Como recuperar arquivo fpt dbf. Recuperação de dados. Descrição da recuperação de arquivos usando OfficeRecovery for DBF Online
Solução de negócio
Se não for possível usar um serviço de recuperação online, você pode baixar um dos seguintes utilitários:
Além da capacidade de recuperar informações em casa, eles também oferecem recursos ilimitados para recuperação de um grande número de arquivos, suporte profissional e muitas outras opções úteis para usuários corporativos.
Guia de vídeo para usar o serviço OfficeRecovery Online
Sobre o OfficeRecovery para DBF Online
OfficeRecovery for DBF Online recupera bancos de dados DBF danificados (dbf).
Versões suportadas do Visual FoxPro:
9,0, 8,0, 7,0, 6,0, 5,0 e 3,0
Os dados recuperados são salvos em um novo banco de dados do Visual FoxPro.
Após a conclusão da recuperação do arquivo, você pode avaliar os resultados da demonstração e registrar-se para receber os resultados gratuitamente ou comprá-los imediatamente. Caso o arquivo não possa ser recuperado, você pode solicitar sua análise por nossa experiente equipe de especialistas.
Exemplos de uso
Um serviço para reparar arquivos DBF danificados pode ser usado quando um arquivo dbf não abre no Microsoft Visual FoxPro e você vê erros ou avisos ao abri-lo.
Para recuperar rapidamente um arquivo dbf danificado, carregue o banco de dados dbf em nosso serviço de recuperação em nuvem usando o formulário nesta página.
É importante observar que se o processo de recuperação for bem-sucedido, você terá um arquivo dbf pronto para uso. Você pode obter um banco de dados dbf totalmente recuperado escolhendo opções pagas ou gratuitas.
Características padrão:
- Suporte a banco de dados Microsoft Visual FoxPro, dBASE, FoxBASE DBF
- Restaurar estrutura e dados da tabela
- Crie um novo banco de dados (.dbf) com os dados recuperados
- Fácil de usar, não requer habilidades especiais
Descrição da recuperação de arquivos usando OfficeRecovery for DBF Online
Dbfs corrompidos são arquivos que repentinamente se tornaram inutilizáveis e não podem ser abertos usando o Microsoft Visual FoxPro. Existem vários motivos pelos quais um arquivo dbf pode ser corrompido. E em alguns casos é possível consertar e restaurar um arquivo dbf danificado (Visual FoxPro 9.0, 8.0, 7.0, 6.0, 5.0, 3.0).
Se o seu banco de dados dbf repentinamente for corrompido ou não puder ser aberto no programa que o criou, não se desespere! Você não precisa mais comprar software caro para reparar apenas um arquivo dbf danificado. OfficeRecovery for DBF Online apresenta um novo serviço online que o ajudará a recuperar banco de dados dbf danificado instantaneamente. Tudo o que você precisa fazer é simplesmente baixar o arquivo dbf danificado usando um navegador, avaliar a qualidade dos resultados da demonstração de recuperação e escolher a solução que melhor se adapta a você.
OfficeRecovery Online para DBF suporta Microsoft Visual FoxPro 9.0, 8.0, 7.0, 6.0, 5.0, 3.0. Os dados recuperados são salvos em um novo banco de dados do Visual FoxPro.
OfficeRecovery for DBF Online oferece opções gratuitas e pagas para resultados de recuperação completos. A opção gratuita significa que os resultados completos podem ser obtidos de forma totalmente gratuita dentro de 14 a 28 dias. Tudo o que você precisa fazer é simplesmente se inscrever para obter resultados gratuitos após a conclusão do processo de recuperação do arquivo dbf. Se você precisar obter o arquivo dbf recuperado imediatamente, instantaneamente, precisará escolher uma opção paga em vez de gratuita.
O que fazer se não houver dados de recuperação identificados no seu arquivo dbf? Você pode solicitar uma análise não reembolsável do seu arquivo por nossa experiente equipe técnica. Em alguns casos, a recuperação de dados só é possível manualmente.
As pessoas, em busca de condições de trabalho confortáveis, muitas vezes não pensam na segurança dos seus dados e, mais cedo ou mais tarde, enfrentam problemas relacionados com a sua perda. Vamos considerar a solicitação de um cliente para USB Flash 2Gb Transcend. Segundo o cliente, um dia ao instalar o drive na porta USB do computador, foi sugerido que ele fosse formatado. Segundo o cliente, ele recusou e pediu ajuda ao administrador do sistema. O administrador do sistema, ao descobrir que o computador congela ao conectar um drive USB, não conseguiu pensar em nada melhor do que concordar com a proposta do sistema operacional de formatá-lo ( nunca faça isso!). Em seguida, o administrador do sistema usou o popular programa de recuperação automática R-Studio. O resultado de seu trabalho na forma de pastas sem nome foi copiado para o cliente em outra unidade. Ao visualizar o resultado, o cliente descobriu que cerca de um quarto dos arquivos não puderam ser abertos e, o pior de tudo, 1C Accounting 7.7 se recusou a iniciar com o banco de dados restaurado, citando arquivos ausentes.
Acontece que a cópia de backup desse banco de dados do cliente tinha mais de um ano.
O primeiro estágio na solução de tais problemas é criar uma cópia bloco por bloco da unidade original (ou, como tem sido costume escrever desde os tempos em que apenas unidades de disquete e de disco rígido magnético eram mídias de armazenamento, setor por setor ). Ao subtrair, é detectada uma velocidade de leitura instável, o que indica sério desgaste da memória NAND (leitura múltipla de NAND pelo controlador de página de memória NAND e correção de erros devido à redundância de códigos de correção de erros (ECC) é uma operação que consome muitos recursos, o que em última análise afeta a velocidade de leitura). Caso existam seções não lidas, é necessário preenchê-las com um padrão, que posteriormente nos ajudará a identificar os arquivos que não foram totalmente lidos.
Em seguida, procedemos à análise. É necessário estabelecer qual sistema de arquivos e dentro de quais limites estava anteriormente no flash USB. Ou seja, é necessário procurar expressões regulares específicas para vários metadados do sistema de arquivos, mas antes de começarmos, vamos verificar uma opção simples que assume que os limites da partição são os mesmos. Para fazer isso, defina os parâmetros atuais do sistema de arquivos.
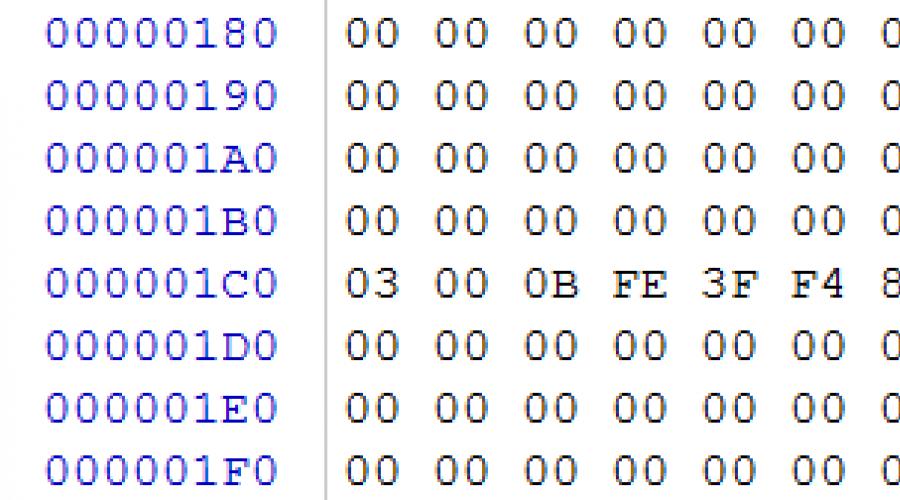
Abra o LBA 0 (0x0 no arquivo de imagem) e verifique a presença de uma tabela de partição ou do setor de inicialização do sistema de arquivos.

arroz. 2
No nosso caso, vemos no offset 0x1C2 o tipo de partição 0x0B, o que significa que no momento existe uma partição FAT32 no drive USB, que começa no setor 0x80 (DWORD no offset 0x1C6), com comprimento de setores 0x003C2000 ( DWORD no deslocamento 0x1CA). Vá para o setor de boot da partição descrita no setor 0x80 (no arquivo de imagem bytes 0x10000)

arroz. 3
É necessário calcular o ponto de partida, ou seja, a localização do cluster zero em relação ao qual o espaço é calculado, e também determinar o tamanho do cluster.
Para fazer isso, precisamos dos seguintes parâmetros descritos no setor de inicialização (serão indicados como um deslocamento desde o início do setor): tamanho do setor no deslocamento 0x0B - 0x200 (512 bytes), número de setores no cluster no deslocamento 0x0D - 0x08, o tamanho do cluster é obtido multiplicando o tamanho dos setores pelo número de setores no cluster 0x08*0x0200=0x1000 (4096 bytes), número de setores reservados até a primeira cópia das tabelas FAT - no deslocamento 0x0E=0x01FE (510 setores ), número de cópias FAT - no deslocamento 0x10=0x02, tamanho de uma cópia FAT - no deslocamento 0x24=00000F01 (3841 setores). Utilizando os parâmetros obtidos, calcularemos a posição do início da área de dados: 0x10000+0x01FE*200+0x00000F01*2*200=0x410000 (setor 8320). Um pequeno problema dos criadores do FAT32 é que no momento calculamos o início da área de dados para a partição FAT32, mas não é um ponto de referência zero, pois as duas primeiras entradas da tabela FAT são reservadas e não são usados para a finalidade pretendida e, portanto, O ponto zero é o início da área de dados menos 2 clusters. Neste caso será 0x410000-0x1000*2=0x40E000 (setor 8318).
Verificaremos a ausência de entradas na tabela de alocação de arquivos e realizaremos um procedimento de comparação de cópias em busca de discrepâncias.

Arroz. 4
A comparação das cópias FAT mostrou que não houve discrepâncias. A análise do conteúdo de uma das cópias do FAT mostrou que, conforme tabela, apenas um cluster foi preenchido na partição.
Em seguida, você precisa avaliar o diretório raiz para entradas excluídas. A posição do primeiro cluster do diretório raiz é indicada no setor de inicialização no deslocamento 0x2C=0x00000002. Para o segundo cluster, o FAT indica FF FF FF 0F, o que significa o fim da cadeia, ou seja, o diretório raiz consiste em um cluster.

arroz. 5
A partir do endereço calculado acima, vemos o diretório raiz (diretório raiz), que contém uma única entrada de 32 bytes. No deslocamento 0x0B vemos o valor 0x08, que indica o tipo de registro - rótulo do volume. O fato de as tabelas de alocação de arquivos estarem preenchidas com zeros e não haver nenhuma indicação de outras entradas no diretório raiz indica que esta partição foi formatada.
Para verificar a suposição de que a partição não foi recriada e todos os parâmetros do sistema de arquivos estão corretos, você precisa procurar a expressão regular 0x2E 0x2E 0x20 0x20 0x20 0x20 0x20 0x20 com um deslocamento dentro do setor 0x20 (esta expressão é um sinal do início do diretório FAT32).

arroz. 6
Ao encontrar uma expressão regular, você precisa ter certeza de que se trata realmente de um diretório, com base em outros critérios, pois em alguns casos é possível que haja uma correspondência e a expressão regular encontrada não seja um elemento do diretório. De acordo com as informações da Fig. 6, podemos dizer que este diretório começou com cluster 3 (o número do cluster atual do diretório DWORD está contido em WORD no deslocamento 0x1A (parte baixa) e WORD no deslocamento 0x14 (parte alta)) e foi descrito na raiz diretório, pois nos deslocamentos 0x3A e 0x34 contém zeros (o cluster inicial do diretório pai). Vamos verificar se o número do cluster deste diretório corresponde ao ponto de referência zero do sistema de arquivos criado após a formatação. Para fazer isso, multiplique o número do cluster de diretório pelo tamanho do cluster atual e adicione 0x03*0x1000+0x40E000=0x411000 ao ponto zero. Como você pode ver, o endereço de cobrança corresponde à localização real. Definir o nome deste diretório só é possível se o diretório raiz consistia anteriormente em mais de um cluster, e o link para este diretório não estava no primeiro cluster, pois o conteúdo do primeiro cluster foi completamente destruído durante a formatação, junto com o tabelas de alocação de arquivos.

arroz. 7
Repetimos todas as verificações: 0x04*0x1000+0x40E000=0x412000. Novamente vemos que a posição do diretório corresponde aos parâmetros do sistema de arquivos atual. Mas, além disso, vemos que existe um número de cluster do diretório pai 0x03, o que indica que este diretório foi aninhado, e olhando a Fig. 6, você pode definir o nome do diretório, mostrado na Fig. 7. Então, de acordo com a Fig. 6, no deslocamento 0x4B vemos o valor 0x10 - isso significa que esta entrada aponta para o diretório, e nos deslocamentos 0x5A e 0x54 o número 0x00000004 é um ponteiro para o 4º cluster. No deslocamento 0x40 – nome do diretório “BIN”. É assim que o relacionamento dos diretórios em uma partição FAT danificada é estabelecido. Depois de realizar um certo número de verificações de diretório em diferentes partes da imagem, podemos chegar à conclusão final de que esta unidade foi formatada dentro dos limites do sistema de arquivos anterior e os parâmetros do sistema de arquivos recém-criado são herdados do anterior. , ou seja, outras operações analíticas devem ser realizadas dentro da partição descrita na tabela de partições, levando em consideração os parâmetros do sistema de arquivos atual.
Sabendo que o banco de dados 1C, composto por arquivos DBF, deve conter o arquivo de configuração 1CV7.MD, procuraremos a sequência 0x31 0x43 0x56 0x37 0x20 0x20 0x20 0x20 0x4D 0x44. Para reduzir o número de resultados deliberadamente falsos, é melhor realizar a pesquisa em blocos de 32 bytes com deslocamento zero.

Arroz. 8
Assim, encontramos todos os diretórios que contêm um ponteiro para o arquivo 1CV7.MD. No nosso caso, apenas um desses diretórios foi encontrado, o que sugere que encontramos o primeiro cluster do diretório necessário. Isto é seguido por uma análise da posição dos diretórios pais, até o diretório raiz. Cada diretório encontrado é registrado na tabela FAT (primeiro como um diretório de um cluster, escrevendo FF FF FF 0F para o elemento da tabela correspondente). Um link para um objeto filho também é gravado no diretório raiz.
No estágio atual, copiaremos os arquivos encontrados presumindo sua continuidade, pois ambas as cópias do FAT não contêm informações sobre fragmentação (lembre-se que foram irremediavelmente destruídos pelo administrador do sistema em decorrência de formatação impensada do flash USB ). Após copiar o diretório do banco de dados 1C, analisamos a quantidade de arquivos. Considerando que o fragmento do diretório tinha o tamanho de um cluster, extraímos no máximo 126 arquivos, o que é claramente muito menor do que deveria estar em um diretório com arquivos DBF e CDX relacionados ao banco de dados 1C. Os programas de recuperação automática produzirão aproximadamente o mesmo resultado, conforme evidenciado pelo resultado obtido pelo administrador do sistema usando o R-Studio.
Os arquivos extraídos incluem 1CV7.MD (arquivo de configuração) e 1CV7.DD (arquivo de dicionário de dados). Após realizar a verificação de integridade, criaremos uma pasta temporária em nosso disco onde colocaremos 1CV7.MD. Indicaremos este caminho ao adicionar um novo banco de dados e abrir o configurador, através do qual criaremos um banco de dados limpo baseado nesta configuração. Vamos comparar o arquivo DD gerado com o restaurado; se as descrições e o número de diretórios forem idênticos, nenhuma ação adicional será necessária e, tendo uma lista completa de arquivos, você poderá começar a procurar os fragmentos restantes do diretório do banco de dados 1C. . Para fazer isso, você precisa procurar sequências de códigos de caracteres ASCII usados nos nomes dos arquivos DBF ausentes. À medida que os fragmentos de diretório são descobertos, adicione uma continuação da cadeia à tabela de alocação de arquivos. Após cada operação de adição de uma cadeia de diretórios, copie os arquivos e analise quanto o número de arquivos DBF ausentes foi reduzido e forme novamente uma sequência de códigos de caracteres ASCII para procurar o próximo fragmento.

arroz. 9
Também é necessário lembrar que ao gravar uma cadeia de fragmentos de diretório na tabela de alocação de arquivos, é necessário analisar os fragmentos para que os registros LFN sejam correspondidos. No caso apenas de registros curtos, a cadeia pode ser escrita com qualquer ordem de fragmentos.
Neste caso, após pesquisar 5 sequências, conseguimos encontrar todos os fragmentos restantes do diretório com a base de dados 1C.
Após a construção da cadeia completa de fragmentos de diretório, copiamos novamente todos os arquivos do banco de dados 1C com a suposição de sua continuidade. As informações do usuário estão contidas em arquivos DBF, portanto é necessário verificar sua integridade.
O principal método para monitorar a integridade de um arquivo DBF é verificar as informações contidas no cabeçalho do serviço e se o conteúdo do arquivo corresponde à descrição no cabeçalho.

arroz. 10
Inicialmente, o cabeçalho é avaliado: seu comprimento, indicado no deslocamento 0x08, é verificado para ver se o deslocamento nele especificado leva ao marcador final 0x0D. Os registros de campo base, começando no deslocamento 0x20, são descritos por registros de 32 bytes, nos quais o nome do campo segue no deslocamento 0x00, o tipo de campo no deslocamento 0x0B e o tamanho do campo no deslocamento 0x10. A soma dos tamanhos dos campos +1 (um byte adicional para cada registro no banco de dados é o status do registro no DBF) deve ser igual ao conteúdo no deslocamento 0x0A (o tamanho de um registro no banco de dados). Na imagem dos arquivos DBF vemos os seguintes comprimentos de campo: 0x09+0x10+0x10+0x10+0x10+0x10+0x01=0x5A.
Vamos verificar se o tamanho do arquivo está correto. Para fazer isso, multiplicamos o número de registros indicados no cabeçalho no deslocamento 0x04 pelo tamanho de um registro no banco de dados no deslocamento 0x0A, seguido da adição com o conteúdo no deslocamento 0x08.
0x00000003*0x005A+0xE1=0x01EF. O deslocamento resultante deve conter o marcador de fim de arquivo 0x1A.
Você pode usar um método visual para monitorar a integridade do conteúdo do campo.
Nesta opção de visualização, você precisa percorrer o conteúdo das postagens do início ao fim. Se o preenchimento for homogêneo, cada campo contém tipos de dados característicos do que está descrito no cabeçalho e não há conteúdo estranho, então após visualizar o arquivo DBF você pode concluir que seu conteúdo está correto.
Caso seja detectado conteúdo que não corresponda à descrição do campo no cabeçalho do banco de dados, é necessário estabelecer o local exato onde iniciam os dados incorretos.

Arroz. 12
Com base na descrição dos campos no cabeçalho e no conteúdo de um arquivo DBF específico, é possível gerar sequências ASCII provisórias que devem estar localizadas em deslocamentos especificados nos fragmentos ausentes. Se não houver bancos de dados do mesmo tipo em uma das unidades (incluindo cópias de arquivos do mesmo banco de dados), este método permitirá que você encontre de forma relativamente rápida todos os fragmentos ausentes na imagem da unidade. Separadamente, notamos que surgirão dificuldades adicionais na união de fragmentos se o tamanho do registro no arquivo DBF for pequeno ou múltiplo de 16. Se houver outros bancos de dados do mesmo tipo, a tarefa será muitas vezes mais complicada (esta afirmação é true em todas as etapas do trabalho, começando pela busca por fragmentos do diretório desejado).
É necessário verificar a integridade de cada arquivo DBF, dos quais existem várias centenas em um banco de dados 1C. Depois de passar por todas as verificações e coletar fragmentos de arquivos, uma verificação final ocorrerá no configurador 1C Enterprise.

arroz. 13
Idealmente, de acordo com os resultados do teste, todos os pontos marcados nas caixas de seleção devem ser aprovados. Caso sejam detectados erros nos dois primeiros pontos, é necessário analisar o log de erros no configurador e descobrir quais arquivos DBF contêm dados estranhos que não foram detectados durante as verificações. Se forem detectados erros na verificação da integridade lógica, novamente é necessário analisar o log de erros para saber se o problema do banco de dados está na qualidade de sua coleta ou em erros cometidos pelos desenvolvedores da configuração 1C.
Chamamos a atenção para o fato de que se este flash USB não tivesse sido formatado, após a revisão o procedimento de recuperação dos dados teria sido muito mais simples, o que teria reduzido muito o custo e o prazo de execução da obra. Concluindo, gostaria de alertar todos os usuários e pessoal de manutenção contra ações precipitadas em situações de emergência, que agravam repetidamente o problema, e também desejam realizar operações de backup com mais frequência.
Postado anteriormente no Clipper Summer 87.
Preciso criar um arquivo de índice CDX no Clipper 5.3, mas não consigo nem criar o arquivo exe.
No início do programa inseri:
SOLICITAR DBFCDX
rddSetDefault("DBFCDX")
Eu vinculo como no exemplo:
ARQUIVO BLINKER $(objs) SAÍDA $@ lib dbfcdx.lib
Ao construir dá um erro:
BLINKER: 1115: DBFCDX.LIB(CL53INIT): "_DBFCDX": externo não resolvido
Pisca-pisca substituído.
Comecei a tentar montar o BLINKER 6.0
o mesmo.
O que é interessante é se em vez de DBFCDX você conectar DBFNDX ao exemplo, ou seja,
em um programa
SOLICITAR DBFNDX
rddSetDefault("DBFNDX")
e então
ARQUIVO BLINKER $(objs) SAÍDA $@ lib dbfndx.lib
então tudo liga normalmente e funciona
Em relação à segunda pergunta - no meu sistema eu também uso CLIPPER (com mais frequência) e FOXPRO (com menos frequência e parei de usar, pois o FOXPRO tem uma desvantagem fatal - a dimensão máxima do array é 2. Para um algoritmista, isso é lenha. Se eu soubesse imediatamente, geralmente teria usado Não entrei em contato com a FOX). Mesmo assim, vários programas já estão na FOXe. No entanto, não entendo por que são necessários índices gerais. No clipper eu uso NDX, e no FOXe sua porra de IDX, DBF são comuns. O trabalho continua separadamente - cada um com o seu. Ou o sistema é tão monumental que há um fluxo contínuo de alterações de arquivos de ambos os lados? Receio que não exista uma solução normal para sistemas heterogêneos que trabalham tão próximos uns dos outros no nível do índice.
E em relação às falhas na criação do CDX pelo Clipper, o único conselho é fazer upload de um arquivo com um exemplo de teste mínimo sem a parte do assunto (programa + DBF + descrição da falha (quando e como ela se manifesta), talvez alguém consiga para chegar ao fundo do que está acontecendo.
Pelo menos eu estava interessado.
Resposta à carta anterior. Claro, eu vinculo _dbfcdx.lic, mas isso não ajuda.
Para perceber o seu interesse, você pode pegar o primeiro DBF que encontrar e construí-lo usando qualquer expressão de índice usando o clipper e o Fox.
O tamanho dos índices será diferente, sem falar no conteúdo de índices supostamente idênticos.
você Raposa há uma vantagem em relação a cortador: funciona muito mais rápido com o banco de dados, mas tenho uma tarefa para 400 mil assinantes, que precisam ser enumerados em massa todos os meses. A Fox ajudaria aqui, caso contrário, estou correndo em torno da gerência, procurando computadores que possa deixar durante a noite para fazer cálculos. Portanto, esta combinação às vezes é muito útil. Claro, isso está fora de questão, mas com tantos assinantes e, portanto, alta responsabilidade, faz sentido alocar um servidor separado. Então você pode executar tarefas de serviço nele. Meu programa Clipper, que já tem 13 anos, faz exatamente isso.
Andrey: Urri escreve: Tenho uma tarefa para 400 mil assinantes. Anteriormente, tinha uma tarefa para 150 mil assinantes. Contei a noite toda. Aí decidi o algoritmo (demorei muito) e comecei a contar em 5 horas. Mudou para xHarbour. Considera 1,5-2 horas aproximadamente. Então Fox e Clipper - é hora de mudar para compiladores normais. E se a gestão não entende o seu trabalho, você precisa mudar a gestão, ou pedir demissão. Quanto mais cedo você entender essa verdade, mais fácil será viver.
eu olhei xHarbor no início de sua carreira criativa, mas não encontrei a oportunidade de anexar ADS a ele, sem o qual agora não consigo me imaginar trabalhando para meus grandes bancos de dados (índices e transações corretos são caros). Se você sabe como fazer amizade com ADS, por favor me diga e me dê um link onde conseguir um xHarbor estável e funcional. Vou tentar aumentar a parte do cálculo - talvez isso facilite.
Mude para um compilador normal, você diz? Isto apesar do fato de que 60% das máquinas (de 300) são tais que metade delas dificilmente suporta w98, e a outra metade - w95 suporta apenas monitores de 14" e uma resolução de 640 * 480... O que, no VBasic-4? E é difícil mudar a liderança agora - há uma crise por toda parte, no entanto, os empregadores não favorecem os programadores agora. Ou é diferente na sua região: Há suporte de anúncios em Harbor. com anúncios ainda mais cedo do que com DBFCDX, ou seja, o rdd funcional estava pronto quando o DBFCDX ainda estava com erros.
Andrey: Urri escreve: que metade deles w98 dificilmente aguenta, e a outra metade - w95 só suporta monitores de 14" e uma resolução de 640*480... O que, no VBasic-4? Então o xHarbor ainda funciona MUITO mais estável em w98 - 95 e será mais rápido. Eu também duvidei muito disso antes, mas agora só estou me perguntando por que ninguém me mostrou isso (xHarbor) antes!!! haverá problemas, mas haverá pequenos problemas. Já trouxe 5 sistemas próprios e 3 de outra pessoa!!!
Urri: Caro (junto com o moderador Pasha)! Não me provoque, apenas me dê um link para a versão estável do xHarbor e rdd para ADS e onde posso ler sobre isso. Por favor. Muito necessário
Andrei: Droga! Basta pegar o xharbour, baixar a versão de lá e pronto! Estou nessa versão há quase um ano!
Realizou um teste para cortador 5.3, Pisca-pisca 1.0 e FoxPro 8.
Existem dois arquivos idênticos testclp.dbf e testfox.dbf
com campos NOME, NOME1 - C(10), NÚMERO, NÚMERO1, SUMMACLP, SUMMAFOX - N(10).
Programa especial fill.exe<кол-во записей>preenche esses dois arquivos desta maneira:
NAME=A000000001, NUMBER1=1 para a 1ª entrada,
NAME=A000000002, NUMBER1=2 para a 2ª entrada, etc.
Os campos NOME1 e NÚMERO1 são preenchidos de forma semelhante, mas na ordem inversa, ou seja, os valores especificados serão o último e o penúltimo registros, etc. Os campos SUMMAFOX e SUMMACLP não são preenchidos pelo fill.exe.
Depois, existem dois programas semelhantes no CLIPPER (testclp.exe) e no FoxPro (testfox.exe). Para testclp.exe (clipper), a tarefa é a seguinte:
a) indexe o arquivo testclp.dbf pelo campo NOME (tag FLD)
e pelo campo NAME1 (tag FLD1), criando “seu próprio” índice testclp.cdx;
b) percorra o arquivo testfox.dbf e, usando o arquivo de índice criado em a) para cada linha de testfox.dbf pelo valor NOME, encontre uma linha no arquivo testclp.dbf que tenha o mesmo campo NOME e adicione o NÚMERO campo deste arquivo para o campo SUMMACLP de testfox.dbf; em seguida, usando o mesmo valor NAME, encontre outra linha no arquivo testclp.dbf que tenha o mesmo campo NAME1 e subtraia testfox.dbf do campo SUMMACLP.
c) percorrer o arquivo testclp.dbf e, utilizando o arquivo de índice testfox.cdx criado por outro programa (testfox.exe - FoxPro),
para cada linha de testclp.dbf, encontre a linha usando o valor NAME
no arquivo testfox.dbf, que possui o mesmo campo NOME e adicione o campo NÚMERO
deste arquivo para o campo SUMMACLP de testclp.dbf; então usando o mesmo valor NAME
encontre uma linha no arquivo testfox.dbf que tenha o mesmo campo NAME1 e
subtraia do campo SUMMACLP de testclp.dbf.
Para testfox.exe (FoxPro) uma tarefa semelhante:
A) indexe o arquivo testfox.dbf por campo NOME (tag FLD)
e por campo NAME1 (tag FLD1), criando “seu próprio” índice testfox.cdx;
b) percorra o arquivo testclp.dbf e, usando o arquivo de índice criado em a) para cada linha de testclp.dbf pelo valor NOME, encontre uma linha no arquivo testfox.dbf que tenha o mesmo campo NOME e adicione o NÚMERO campo deste arquivo para o campo SUMMAFOX de testclp.dbf; em seguida, usando o mesmo valor NAME, encontre uma linha no arquivo testfox.dbf que tenha o mesmo campo NAME1 e subtraia-a do campo SUMMAFOX testclp.dbf.
c) percorrer o arquivo testfox.dbf e, utilizando o arquivo de índice testclp.cdx criado por outro programa (testclp.exe - Clipper),
para cada linha de testfox.dbf, encontre a linha usando o valor NAME
no arquivo testclp.dbf, que possui o mesmo campo NOME e adicione o campo NÚMERO
deste arquivo para o campo SUMMAFOX de testfox.dbf; então usando o mesmo valor NAME
encontre uma linha no arquivo testclp.dbf que tenha o mesmo campo NAME1 e
subtraia do campo SUMMAFOX testfox.dbf.
Assim, ao funcionar corretamente, ambos os programas devem somar e subtrair o mesmo número a cada campo de cada arquivo (embora localizados em registros diferentes), e como resultado, se o sistema funcionar corretamente, deverá haver valores zero em os campos SUMMACLP e SUMMAFOX em ambos os arquivos.
O teste foi realizado para 100.000 e 400.000 registros e, apesar dos diferentes tamanhos dos arquivos de índice, deu o resultado correto. A única coisa é que ao adicionar registros, um dos arquivos de índice (o “alien”) permanece incorreto, então quando você inicia pela primeira vez cada um dos programas só trabalha com o “seu” índice, e não funciona com o “alienígena”. " um. Após iniciar o segundo programa, ambos os arquivos são indexados corretamente e ambos os programas começam a funcionar sem falhas (da mesma forma ao reduzir o número de registros, mas ao mesmo tempo o FoxPro falha no índice de outra pessoa, e tive que usar o ON ERROR manipulador... Mas isso ocorre porque a alteração do número de registros é realizada pelo fill.exe sem abrir os dois índices, e também pelo fato de cada um dos programas não reindexar o outro índice (ou seja, este
o problema foi criado artificialmente - não deveria ser de outra forma). Se você permitir que o FoxPro reindexe o índice de outra pessoa, a operação normal será restaurada. Não “melhorei” ainda mais o sistema de tratamento de erros para que ambos os programas não fossem muito diferentes um do outro.
O resultado é o seguinte:
1) No começo eu tinha o Clipper 5.3 sem patch (e estou trabalhando nisso há muito tempo). Ele realmente travou: a partir de cerca de 40.000 registros, às vezes funcionava bem, às vezes travava, às vezes travava com um erro (como se o programa tivesse realizado uma operação inválida) no início do programa ao tentar indexar “seu” CDX. Conforme informado aqui no fórum, corrigi para 5.3b - tudo funcionou bem. Mas mesmo antes do patch, as falhas não eram no sentido de que os índices FoxPro não fossem compreendidos - sem reindexação(quando ambos os índices foram criados pelo FoxPro) o processamento foi realizado normalmente, o CLIPPER falhou ao criar “seus” índices.
2) para SGBDs modernos, 400.000 registros não é muito. Como
pode ser visto nos resultados do teste, processando o arquivo inteiro com uma pesquisa aleatória
leva de 2 a 3 minutos no máximo, mesmo em computadores um tanto desatualizados. Portanto, 2 a 4 horas em tecnologia moderna (e até 30 minutos) é “das ist fantastisch” em meus termos. O problema provavelmente está em um algoritmo antieconômico ou em gargalos como a largura de banda da rede (devido à mania da arquitetura cliente-servidor, em relação à qual tenho uma atitude negativa - mas isso é offtopic). 3) Como pode ser visto nos resultados do teste, o tempo para criar um índice é insignificante em comparação com o tempo total de operação, por isso é melhor criar índices novamente antes de iniciar o processamento do arquivo, não confiando em “estrangeiros” e “nossos” criados anteriormente índices (a menos que não sejam usados por outros programas neste momento).
Cada um dos programas no caso de normal processamento de arquivo informa o tempo (em segundos) necessário para:
- criar “o seu próprio” índice (alínea a);
- processar o arquivo utilizando seu índice “próprio” (alínea b);
- processar um arquivo usando um índice “estrangeiro” (alínea c);
- tempo total de trabalho (o tempo para preenchimento dos campos é adicionado aqui)
SUMMAFOX e SUMMACLP com valores zero em ambos os arquivos).
Arquivo anexado:
info.doc - resultados do experimento em tempo de execução.
fill.prg - texto auxiliar programas no clipper para preencher os arquivos.
calc.prg - texto do programa clipper.
program1.prg - texto do programa FoxPro.
makefill.bat - cria fill.exe (terá que ser um pouco ajustado)
makecalc.bat - cria testclp.exe (mesma coisa).
proj1.pjx - arquivo de projeto no FoxPro.
testfox.dbf e testclp.dbf - arquivos de dados (criados em DBU).
testclp.cdx é um arquivo de índice criado pelo CLIPPER.
testfox.cdx é um arquivo de índice criado pela FoxPro.
preencher.exe - programa para preencher arquivos.
testclp.exe é um programa CLIPPER.
testfox.exe é um programa FoxPro.
Testfox.exe exigirá um ambiente de execução (do VFP6
provavelmente não funcionará, então você terá que usar o texto de program1.prg
e é possível corrigi-lo também).
Para reduzir o tamanho do arquivo, os arquivos dbf contêm 10 registros; para realizar testes reais, o número de registros deve ser aumentado.
Se você tiver o CLIPPER 5.2, também terá que ajustar fill.prg e сalc.prg.
Tentarei fazer testes para CLIPPER "87, CLIPPER 5.2 e VFP6 um pouco mais tarde, pois não trabalho com essas versões e elas não estão funcionando no momento
(bem como testes cruzados como CLIPPER 5.2<->VFP8 e CLIPPER 5.3<->VFP6).
Apesar da aparente simplicidade da tarefa, ainda demorou muito, mas são precisamente esses estudos comparativos objetivos que me interessam significativamente: ALGO escreve: Portanto, 2 a 4 horas em tecnologia moderna (e até mesmo). 30 minutos) é “das ist fantastisch” nos meus termos. O problema provavelmente está em um algoritmo antieconômico. Isso não é um problema, nem é um algoritmo antieconômico. Normal, não funcionaria de outra maneira. Para entender esse algoritmo, é necessário fornecer um registro dos valores de 24 valores de dinheiro recebidos, 24 datas de recebimento de dinheiro, 24 tarifas, 24 valores de cobranças, etc. em uma entrada no banco de dados. Isto é o que escrevi no Clipper, e ainda não o reescrevi, e provavelmente não o farei. Vi como o cálculo das contas de serviços públicos foi implementado na plataforma 1C versão 7.5, então são 9.000. Os assinantes foram cobrados por cerca de 5 horas. E nada, ninguém reclamou.
Programas para recuperar informações perdidas em um PC.
↓ Novidade na categoria "Recuperação de Dados":
Livre
UndeletePlus 3.0.2.406 é um pequeno aplicativo que recupera arquivos excluídos. O aplicativo Undelete Plus irá ajudá-lo a recuperar arquivos perdidos, incluindo aqueles apagados no modo DOS, da Lixeira, do Windows Explorer ou de uma unidade de rede.
Livre  Scan DBF 1.6 é um aplicativo para reparar ou restaurar arquivos DBF danificados. O aplicativo Scan DBF irá ajudá-lo a recuperar arquivos danificados em caso de falha do computador ou de energia, quando o final ou o cabeçalho do arquivo DBF estiver danificado.
Scan DBF 1.6 é um aplicativo para reparar ou restaurar arquivos DBF danificados. O aplicativo Scan DBF irá ajudá-lo a recuperar arquivos danificados em caso de falha do computador ou de energia, quando o final ou o cabeçalho do arquivo DBF estiver danificado.
Livre  Recuva 1.42.544 é um aplicativo conveniente para recuperar arquivos excluídos. O aplicativo Recuva é fácil de usar e pode recuperar dados sem qualquer configuração ou para usuários que nunca encontraram programas semelhantes antes.
Recuva 1.42.544 é um aplicativo conveniente para recuperar arquivos excluídos. O aplicativo Recuva é fácil de usar e pode recuperar dados sem qualquer configuração ou para usuários que nunca encontraram programas semelhantes antes.
Livre  Recover My Files 4.9.4.1343 é um aplicativo para recuperar arquivos que foram excluídos da Lixeira do sistema operacional Windows. Além disso, o aplicativo Recover My Files tem a capacidade de recuperar arquivos perdidos devido à formatação do disco, apagados devido a uma falha no PC, falha de software ou excluídos por vírus.
Recover My Files 4.9.4.1343 é um aplicativo para recuperar arquivos que foram excluídos da Lixeira do sistema operacional Windows. Além disso, o aplicativo Recover My Files tem a capacidade de recuperar arquivos perdidos devido à formatação do disco, apagados devido a uma falha no PC, falha de software ou excluídos por vírus.
Livre  PC INSPECTOR File Recovery 4.0 é um aplicativo que você precisará para recuperar informações se seu disco rígido estiver danificado. O aplicativo PC INSPECTOR File Recovery pode funcionar com sistemas de arquivos FAT 12/16/32, bem como NTFS.
PC INSPECTOR File Recovery 4.0 é um aplicativo que você precisará para recuperar informações se seu disco rígido estiver danificado. O aplicativo PC INSPECTOR File Recovery pode funcionar com sistemas de arquivos FAT 12/16/32, bem como NTFS.
Livre  OS Backup Wizard 1.19 é um aplicativo de backup para Windows. A singularidade deste aplicativo é sua capacidade de não usar espaço excessivo em disco ao fazer backup de um sistema.
OS Backup Wizard 1.19 é um aplicativo de backup para Windows. A singularidade deste aplicativo é sua capacidade de não usar espaço excessivo em disco ao fazer backup de um sistema.
Livre 
Livre  Norton Ghost 15.0.0.35659 é um aplicativo para arquivar e restaurar dados em computadores pessoais. O aplicativo oferece suporte ao trabalho de backup e restauração sem reiniciar o sistema.
Norton Ghost 15.0.0.35659 é um aplicativo para arquivar e restaurar dados em computadores pessoais. O aplicativo oferece suporte ao trabalho de backup e restauração sem reiniciar o sistema.
Livre  Handy Backup 7.1.1 é um aplicativo conveniente para criar automaticamente cópias de seus dados e documentos, que podem ser salvos em qualquer dispositivo (externo ou interno, bem como em CD-RW) ou carregados em um servidor FTP.
Handy Backup 7.1.1 é um aplicativo conveniente para criar automaticamente cópias de seus dados e documentos, que podem ser salvos em qualquer dispositivo (externo ou interno, bem como em CD-RW) ou carregados em um servidor FTP.
Livre  GetDataBack 4.25 é uma ferramenta poderosa e conveniente para recuperar informações perdidas, danificadas ou excluídas do seu disco rígido. GetDataBack fornece uma interface intuitiva e desempenho aprimorado.
GetDataBack 4.25 é uma ferramenta poderosa e conveniente para recuperar informações perdidas, danificadas ou excluídas do seu disco rígido. GetDataBack fornece uma interface intuitiva e desempenho aprimorado.
Livre  BadCopy Pro 4.10.1215 é um aplicativo para recuperar dados de CDs, disquetes, dispositivos flash ou discos rígidos danificados, com vírus, gravados incorretamente ou com erros. O aplicativo BadCopy funciona automaticamente quando você especifica um diretório de recuperação, com a capacidade de trabalhar com vários formatos de arquivos gráficos, de texto e executáveis, arquivos e outros tipos de arquivos.
BadCopy Pro 4.10.1215 é um aplicativo para recuperar dados de CDs, disquetes, dispositivos flash ou discos rígidos danificados, com vírus, gravados incorretamente ou com erros. O aplicativo BadCopy funciona automaticamente quando você especifica um diretório de recuperação, com a capacidade de trabalhar com vários formatos de arquivos gráficos, de texto e executáveis, arquivos e outros tipos de arquivos.
Livre  Acronis True Image Home 2011 Build 6942/ Home 2012 Build 5545 é um aplicativo poderoso para criar imagens precisas de partições de disco selecionadas ou dos próprios discos. O aplicativo Acronis True Image cria uma cópia de backup de todos os dados, aplicativos e sistemas operacionais, com a capacidade de restaurar ou copiar rapidamente para outro computador com a capacidade de criar uma cópia completa deste computador.
Acronis True Image Home 2011 Build 6942/ Home 2012 Build 5545 é um aplicativo poderoso para criar imagens precisas de partições de disco selecionadas ou dos próprios discos. O aplicativo Acronis True Image cria uma cópia de backup de todos os dados, aplicativos e sistemas operacionais, com a capacidade de restaurar ou copiar rapidamente para outro computador com a capacidade de criar uma cópia completa deste computador.
Livre  Acronis Disk Director 11 Home é um pacote de software abrangente com muitas ferramentas necessárias para trabalhar com partições e unidades de disco rígido. O pacote de software tem a capacidade de gerenciar seus discos e partições, bem como criar seus próprios discos de inicialização para backup do sistema e recuperação rápida.
Acronis Disk Director 11 Home é um pacote de software abrangente com muitas ferramentas necessárias para trabalhar com partições e unidades de disco rígido. O pacote de software tem a capacidade de gerenciar seus discos e partições, bem como criar seus próprios discos de inicialização para backup do sistema e recuperação rápida.
Livre  DiVFix 1.10 usando este programa você pode facilmente visualizar vídeos .avi parcialmente baixados. DiVFix suporta a visualização de arquivos de vários formatos de vídeo, incluindo .wmv ou .mpeg. Como os arquivos .avi só podem ser visualizados se estiverem totalmente baixados, pelo fato de no final dos arquivos haver uma tabela de índice, e sem ela não pode ser aberta, não podem ser reproduzidos em outros players.
DiVFix 1.10 usando este programa você pode facilmente visualizar vídeos .avi parcialmente baixados. DiVFix suporta a visualização de arquivos de vários formatos de vídeo, incluindo .wmv ou .mpeg. Como os arquivos .avi só podem ser visualizados se estiverem totalmente baixados, pelo fato de no final dos arquivos haver uma tabela de índice, e sem ela não pode ser aberta, não podem ser reproduzidos em outros players.
Livre  Avi Previewer 2.2.7 é um programa que tem a capacidade de visualizar arquivos avi baixados incompletamente ou simplesmente danificados que não podem ser reproduzidos em reprodutores normais ou apresentam defeitos. O programa Avi Previewer permitirá que você conserte arquivos se estiverem danificados, restaure-os após exclusão ou extração inadequada do arquivo e assim por diante.
Avi Previewer 2.2.7 é um programa que tem a capacidade de visualizar arquivos avi baixados incompletamente ou simplesmente danificados que não podem ser reproduzidos em reprodutores normais ou apresentam defeitos. O programa Avi Previewer permitirá que você conserte arquivos se estiverem danificados, restaure-os após exclusão ou extração inadequada do arquivo e assim por diante.
Livre  Advanced ZIP Password Recovery 4.00 é um programa com recursos para recuperar senhas perdidas de arquivos ZIP.
Advanced ZIP Password Recovery 4.00 é um programa com recursos para recuperar senhas perdidas de arquivos ZIP.
 Captura de tela 1.
Captura de tela 1. Imediatamente após iniciar o programa Caixa de ferramentas de recuperação DBF Uma janela para selecionar o arquivo dbf a ser restaurado é aberta. A seleção do arquivo desejado pode ser feita de três maneiras:
Além do arquivo dbf, uma tabela também pode incluir em sua estrutura um arquivo contendo informações de campos do tipo MEMO. Tais arquivos, via de regra, possuem um nome que corresponde ao nome da tabela dbf e a extensão fpt para tabelas no formato FoxPro ou *.dbt para tabelas no formato dBase.
Observação: Se um arquivo dbf danificado contém campos do tipo MEMO, mas o arquivo fpt ou dbt não foi especificado, o programa DBF Recovery Toolbox restaurará apenas a estrutura de campos do arquivo da tabela principal e os links dele para o arquivo deste campo. Porém, as informações contidas no arquivo externo não serão processadas. Assim, se o arquivo MEMO não tiver sido danificado, será possível continuar trabalhando normalmente com a tabela restaurada. Porém, se além da própria tabela dbf, o arquivo fpt ou dbt estiver danificado e não restaurado, poderão ocorrer falhas durante a operação.
Após selecionar o arquivo da tabela a ser restaurado, para continuar trabalhando, é necessário clicar no botão Analisar, que está localizado na parte inferior da janela do programa.
Se ocorreu um erro ao inserir o nome ou caminho do arquivo da tabela, o programa exibirá um aviso Selecione o arquivo para recuperar! (Selecione um arquivo para restaurar!) e o processo de análise da estrutura da tabela não será iniciado.
 Captura de tela 2.
Captura de tela 2. Ao passar para a fase de visualização da estrutura e conteúdo dos dados da tabela de origem, o programa exibirá uma janela de aviso sobre o início do processo de recuperação das informações. Deseja iniciar a recuperação? (Deseja iniciar a recuperação?). Se você precisar alterar o nome ou caminho do arquivo dbf ou adicionar um arquivo MEMO à seleção, clique no botão Não e retorne à janela de seleção de arquivo usando o botão Voltar.
Se todos os arquivos forem especificados corretamente, clique em Sim na caixa de diálogo. Após clicar neste botão, o programa começará a analisar o arquivo da tabela dbf e arquivos de campo MEMO adicionais.
Se, ao analisar a estrutura da tabela de origem, foram encontrados campos MEMO, mas o arquivo fpt ou dbt - armazenamento para tais campos - não foi especificado, o programa procura arquivos desses tipos com um nome que corresponda ao nome do arquivo de origem no diretório a partir do qual ele é lido. Caso seja detectado, o programa exibirá uma janela solicitando que você utilize o arquivo ao analisar a tabela.
No processo de análise e restauração de informações, o programa Caixa de ferramentas de recuperação DBF:
- Lê o cabeçalho do arquivo, identifica nomes e tipos de campos da tabela e determina os deslocamentos nos quais os registros no arquivo de origem começam fisicamente.
- Identifica o início de cada registro na tabela de origem e extrai todos os campos desses registros do arquivo de origem. Se a tabela contiver campos do tipo MEMO, ela identifica links contidos nos registros da tabela para os endereços dos dados armazenados no arquivo desses campos. O arquivo MEMO em si não é processado.
- Se for especificado um arquivo associado aos campos MEMO (fpt ou dbt), o programa analisa sua estrutura e identifica as entradas do arquivo que correspondem às referências da tabela principal.
Ao restaurar as informações, uma barra de progresso será mostrada na parte inferior da tela, com a qual você poderá avaliar em que estágio se encontra a recuperação dos dados.
Após a conclusão da análise do arquivo dbf danificado, as informações recuperadas serão mostradas em forma de tabela na área de trabalho principal da janela. As colunas da tabela exibida na tela corresponderão aos campos do arquivo fonte, e as linhas da tabela corresponderão aos seus registros.
Se o arquivo estiver tão danificado que o programa não consiga recuperar as informações dele, um botão Enviar um arquivo aos desenvolvedores aparecerá na parte inferior da janela, com o qual você pode enviar o arquivo danificado aos desenvolvedores do programa por e-mail para obter mais informações. análise detalhada e restauração. Além disso, a qualquer momento você pode enviar um arquivo aos desenvolvedores para análise usando o item Enviar arquivo de origem localizado no menu Ações.
Após visualizar as informações recuperadas, você precisa clicar no botão Avançar localizado na parte inferior da janela do programa para prosseguir para a etapa de salvar o arquivo recuperado.
 Captura de tela 3.
Captura de tela 3. Ao trabalhar com o arquivo dbf original e quaisquer arquivos anexados, nenhuma alteração será feita neles. Todo o trabalho ocorre com uma cópia das informações localizadas na RAM do computador. Portanto, para continuar trabalhando com os dados recuperados, eles devem ser salvos em disco.
Neste caso, salvar as informações restauradas do arquivo original só é possível na versão cadastrada do programa. Na versão de teste, você só pode visualizar as informações na etapa 2.
Para salvar informações, você pode usar três maneiras de selecionar um arquivo:
- Insira o caminho e o nome do arquivo na caixa de combinação Nome do arquivo reparado (.dbf): localizada na área de trabalho principal da janela. Quando a janela de seleção de um arquivo para salvar é aberta, o programa preenche automaticamente o campo de entrada. Por padrão, propõe-se salvar o arquivo dbf restaurado na mesma pasta da qual o arquivo original foi obtido, mas com um nome que consiste no nome do arquivo original e no sufixo _repaired. Ou seja, se o arquivo example.dbf foi utilizado, o programa se oferecerá para salvá-lo com o nome example_repaired.dbf.
- Selecionando uma pasta para salvar e um nome de arquivo usando a caixa de diálogo padrão para salvar arquivo. O botão para abrir a caixa de diálogo de seleção de arquivo está localizado à direita da caixa de combinação. Ao abrir a caixa de diálogo, também são utilizados o diretório a partir do qual o arquivo fonte foi lido e o nome do arquivo, construído de acordo com o princípio descrito acima.
- Selecione um arquivo na lista suspensa do campo de entrada. Ao trabalhar com arquivos de tabela, o programa Caixa de ferramentas de recuperação DBF armazena informações sobre arquivos salvos anteriormente em suas configurações e, se necessário, esses nomes e caminhos de arquivos podem ser reutilizados.
Após especificar o caminho e o nome do arquivo salvo, para salvar as informações recuperadas, é necessário clicar no botão Salvar localizado na parte inferior da janela do programa.
Caso o diretório especificado no campo Nome do arquivo reparado (.dbf): não exista, será emitido o aviso Diretório não existe, o arquivo não será salvo e o programa permanecerá na fase de seleção do arquivo para salvar.
Se o arquivo especificado no campo já existir, o programa solicitará que você o reescreva. Deseja reescrever o arquivo existente? (Deseja substituir um arquivo existente?). Se você pressionar o botão Não, o programa também permanecerá na fase de seleção de arquivos. Se o botão Sim for clicado, ou se tal arquivo ainda não existir, o DBF Recovery Toolbox prosseguirá para o estágio de visualização dos resultados da recuperação.
 Captura de tela 4.
Captura de tela 4. O programa pode salvar as informações lidas do arquivo de origem em qualquer formato: dBase III-IV, FoxPro 3.x (ou posterior). Porém, esteja ciente de que ao salvar um documento em formato legado, alguns dados incompatíveis com a versão do arquivo que está sendo salvo podem ser perdidos ou danificados.
O formato do documento salvo é selecionado usando o campo da lista suspensa Selecionar versão do arquivo DBF de saída: (selecione a versão do arquivo DBF resultante).
Ao abrir a janela de seleção do formato do documento a ser salvo, o programa automaticamente se oferece para salvar o documento restaurado em uma versão do formato que corresponda ao documento original. Se o arquivo de origem estiver tão danificado que sua versão não possa ser determinada, o programa oferecerá, por padrão, salvar o arquivo na versão mais recente disponível do formato.
Após concluir as configurações de formato do documento salvo, para prosseguir com o processo de restauração e salvamento dos dados, é necessário clicar no botão Salvar arquivo, que está localizado na parte inferior da janela do programa.
Se necessário, você pode retornar à página de seleção de arquivo para salvar clicando no botão Voltar.
Captura de tela 5. Nesta fase do trabalho, o programa na área de trabalho principal da janela apresenta informações sobre todos os arquivos que foram restaurados nesta sessão do seu trabalho. As informações consistem em:
- nome e caminho do arquivo que foi restaurado;
- o nome e caminho do arquivo no qual as informações recuperadas foram salvas;
- número de registros recuperados;
- hora em que o arquivo da tabela dbf foi restaurado.
Depois de visualizar o log, você pode voltar usando o botão Voltar, localizado na parte inferior da janela do programa, para alterar quaisquer configurações para trabalhar com o programa (salvar o arquivo recuperado com um nome diferente, selecionar outro arquivo para recuperação, etc. .).
Se tiver terminado de trabalhar com o programa, você pode clicar no botão Concluir para sair ou simplesmente fechar a janela do programa.
Fim do trabalho
Após visualizar o log, você pode sair clicando no botão Sair ou selecionando Sair no menu Arquivo. Também é possível usar o botão Bak para retornar à primeira página do programa e selecionar outro arquivo para restaurar. Observe que neste caso, ao salvar o arquivo, o nome e a pasta do arquivo recuperado não mudam automaticamente e você precisará alterá-los manualmente ou selecioná-los em uma caixa de diálogo.