehničkih karakteristika, najvjerovatnije ćete morati da ih pratite, uredite i napišete neke skripte.
Evo primjera prave fraze iz pretraživača. U zagradama su tehničke informacije koje ne treba prevoditi, posebno oblici množine. Na engleskom su na engleskom, a na njemačkom bi također trebali ostati na engleskom, ali su prevedeni. Morat ćete pratiti ove trenutke.

Izvorni motor ne zna ništa o vašim konvencijama imenovanja. Na primjer, imamo sporazum koji svuda zovemo Yandex.Disk latinicom na svim jezicima. Ali na francuskom se pretvara u disk na francuskom.

Skraćenice se ponekad prepoznaju ispravno, ponekad ne. U ovom primjeru, BY, koji označava pripadnost bjeloruskim tehničkim zahtjevima za oglašavanje, pretvara se u prijedlog na engleskom.

Jedan od mojih omiljenih primjera su nove i posuđene riječi. Evo odličnog primjera, riječi odricanje od odgovornosti, "iskonski ruski". Terminologija će se morati provjeriti za svaki dio teksta.
I još jedan, više nije tako značajan problem - zastarjeli pravopis.

Ranije je internet bio novitet, u svim tekstovima se pisalo velikim slovom, a kada smo trenirali naš motor, internet je svuda bio velikim slovom. Sada je nova era, internet već piše malim slovom. Ako želite da vaš motor i dalje koristi internet, morat ćete ga ponovo obučiti.

Nismo očajavali, riješili smo ove probleme. Prvo smo promijenili korpuse tekstova, pokušali prevoditi na druge teme. Svoje komentare prenijeli smo kolegama iz Yandex.Translatea, preobučili neuronsku mrežu i pogledali rezultate, procijenili ih i zatražili poboljšanja. Na primjer, prepoznavanje oznaka, obrada HTML oznaka.
pokazaću stvarne opcije koristiti. Dobri smo u mašinskom prevođenju tehničke dokumentacije. Ovo je pravi slučaj.

Evo fraze na engleskom i ruskom. Prevodilac koji se bavio ovom dokumentacijom bio je veoma ohrabren adekvatnim izborom terminologije. Još jedan primjer.

Prevodilac je cijenio izbor je umjesto crtice, što je promijenilo strukturu fraze u engleski, adekvatan izbor termina, koji je tačan, i riječi vi, koje nema u originalu, ali čini ovaj prijevod tačno engleski, prirodno.

Drugi slučaj su prijevodi interfejsa u hodu. Jedan od servisa odlučio je da se ne opterećuje lokalizacijom i prevodi tekstove odmah u trenutku preuzimanja. Ali nakon promjene motora, otprilike jednom mjesečno, riječ "isporuka" se mijenjala u krug. Predložili smo da tim poveže ne konvencionalni motor neuronske mreže, već naš, obučen za tehničku dokumentaciju, tako da se uvijek koristi isti termin, dogovoren sa timom, koji već stoji u dokumentaciji.

Kako sve ovo utiče na novac? Tradicionalno se dogodilo da je u rusko-ukrajinskom paru potrebno minimalno uređivanje ukrajinskog prijevoda. Tako smo prije nekoliko mjeseci odlučili da pređemo na sistem naknadnog uređivanja. Ovako raste naša ekonomija. Septembar još nije gotov, ali procjenjujemo da smo smanjili troškove naknadnog uređivanja za oko trećinu na ukrajinskom jeziku, a uredit ćemo gotovo sve osim marketinških tekstova. Riječ Irini za sumiranje.
Irina:
- Svima postaje jasno da je to neophodno iskoristiti, to je već naša realnost i ne može se isključiti iz naših procesa i interesa. Ali morate razmisliti o nekoliko stvari.

Odlučite se za vrste dokumenata, kontekst sa kojim radite. Je li ova tehnologija prava za vas?
Drugi trenutak. Razgovarali smo o Yandex.Translateu, jer smo tu dobri odnosi, imamo direktan pristup programerima i tako dalje, ali u stvari morate odlučiti koji će od motora biti najoptimalniji za vas konkretno, za vaš jezik, vašu temu. Ova tema će biti u fokusu sljedećeg izvještaja. Budite spremni da još uvijek postoje poteškoće, programeri motora rade zajedno na rješavanju poteškoća, ali za sada se još uvijek susreću.

Željeli bismo razumjeti šta nam se sprema u budućnosti. Ali zapravo, ovo više nije dalje, već naše. sadašnjostšta se dešava ovde i sada. Svima nam je prije potrebno prilagođavanje naše terminologije, naših tekstova, a to je ono što sada postaje javno. Sada svi rade na tome da ne ulazite u kompaniju, ne pregovarate sa programerima određenog motora, kako ga optimizirati za vas. Možete ga dobiti u javnim otvorenim motorima putem API-ja.
Prilagodba ne ide samo na tekstove, već i na terminologiju, na prilagođavanje terminologije za svoje potrebe. Ovo je veoma važna tačka. Druga tema je interaktivno prevođenje. Kada prevodilac prevede tekst, tehnologija mu omogućava da predvidi sljedeće riječi s obzirom na izvorni jezik, izvorni tekst. Ovo može znatno olakšati posao.
O tome šta je sada zaista skupo. Svi razmišljaju kako da treniraju neke motore mnogo efikasnije uz manje količine teksta. To je nešto što se dešava svuda i svuda se lansira. Mislim da je tema veoma interesantna, a dalje će biti još zanimljivija.
Mašinsko prevođenje: kratka istorija
Drugi izvanredni matematičar iz 19. stoljeća, Charles Babbage, pokušao je uvjeriti britansku vladu da je potrebno financirati njegovo istraživanje za razvoj " kompjuter Između ostalih pogodnosti, obećao je da će jednog dana ova mašina moći automatski da prevodi kolokvijalni govor. Međutim, ova ideja je ostala nerealizovana [Chaliapina 1996: 105].
Datumom rođenja mašinskog prevođenja kao istraživačke oblasti obično se smatra mart 1947. Tada je kriptograf Voren Viver, u svom pismu Norbertu Vineru, prvi postavio problem mašinskog prevođenja, upoređujući ga sa problemom dešifrovanja.
Isti Viver je, nakon niza rasprava, 1949. sastavio memorandum u kojem je teorijski potkrijepio fundamentalnu mogućnost stvaranja sistema za mašinsko prevođenje. W. Weaver je napisao: „Imam tekst ispred sebe koji je napisan na ruskom, ali ću se pretvarati da je zaista napisan na engleskom i da je kodiran nekim čudnim simbolima. isključim kod kako bih povratio informacije sadržane u tekstu" ("Imam tekst napisan na ruskom pred očima, ali ću se pretvarati da je zapravo napisan na engleskom i kodiran koristeći prilično čudne znakove. Sve što sam potrebno je razbiti kod da bi se izdvojile informacije sadržane u tekstu") [Slocum 1989: 56-58].
Weaverove ideje činile su osnovu pristupa MT baziranog na konceptu interlingua: Faza prijenosa informacija podijeljena je u dvije faze. U prvoj fazi, izvorna rečenica se prevodi na posrednički jezik (napravljen na bazi pojednostavljenog engleskog), a zatim se rezultat ovog prijevoda predstavlja pomoću ciljnog jezika.
U to vrijeme, nekoliko kompjutera se uglavnom koristilo za rješavanje vojnih problema, pa ne čudi što se u SAD-u glavna pažnja poklanjala rusko-engleskom, a u SSSR-u - englesko-ruskom prijevodu. Do početka 1950-ih, brojne istraživačke grupe borile su se s problemom automatskog prevođenja.
Godine 1952. održana je prva konferencija o MT-u na Tehnološkom institutu u Masačusetsu, a 1954. godine predstavljen je prvi punopravni sistem mašinskog prevođenja - IBM Mark II, koji je razvio IBM zajedno sa Univerzitetom Džordžtaun (ovaj događaj je ušao u istoriju kao Georgetown eksperiment). Sistem, vrlo ograničen u svojim mogućnostima, savršeno je preveo 49 posebno odabranih rečenica sa ruskog na engleski koristeći rječnik od 250 riječi i šest gramatičkih pravila.
Jedan od novih razvoja 1970-ih i 1980-ih bila je TM (translation memory) tehnologija, koja radi na principu akumulacije: tokom procesa prevođenja, originalni segment (rečenica) i njegov prevod se čuvaju, što rezultira formiranjem lingvistička baza podataka; ako se u novoprevedenom tekstu pronađe identičan ili sličan segment, on se prikazuje zajedno s prijevodom i naznakom procentualnog podudaranja. Prevodilac tada donosi odluku (da uredi, odbije ili prihvati prevod), čiji rezultat sistem pohranjuje.
Od početka 1980-ih, kada su personalni računari samouvereno i moćno počeli da osvajaju svet, njihovo radno vreme je pojeftinilo i moglo im se pristupiti u svakom trenutku. MP je postao ekonomski održiv. Osim toga, u ovim i narednim godinama, unapređenje programa omogućilo je prilično precizno prevođenje mnogih vrsta tekstova, ali su neki problemi MT-a ostali neriješeni do danas.
Devedesete se mogu smatrati pravom renesansom u razvoju MT-a, što je povezano ne samo sa visokim nivoom mogućnosti personalnih računara, već i sa širenjem Interneta, što je dovelo do stvarne potražnje za MT-om. Ponovo je postao atraktivno područje za ulaganja, kako za privatne investitore, tako i za državne strukture.
Od ranih 1990-ih, ruski programeri ulaze na tržište PC sistema.
U julu 1990. godine na PC Forumu u Moskvi predstavljen je prvi komercijalni sistem mašinskog prevođenja u Rusiji pod nazivom PROMT (PROgrammer's Machine Translation) PROMT je pobedio na NASA-inom konkursu za nabavku MP sistema (PROMT je bila jedina neamerička kompanija na ovom takmičenju ) [Kulagin 1979: 324].
Što se tiče samih sistema za mašinsko prevođenje, treba napomenuti da su oni prošli kroz tri faze svog razvoja:
- 1. "Elektronski prevodioci" prve generacije - sistemi direktnog prevođenja (NTS)- bili softverski i hardverski kompleksi i analizirali tekst "riječ po riječ" (semantičke veze i nijanse praktički nisu uzete u obzir). Mogućnosti SPP-a određivale su se raspoloživim veličinama rječnika, što je direktno ovisilo o količini računarske memorije. IBM Mark II, koji je omogućio eksperiment Georgetowna, pripadao je kategoriji NGN.
- 2. Vremenom je SPP zamijenjen T-sistemi(od engleskog Transfer - "transformacija"), u kojem je prevođenje izvršeno na nivou sintaksičkih struktura (ovako se jezik uči u srednjoj školi). Izveli su skup operacija koje su omogućile, analizom prevedene fraze, da odrede njenu sintaksičku strukturu prema gramatičkim pravilima ulaznog jezika, a zatim je transformišu u sintaksičku strukturu izlazne rečenice i sintetiziraju novu frazu, zamjenjujući potrebne riječi iz rječnika izlaznog jezika. Rad u ovom pravcu se više ne radi: praksa je pokazala da je stvarni sistem korespondencije složeniji i da adekvatan prevod zahteva suštinski drugačiji algoritam delovanja.
- 3. Nešto kasnije, sve brojniji sistemi mašinskog prevođenja, u zavisnosti od principa njihovog rada, počeli su se deliti na MT-programe(od Machine Translation - "mašinsko prevođenje") i TM-kompleksi(iz Translation Memory - "prijevodna memorija"). Kao zaista uspješan primjer MT programa, nazovimo poznati kanadski sistem METEO, koji prevodi vremensku prognozu sa francuskog na engleski i obrnuto (nastao je prije skoro trideset godina, a radi i danas). Programeri METEO-a su se kladili da je zaista automatizovano mašinsko prevođenje moguće samo pod uslovima veštačkog ograničenja (kao u vokabular i gramatiku) jezika. I bili su uspješni. Najpopularniji profesionalac na svijetu TM-alat je TRADOS Translation "s Workbench paket. Takvi programi se uglavnom koriste profesionalni prevodioci koji su shvatili korist od djelimične automatizacije svog rada uz pomoć kompjutera pri prevođenju tekstova koji se ponavljaju koji su slični po temi i strukturi.
Glavna ideja Translation Memory je da se isti tekst ne prevodi dvaput. Ova tehnologija se zasniva na poređenju dokumenta koji treba prevesti sa podacima pohranjenim u prethodno kreiranoj "ulaznoj" bazi podataka. Kada sistem pronađe fragment koji ispunjava unapred određene kriterijume, onda se njegov prevod preuzima iz "izlazne" baze. Rezultirajući tekst podliježe intenzivnoj ljudskoj naknadnoj montaži [Marchuk 1997: 21-22].
Poglavlje 1 Zaključci
U prvom poglavlju pogledali smo šta je prevod. Izdvojili smo njegove vrste, forme i žanrove. Razmotrili smo i mašinsko prevođenje. Dotaknuvši se teme mašinskog prevođenja, ispitali smo njegovu kratku istoriju, kao i koje mesto zauzima u opšta klasifikacija prevod. Saznali smo kako funkcionira program prevoditelja.
Prvi eksperimenti na mašinskom prevođenju, koji su potvrdili fundamentalnu mogućnost njegove implementacije, izvedeni su 1954. godine na Univerzitetu Džordžtaun (Vašington, SAD). Ubrzo nakon toga počelo je istraživanje i razvoj u industrijaliziranim zemljama svijeta s ciljem stvaranja sistema za mašinsko prevođenje. I iako je od tada prošlo više od pola veka, problem mašinskog prevođenja još uvek nije rešen na odgovarajućem nivou. Pokazalo se da je to mnogo teže nego što su zamišljali pioniri i entuzijasti mašinskog prevođenja kasnih pedesetih i ranih šezdesetih. Stoga, procjenjujući današnju stvarnost, mora se govoriti i o postignućima i o razočarenjima.
Već smo rekli da je, kako bi se mašina naučila da prevodi, kreiran semantički model prijevoda na osnovu "generativne semantike" i trenutnog jezičkog modela "značenje ↔ tekst". Zadatak je bio osigurati elektronski mozak dovoljan broj sinonima, konverza, sintaksičkih izvedenica i semantičkih parametara kojima bi mogao manipulirati u procesu prevođenja. A prijevod se u to vrijeme shvatao samo kao proces zamjene riječi i izraza jednog jezika riječima i frazama drugog jezika.
To je bilo i vrijeme kada su lingvisti koji su radili u oblasti mašinskog prevođenja pokušavali da opišu prirodni jezik koristeći matematičke simbole. Za razliku od Retzkera i Fedorova, koji su nastojali da uspostave postojeće obrasce na osnovu praktičnih zapažanja, oni su kao cilj postavili stvaranje deduktivne teorije. Radilo se o razvoju skupa pravila čija bi primjena na određeni skup jezičnih jedinica mogla dovesti do stvaranja smislenog teksta. Jezičke jedinice ponašali su se kao matematički simboli, koji bi se, kao rezultat primjene na njih gornjih pravila, također matematički izraženih, mogli rasporediti na određeni način. Nakon dekodiranja, kombinacija znakova se pretvorila u tekst.
Naučnici su stvorili poseban jezik, koji se sastoji od matematičkih simbola, koje bi mašina mogla koristiti kao posrednik u prelasku sa izvornog teksta na ciljni tekst. Jezik posrednika je "metalni jezik" teorije prevođenja. U lingvistici se metajezik obično shvata kao „jezik drugog reda“, odnosno jezik na kojem se gradi razmišljanje o prirodnom jeziku ili bilo kojoj drugoj pojavi. Dakle, kada govorimo o gramatici, koristimo posebne riječi, odnosno termine i izraze, a kada govorimo o oblasti medicine koristimo se drugačijim terminološkim aparatom. Drugim riječima, metajezik ili „jezik posrednik“ prijevoda je kompleks strukturalnih i jezičkih karakteristika koje omogućavaju da se proces prevođenja opiše s dovoljnom potpunošću.
Prema namjeri autora teorije mašinskog prevođenja, posrednički jezik se zasnivao na konceptualnom aparatu „generisanje semantike“ i modelu „smisla ↔ tekst“. Pripremljen je skup pravila za transformaciju površinskih struktura engleskog jezika u ključne rečenice. Naučnici su dalje očekivali da će, uz pomoć posredničkog jezika, mašina lako pretvoriti duboke strukture izvornog jezika u duboke strukture ciljnog jezika, a zatim u njegove površinske strukture. Ali dobijeni rezultati nisu bili sasvim zadovoljavajući. Kvaliteta mašinskog prijevoda pokazala se vrlo lošom i kasniji pokušaji da se on poboljša nisu uspjeli. Šta je bio razlog?
Kao što je ranije spomenuto, naučnici u to vrijeme, odnosno početkom pedesetih i sredinom šezdesetih godina prošlog stoljeća, vodili su se lingvističkom teorijom strukturalizma, zasnovanom na opisu i tumačenju jezičkih pojava striktno u okviru unutarjezičkih odnosa. i ne dopuštajući da se u analizi ovih pojava izađe izvan granica jezičke strukture. Oni su sigurno znali ono što svaki praktični prevodilac dobro zna. Naime, važnost uzimanja u obzir specifične situacije u kojoj se odvija ovaj čin međujezične komunikacije, kao i situacije opisane u poruci koja se prevodi. Ova informacija, sa stanovišta kvaliteta prevedenog teksta, nema manju ulogu od stvarnih jezičkih fenomena.
Kako bi se ova okolnost pomirila sa zahtjevom da se ne ide dalje od unutarjezičkih odnosa, predloženo je da se prevodilačka djelatnost podijeli na dvije komponente - sam prevod, koji se obavlja prema datim pravilima bez pribjegavanja ekstralingvističkoj stvarnosti koja se ogleda u iskustvu ili percepciji prevoditelja. prevodilac i tumačenje, uključujući uključivanje ekstralingvističkih podataka.
Ali ovo je očigledno protiv onoga o čemu znamo stvarni procesi konvencionalno, odnosno nemašinsko prevođenje. Za prevođenje koje obavlja osoba karakteristično je organsko i neodvojivo jedinstvo vlastitih jezičkih i ekstralingvističkih faktora. Činjenica je da u bilo kojem govornom djelu nije sve izraženo eksplicitno, ili, kako lingvisti kažu, eksplicitno. Mnogo toga obično ostaje neizraženo, podrazumijevano. Svaka izjava je upućena određenoj osobi ili određenoj publici. Autor izjave polazi od činjenice da njegovi slušaoci ili čitaoci imaju dovoljno znanja da nedvosmisleno protumače ovu ili onu poruku bez pojašnjenja detalja.
Dakle, mašinsko prevođenje, zasnovano samo na analizi formalnih i strukturnih obrazaca izvornog teksta, ne dozvoljava otkrivanje interakcije jezičkih i ekstralingvističkih faktora i na taj način izostavlja najvažniju komponentu međujezične komunikacije. To je bio glavni razlog njegovog nezadovoljavajućeg kvaliteta.
Mnogi istraživači priznaju da ni u današnje vrijeme nije bilo nikakvih pomaka u strojnom prevođenju u implementaciji drugih modela, uprkos činjenici da su se sposobnosti računara višestruko povećale u odnosu na početak rada na mašinskom prevođenju, a nove Pojavili su se programski jezici, mnogo pogodniji za implementaciju programa za kreiranje mašinskog prevođenja. Čitava poenta je, očigledno, u tome da je tumačenje jezičkih znakova u odnosu na ekstralingvističku stvarnost u mnogo čemu intuitivne prirode i da se provodi nesvjesno, ili, kako se kaže, "na subkorteksu", a ono što se radi nesvjesno ne može biti formalizovan i prenesen na mašinu u obliku softvera. Prema tome, mašinsko prevođenje i dalje zahteva čoveka urednika za sobom i služi kao izvor brojnih prevodilačkih šala.
Dakle, jednom kada je mašina zamoljena da prevede na engleski, a zatim odmah nazad na ruski, poslovica „Spolja na vidiku, van pameti“. Konačna verzija je bila: "Nevidljivi idiot". Zašto? Jer odgovarajuća engleska poslovica kaže: "Outofsight-outofmind". Mašina ga je pronašla bez poteškoća. Ali s obrnutim prijevodom ove poslovice na ruski, krenula je pogrešnim putem. Činjenica je da na ruskom postoje direktne korespondencije s obje komponente engleska fraza: Out of sight - prenosi se riječju "nevidljiv", dok engleski outofmind odgovara ruskim riječima "lud, lud, idiot". Mašina je iskoristila ove prepiske. Jednostavno nije pretpostavila da obje navedene komponente engleske fraze ne treba prenositi zasebno, već kao cjelinu. Zbog njenog nedostatka "ljudskog faktora".
Generalno, nivo kvaliteta mašinskog prevođenja čisto informativnih tekstova, ugovora, uputstava, naučnih izveštaja itd. mnogo više od tekstova novinarske prirode. Evo nekoliko primjera:
Plaćanja po ovom ugovoru za opremu navedenu u dodatku 1 ugovora će se izvršiti na sljedeći način.
Plaćanja po ovom ugovoru za opremu navedenu u Dodatku 1 ugovora će se izvršiti na sljedeći način.
Ipak, dosta zamki čeka g. Bush ako pokuša sam.
Ipak, gomilu trapeznih mišića čekaju gospodina Busha ako pokuša da hoda sam.
Tržišta su, s obzirom na više i ranije nego što su imala razloga za očekivati, bila iznenađena.
Tržišta su dala više i ranije nego što su imala razloga za očekivati, dobro iznenađena.
Sve navedeno nam omogućava da zaključimo da su pioniri mašinskog prevođenja i njihovi neposredni nasljednici postigli značajan uspjeh u ovoj oblasti. Ali još uvijek nisu uspjeli riješiti mnoge najvažnije probleme. S tim u vezi, izjava šefa Japana državni program mašinski prevod profesora Makoto Nagao sa Univerziteta Kjoto. U jednom od svojih članaka objavljenih 1982. dao je sljedeću izjavu: „Svaki razvoj sistema za mašinsko prevođenje će na kraju doći u ćorsokak. Naš razvoj će također doći u ćorsokak, ali ćemo se truditi da to bude što je moguće kasnije.”
Iste godine, profesor Nagao je objavio članak u kojem je predložio novi koncept za mašinsko prevođenje. Prema ovom konceptu, testove treba prevoditi po analogiji sa drugim tekstovima koji su prethodno prevedeni ručno, odnosno ne mašinom, već prevodiocem. U tu svrhu treba formirati veliki niz tematski sličnih tekstova i njihovih prijevoda (dvojezičnih) koji će se potom unositi u super-moćni višeprocesorski računar. U procesu prevođenja novih tekstova, iz niza dvojezičnih tekstova potrebno je odabrati analoge fragmenata ovih tekstova koji se mogu koristiti za formiranje konačnog teksta. M.Nagao je svoj pristup mašinskom prevođenju nazvao "Examplebasedtranslation" (prevod zasnovan na primerima), a tradicionalni pristup - "Rulebasedtranslation" (prevod prema pravilima).
Koncept Makoto Nagao odjekuje nedavno široko korištenom konceptu "TranslationMemory" (memorija prijevoda), koji se ponekad naziva "SentenceMemory" (skladištenje rečenica). Suština ovog koncepta je sljedeća. Prilikom pripreme verzija bilo kojeg dokumenta na stranom jeziku (npr. operativnu dokumentaciju za proizvode mašinogradnje) u početku njihov prevod obavljaju ručno visokokvalifikovani prevodioci. Zatim se originalni dokumenti i njihovi prijevodi na strani jezik unose u kompjuter, dijele na zasebne rečenice ili fragmente rečenica i od tih elemenata se gradi baza podataka koja se zatim učitava u pretraživač. Prilikom prevođenja novih tekstova, pretraživač traži rečenice i dijelove rečenica u njima koji su slični onima koje ima i ubacuje ih u prava mjesta prevedeni tekst. Tako se u automatskom načinu rada dobiva kvalitetan prijevod onih fragmenata novog teksta koji su dostupni u bazi podataka.
Neidentificirani fragmenti teksta se prevode na strani jezik ručno. U ovom slučaju, možete koristiti proceduru za približnu pretragu ovih fragmenata u bazi podataka i koristiti rezultate pretrage kao nagovještaj. Rezultati ručnog prijevoda novih fragmenata teksta se ponovo unose u bazu podataka. Kako se sve više dokumenata prevodi, "prevodilačka memorija" se postepeno obogaćuje i povećava se njena efikasnost.
Neosporna prednost tehnologije "translation memory" je visoka kvaliteta prijevode klase tekstova za koje je stvorena. Ali baza prevodnih korespondencija izgrađena za homogene tekstove jednog preduzeća pogodna je samo za homogene tekstove preduzeća bliskih profila, budući da se rečenice i veliki fragmenti rečenica izvučeni iz tekstova nekih dokumenata, po pravilu, ne javljaju ili su veoma rijetko se nalazi u tekstovima drugih dokumenata.
Da bi se prevazišlo ovo ograničenje „prevodne memorije“ i, što je najvažnije, da se izađe iz ćorsokaka u koji je, po svemu sudeći, ušla semantička teorija, usmeren je novi koncept mašinskog prevođenja, nazvan „frazeološka teorija mašinskog prevođenja“. Glavna karakteristika Ovaj koncept je ideja da pri prevođenju kao glavne i najstabilnije jedinice značenja ne treba uzeti u obzir semantičke komponente koje su sastavni dio jezika, već pojmove koji su povezani s jezikom kroz jezička značenja, ali istovremeno djeluju kao nezavisni oblik ljudsko razumevanje životne sredine materijalnog sveta. Dakle, prvi korak je napravljen da se mašina nauči da radi ne samo na lingvističkim, već i na ekstralingvističkim aspektima prevođenja.
Dozvolite mi da vas podsjetim da je ljudska svijest u stanju da reflektuje svijet oko sebe u obliku dva signalna sistema.Prvi signalni sistem opaža svijet oko sebe putem čula. Kao rezultat izlaganja jednom od čulnih organa (vid, sluh, dodir, miris, ukus) nastaje osjet. Na osnovu ukupnosti osjeta povezanih s određenim objektom, osoba ima holističku percepciju ovog objekta. Opaženi predmet može se pohraniti u memoriju u obliku odgovarajućeg prikaza istog bez direktnog senzornog kontakta.
Drugi signalni sistem omogućava osobi, apstrahujući od određenih objekata, da formira generalizovane koncepte o svetu oko sebe. Pojam se razlikuje po svom obimu, odnosno klasi objekata generalizovanih u pojmu, i sadržaju pojma - znakovima objekata preko kojih se generalizacija vrši. Ljudi operiraju konceptima u procesu komunikacije. Da biste to učinili, svakom konceptu se dodjeljuju određene oznake - njihova imena u obliku zasebnih riječi ili (što je mnogo češće) fraza. I unutra različitim jezicima može se koristiti za upućivanje na iste koncepte različiti znakovi(snowdrop, oko - pas - pas vodič, usisivač - usisivač).
Uzimajući u obzir navedene principe, sistem frazeološkog mašinskog prevođenja u uopšteno govoreći kao što slijedi. Kao što je već spomenuto, najstabilniji elementi teksta su nazivi pojmova. U procesu prevođenja, nazivi koncepata izvornog teksta zamjenjuju se nazivima ovih značenjskih jedinica na ciljnom jeziku, a dizajn tako dobivenog novog teksta vrši se u skladu s gramatičkim normama ciljnog teksta. jezik. Kao iu sistemima "Translationmemory", koristi se princip analogije - riječi, fraze i fraze koje odražavaju tipične situacije prevode se po analogiji s prethodno izvedenim prijevodima ovih jedinica. Razlika između njih leži u činjenici da se u sistemima tipa "prevodilačka memorija" ne koriste tako stabilni segmenti teksta kao što su pojmovi i tipične situacije, već sve rečenice koje se nalaze u izvornom tekstu.
Iz navedenog proizilazi da su mašinski rječnici najvažnija komponenta frazeoloških sistema mašinskog prevođenja. Broj različitih riječi u jezicima kao što su ruski i engleski prelazi milion, a broj relativno stabilnih frazeološkim frazama koji se broje u stotinama miliona. Frazeološki rječnici takvog volumena ne mogu se brzo izraditi. Dakle, volumen rječnika jednog od savremeni sistemi"RetransVista" je 3 miliona 300 hiljada rečničkih natuknica.
Stoga će sastavljanje frazeoloških rječnika velikih količina zahtijevati značajne vremenske troškove u sistemima za mašinsko prevođenje stalni pratilac frazeološke fraze biće odvojene riječi. Za njihovo prevođenje, kao što je spomenuto, koriste se odredbe semantičkog modela, dok kvalitet strojnog prijevoda izaziva brojne pritužbe.
To je svakako istina, ali prijevod tekstova od riječi do riječi je mnogo bolji od
odsustvo bilo kakvog prevoda.
Stoga, kako mnogi stručnjaci u ovoj oblasti smatraju, jedina razumna perspektiva za sisteme mašinskog prevođenja u 21. veku je kombinacija frazeološkog i semantičkog prevođenja reč po reč. Istovremeno, udio frazeološkog prijevoda, po svemu sudeći, trebao bi se stalno povećavati, a udio semantičkog prijevoda stalno bi se smanjivao.
Kako iskustvo pokazuje, sistemi za mašinsko prevođenje treba da budu fokusirani prvenstveno na prevođenje poslovnih tekstova iz oblasti nauke, tehnologije, politike i ekonomije. Prevod književnih tekstova je teži zadatak. Ali i ovdje, u budućnosti, može se postići određeni uspjeh ako postoje entuzijasti poput Vladimira Dala koji uz pomoć modernih tehnička sredstvaće preuzeti težak posao na sastavljanju moćnih frazeoloških rječnika za ovu vrstu tekstova.
Dodatna literatura.
1. Belonogov G.G. O upotrebi principa analogije u automatskoj obradi tekstualnih informacija. Sat. "Problemi kibernetike", br. 28, 1974.
2. Ubin I.I. Savremeni alati za automatizaciju prevođenja: nade, razočaranja i stvarnost. Sat. „Prebacite se na savremeni svet“, M., VCP, 2001, str. 60-69.
Trenutno postoje tri tipa sistema mašinskog prevođenja:
Sistemi zasnovani na gramatičkim pravilima (Mašinsko prevođenje zasnovano na pravilima, RBMT);
Statistički sistemi (Statističko mašinsko prevođenje, SMT);
hibridni sistemi;
Sistemi zasnovani na gramatici analiziraju tekst koji se koristi u procesu prevođenja. Prevod se vrši na osnovu ugrađenih rečnika za dati jezički par, kao i gramatika koje pokrivaju semantičke, morfološke, sintaktičke obrasce oba jezika. Na osnovu svih ovih podataka, izvorni tekst se sekvencijalno, rečenica po rečenica, pretvara u tekst na traženom jeziku. Osnovni princip rada ovakvih sistema je povezanost strukture izvornog i finalnog teksta.
Sistemi zasnovani na gramatičkim pravilima često se dijele u još tri podgrupe - sistemi prevođenja od riječi do riječi, sistemi prijenosa i međujezički sistemi.
Prednosti sistema zasnovanih na gramatičkim pravilima su gramatička i sintaktička tačnost, stabilnost rezultata i mogućnost prilagođavanja određenoj predmetnoj oblasti. Nedostaci sistema zasnovanih na gramatičkim pravilima uključuju potrebu za kreiranjem, održavanjem i ažuriranjem lingvističkih baza podataka, složenost kreiranja takvog sistema, kao i njegovu visoku cenu.
Statistički sistemi u svom radu koriste statističku analizu. U sistem se učitava dvojezični korpus tekstova (koji sadrži veliku količinu teksta na izvornom jeziku i njegov „ručni“ prevod na traženi jezik), nakon čega sistem analizira statistiku međujezičkih korespondencija, sintaksičkih konstrukcija itd. sistem se samouči – pri odabiru opcije prijevoda oslanja se na prethodne statistike. Što je veći vokabular unutar jezičkog para i što je tačniji, to je bolji rezultat statističkog mašinskog prevođenja. Sa svakim novim prevedenim tekstom kvaliteta narednih prijevoda se poboljšava.
Statistički sistemi se brzo postavljaju i lako se dodaju nova uputstva za prevođenje. Među nedostacima, najznačajniji su prisustvo brojnih gramatičkih grešaka i nestabilnost prijevoda.
Hibridni sistemi kombinuju ranije opisane pristupe. Očekuje se da će hibridni sistemi mašinskog prevođenja kombinovati sve prednosti koje imaju statistički sistemi i sistemi zasnovani na pravilima.
1.3 Klasifikacija sistema mašinskog prevođenja
Sistemi mašinskog prevođenja su programi koji obavljaju potpuno automatizovano prevođenje. Glavni kriterij programa je kvalitet prijevoda. Osim toga, važne točke za korisnika su praktičnost sučelja, lakoća integracije programa s drugim alatima za obradu dokumenata, izbor tema i uslužni program za dopunu rječnika. Sa pojavom Interneta, glavni proizvođači mašinskog prevođenja su ugradili veb interfejse u svoje proizvode, istovremeno ih integrišući sa drugim softverom i e-poštom, omogućavajući MT da se koristi za prevođenje veb stranica, e-pošte i onlajn razgovora.
Novi članovi CompuServe-ovog foruma stranih jezika često pitaju može li neko preporučiti dobar program za mašinsko prevođenje po razumnoj cijeni.
Odgovor na ovo pitanje je uvek "ne". U zavisnosti od ispitanika, odgovor može sadržati dva glavna argumenta: ili da mašine ne mogu da prevode, ili da je mašinsko prevođenje preskupo.
Oba ova argumenta su do određene mjere valjana. Međutim, odgovor je daleko od toga da je tako jednostavan. Prilikom proučavanja problema mašinskog prevođenja (MT), potrebno je posebno razmotriti različite podsekcije ovog problema. Sljedeća podjela je zasnovana na predavanjima Larryja Childsa na Međunarodnoj konferenciji o tehničkoj komunikaciji 1990.:
Potpuno automatski prijevod;
Automatsko strojno prevođenje uz sudjelovanje ljudi;
Prevod obavlja osoba koja koristi kompjuter.
Potpuno automatizovano mašinsko prevođenje. Ova vrsta mašinskog prevođenja je ono što većina ljudi misli kada govori o mašinskom prevođenju. Značenje je jednostavno: tekst na jednom jeziku se unosi u računar, ovaj tekst se obrađuje i računar ispisuje isti tekst na drugom jeziku. Nažalost, implementacija ove vrste automatskog prevođenja suočava se s određenim preprekama koje tek treba savladati.
Glavni problem je složenost samog jezika. Uzmimo, na primjer, značenje riječi "može". Pored glavnog značenja modalnog pomoćnog glagola, riječ "može" ima nekoliko službenih i žargonskih značenja kao imenica: "banka", "latrina", "zatvor". Osim toga, postoji arhaično značenje ove riječi - "znati ili razumjeti". Pod pretpostavkom da ciljni jezik ima posebnu riječ za svaku od ovih vrijednosti, kako ih kompjuter može razlikovati?
Kako se ispostavilo, postignut je određeni napredak u razvoju prevodilačkih programa koji razlikuju značenje na osnovu konteksta. Novije studije u analizi tekstova više se oslanjaju na teoriju vjerovatnoće. Međutim, potpuno automatizovano mašinsko prevođenje tekstova sa opsežnom tematikom i dalje je nemoguć zadatak.
Automatsko mašinsko prevođenje uz učešće ljudi. Ova vrsta mašinskog prevođenja je sada sasvim izvodljiva. Govoreći o mašinskom prevođenju uz učešće osobe, obično se misli na uređivanje tekstova i pre i nakon što ih računar obradi. Ljudski prevodioci mijenjaju tekstove tako da ih mašine mogu razumjeti. Nakon što kompjuter obavi prevod, ljudi ponovo uređuju grubi mašinski prevod, čineći tekst na ciljnom jeziku ispravnim. Pored ovog redosleda rada, postoje MT sistemi koji zahtevaju stalno prisustvo ljudskog prevodioca tokom prevođenja kako bi pomogli kompjuteru da prevede posebno složene ili dvosmislene strukture.
Mašinsko prevođenje uz pomoć ljudi primjenjivo je u većoj mjeri na tekstove s ograničenim vokabularom usko ograničenih tema.
Ekonomija korištenja mašinskog prevođenja uz pomoć ljudi je još uvijek diskutabilna. Sami programi su obično prilično skupi, a neki od njih zahtijevaju posebnu opremu za rad. Uređivanje prije i poslije se mora naučiti, a to nije prijatan posao. Kreiranje i održavanje baza podataka riječi je naporan proces i često zahtijeva posebne vještine. Međutim, za organizaciju koja prevodi velike količine tekstova u dobro definisanoj predmetnoj oblasti, mašinsko prevođenje uz pomoć ljudi može biti prilično isplativa alternativa tradicionalnom ljudskom prevođenju.
Prevod obavlja osoba koja koristi kompjuter. Ovim pristupom, ljudski prevodilac se stavlja u centar procesa prevođenja, dok se kompjuterski program smatra alatom koji proces prevođenja čini efikasnijim, a prevod tačnim. Ovo su konvencionalni elektronski rječnici koji pružaju prijevod tražene riječi, ostavljajući osobu odgovornu za izbor. željenu opciju i značenje prevedenog teksta. Ovakvi rječnici uvelike olakšavaju proces prevođenja, ali zahtijevaju od korisnika da ima određeno poznavanje jezika i utroši vrijeme na njegovu implementaciju. Pa ipak, sam proces prevođenja je znatno ubrzan i olakšan.
Među sistemima koji pomažu prevodiocu u njegovom radu, najvažnije mjesto zauzimaju tzv. Translation Memory (TM) sistemi.TM sistemi su interaktivni alat za akumulaciju parova ekvivalentnih segmenata teksta na izvornom jeziku i prevod u baze podataka sa mogućnošću njihovog naknadnog pretraživanja i uređivanja. Ovi softverski proizvodi nisu namijenjeni korištenju visoko inteligentnih informacionih tehnologija, već su, naprotiv, zasnovani na korištenju kreativnog potencijala prevoditelja. U toku rada prevodilac sam formira bazu podataka (ili je prima od drugih prevodilaca ili od naručioca), a što više jedinica sadrži, to je veći povrat od njenog korišćenja.
Evo liste najpoznatijih TM sistema:
Tranzitna švicarska kompanija Star,
Trados (SAD),
Menadžer prevođenja iz IBM-a,
Eurolang Optimizer francuske kompanije LANT,
DejaVu iz ATRIL-a (SAD),
WordFisher (Mađarska).
TM sistemi omogućavaju da se isključi ponovljeni prevod identičnih fragmenata teksta. Prevod segmenta prevodilac vrši samo jednom, a zatim se svaki naredni segment provjerava da li se podudara (puna ili nejasna) s bazom podataka, a ako se pronađe identičan ili sličan segment, onda se nudi kao prijevod opcija.
Trenutno je u toku razvoj na poboljšanju TM sistema. Na primjer, jezgro Star's Transit sistema je zasnovano na tehnologiji neuronske mreže.
Uprkos širokom spektru TM sistema, oni dijele nekoliko zajedničkih karakteristika:
Funkcija poravnanja. Jedna od prednosti TM sistema je mogućnost korištenja već prevedenih materijala na ovu temu. Baza podataka TM može se dobiti poređenjem originalnih i prijevodnih datoteka segment po segment.
Dostupnost uvozno-izvoznih filtera. Ovo svojstvo osigurava kompatibilnost TM sistema sa raznim programima za obradu teksta i izdavačkim sistemima i daje prevodiocu relativnu nezavisnost od korisnika.
Mehanizam za traženje nejasnih ili potpunih podudaranja. Upravo ovaj mehanizam predstavlja glavnu prednost TM sistema. Ako pri prevođenju teksta sistem naiđe na segment koji je identičan ili blizak prethodno prevedenom, tada se prevodiocu nudi već prevedeni segment kao varijanta prijevoda trenutnog segmenta, koja se može ispraviti. Stepen fuzzy podudarnosti postavlja korisnik.
Podrška za tematske rječnike. Ova funkcija pomaže prevodiocu da se drži pojmovnika. U pravilu, ako prevedeni segment sadrži riječ ili frazu iz tematskog rječnika, on se ističe bojom i nudi se njegov prijevod koji se automatski može umetnuti u prevedeni tekst.
Sredstva za traženje fragmenata teksta. Ovaj alat je vrlo zgodan kada uređujete prijevod. Ako više od dobra opcija prijevod bilo kojeg fragmenta teksta, onda se ovaj fragment može naći u svim segmentima TM, nakon čega se uzastopno vrše potrebne promjene u segmentima TM.
Naravno, kao i svaki softverski proizvod, TM sistemi imaju svoje prednosti i nedostatke, kao i svoj opseg. Međutim, u odnosu na TM sisteme, glavni nedostatak je njihova visoka cijena.
Posebno je zgodno koristiti TM sisteme pri prevođenju dokumenata kao što su uputstva za upotrebu, uputstva za upotrebu, projektna i poslovna dokumentacija, katalozi proizvoda i drugi dokumenti istog tipa sa velikim brojem podudaranja.