Hogyan lehet visszaállítani az fpt fájlt dbf. Adat visszanyerés. A fájl-helyreállítás leírása az OfficeRecovery for DBF Online eszközzel
Üzleti megoldások
Ha az online helyreállítási szolgáltatás használata nem lehetséges, letöltheti a következő segédprogramok egyikét:
Az otthoni információ-visszaállítási lehetőség mellett korlátlan lehetőséget kínálnak nagyszámú fájl helyreállítására, professzionális támogatást és sok más lehetőséget, amelyek hasznosak a vállalati felhasználók számára.
Videós útmutató az OfficeRecovery Online szolgáltatás használatához
Az OfficeRecovery for DBF Online bemutatása
Az OfficeRecovery for DBF Online javítja a sérült DBF (dbf) adatbázisokat.
A Visual FoxPro támogatott verziói:
9.0, 8.0, 7.0, 6.0, 5.0 és 3.0
A helyreállított adatok egy új Visual FoxPro adatbázisba kerülnek.
A fájl-helyreállítás befejezése után kiértékelheti a demó eredményeit, és regisztrálhat ingyenes eredményekre, vagy azonnal megvásárolhatja azokat. Ha a fájlt nem sikerült visszaállítani, megrendelheti annak elemzését tapasztalt szakembergárdánktól.
Példák a felhasználásra
A sérült DBF fájl javítási szolgáltatás akkor használható, ha egy dbf fájl nem nyitható meg a Microsoft Visual FoxPro programban, és a megnyitás során hibák vagy figyelmeztetések jelennek meg.
A sérült dbf fájl gyors helyreállítása érdekében töltse fel a dbf adatbázist felhő-helyreállítási szolgáltatásunkba az ezen az oldalon található űrlap segítségével.
Fontos megjegyezni, hogy ha a helyreállítási folyamat sikeres, akkor ennek eredményeként egy használatra kész dbf fájlt kap. Teljesen visszaállított dbf adatbázist kaphat a fizetős vagy ingyenes lehetőségek kiválasztásával.
Alapfelszereltség:
- Microsoft Visual FoxPro, dBASE, FoxBASE DBF adatbázisok támogatása
- Táblaszerkezet és adatok visszaállítása
- Hozzon létre egy új adatbázist (.dbf) a visszaállított adatokkal
- Könnyen használható, nem igényel speciális ismereteket
A fájl-helyreállítás leírása az OfficeRecovery for DBF Online eszközzel
A sérült dbf adatbázisok olyan fájlok, amelyek hirtelen használhatatlanná válnak, és nem nyithatók meg a Microsoft Visual FoxPro segítségével. Számos oka lehet annak, hogy egy dbf fájl megsérülhet. És bizonyos esetekben lehetséges a sérült dbf (Visual FoxPro 9.0, 8.0, 7.0, 6.0, 5.0, 3.0) fájl javítása és visszaállítása.
Ha a dbf adatbázisa hirtelen megsérül, vagy nem nyitható meg abban a programban, amellyel létrehozták, ne essen kétségbe! Már nem kell drága szoftvert vásárolnia egyetlen törött dbf fájl kijavításához. Az OfficeRecovery for DBF Online egy új online szolgáltatást kínál, amely segít a sérült dbf adatbázis azonnali helyreállításában. Mindössze annyit kell tennie, hogy letölti a sérült dbf fájlt egy böngésző segítségével, értékelje a demo eredmények helyreállításának minőségét, és válassza ki az Önnek legmegfelelőbb megoldást.
Az OfficeRecovery Online for DBF támogatja a Microsoft Visual FoxPro 9.0, 8.0, 7.0, 6.0, 5.0, 3.0 verzióit. A helyreállított adatok egy új Visual FoxPro adatbázisba kerülnek.
Az OfficeRecovery for DBF Online ingyenes és fizetős lehetőségeket kínál a teljes helyreállítási eredmények eléréséhez. Az ingyenes lehetőség azt feltételezi, hogy a teljes eredmény 14-28 napon belül teljesen ingyenesen érhető el. Mindössze annyit kell tennie, hogy előfizet az ingyenes eredményekért, miután a dbf fájl helyreállítási folyamat befejeződött. Ha azonnal, azonnal meg kell szereznie a visszaállított dbf fájlt, akkor ingyenes helyett fizetős lehetőséget kell választania.
Mi a teendő, ha a dbf fájl nem tartalmaz helyreállítási adatokat? Megrendelheti fájljának vissza nem térítendő elemzését tapasztalt műszaki csapatunktól. Bizonyos esetekben az adatok helyreállítása csak manuálisan lehetséges.
A számukra kényelmes munkakörülményeket kereső emberek gyakran nem gondolnak adataik biztonságára, és előbb-utóbb szembesülnek az elvesztésük problémájával. Tekintsük az ügyfél kérését USB Flash 2Gb Transcenddel. Az ügyfél szerint egy napon, amikor a meghajtót a számítógép USB-portjába telepítették, javasolták a formázást. Az ügyfél elmondása szerint ezt megtagadta, és a rendszergazdához fordult segítségért. A rendszergazda, miután felfedezte, hogy a számítógép „lefagy”, amikor USB-meghajtót csatlakoztatunk, nem talált ki jobbat, mint hogy egyetértett az operációs rendszer formázására vonatkozó javaslatával ( soha ne csináld!). Ezután a rendszergazda a népszerű R-Studio automatikus helyreállítási programot használta. Munkájának eredményét névtelen mappák formájában átmásolták a kliensre egy másik meghajtón. Az eredmény megtekintésekor az ügyfél azt tapasztalta, hogy a fájlok körülbelül egynegyede nem nyitható meg, és ami a legrosszabb, az 1C Accounting 7.7 nem hajlandó elindulni a visszaállított adatbázissal, hivatkozva a fájlok hiányára.
Mint kiderült, az ügyfélnek több mint egy éves biztonsági másolata volt erről az adatbázisról.
Az ilyen problémák megoldásának első lépése az eredeti meghajtó blokkonkénti másolatának elkészítése (vagy ahogyan azt szokás írni abból az időből, amikor csak floppy és merevlemez volt adathordozó, szektoronként) . Kivonáskor instabil olvasási sebesség észlelhető, ami a NAND memória komoly kopására utal (a NAND memórialapok többszöri kiolvasása a NAND vezérlő által és a redundáns hibajavító kódok (ECC) miatti hibajavítás igen erőforrásigényes művelet, ami végső soron az olvasási sebességet befolyásolja). Ha vannak olvasatlan szakaszok, akkor ezeket egy mintával kell kitölteni, amely később segít azonosítani a teljes egészében el nem olvasott fájlokat.
Ezután folytatjuk az elemzést. Meg kell határozni, hogy milyen fájlrendszer és milyen határokon belül volt korábban az USB flash-en. Ez azt jelenti, hogy meg kell keresni a különféle fájlrendszer-metaadatokra jellemző reguláris kifejezéseket, de mielőtt elkezdenénk, nézzünk meg egy egyszerű változatot, amely feltételezi, hogy a partícióhatárok azonosak. Ehhez állítsa be az aktuális fájlrendszer paramétereit.
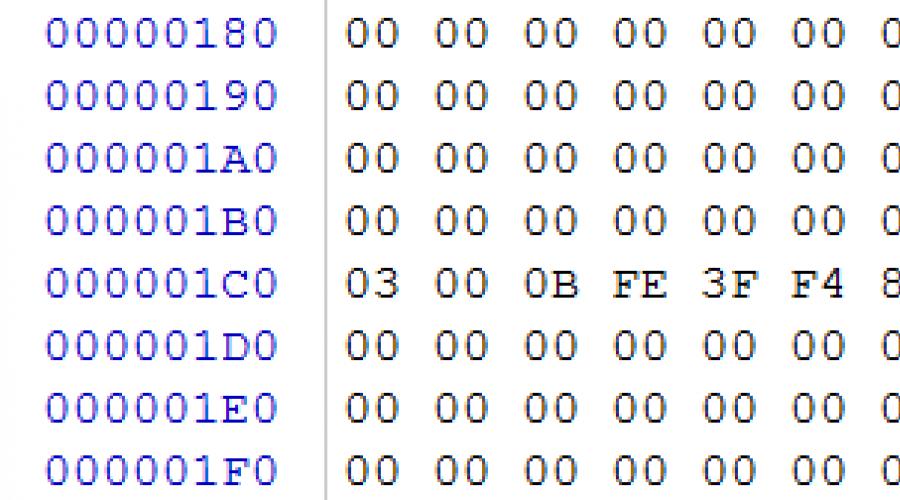
Nyissa meg az LBA 0-t (0x0 a képfájlban), és ellenőrizze, hogy van-e ott partíciós tábla, vagy hogy van-e a fájlrendszer rendszerindító szektora.

rizs. 2
Esetünkben a 0x0B típusú partíció 0x1C2 eltolását látjuk, ami azt jelenti, hogy jelenleg egy FAT32 partíció van az USB-meghajtón, amely 0x80 szektorral kezdődik (DWORD eltolásnál 0x1C6), 0x003C2000 szektor hosszú (DWORD eltolásnál 0x1CA). ). A leírt szakasz indító szektorába megyünk a 0x80 szektorban (a képfájlban 0x10000 bájt)

rizs. 3
Ki kell számítani a kiindulási viszonyítási pontot, vagyis annak a nulla klaszternek a helyét, amelyhez viszonyítva a teret számítjuk, és meg kell határozni a klaszter méretét is.
Ehhez a következő paraméterekre van szükségünk, amelyeket a rendszerindító szektorban leírtak (a szektor elejétől eltolásként lesz megadva): szektorméret eltolásnál 0x0B - 0x200 (512 bájt), szektorok száma a fürtben 0x0D eltolásnál - 0x08, a klaszter méretét úgy kapjuk meg, hogy a méretszektorokat megszorozzuk a fürtben lévő szektorok számával 0x08*0x0200=0x1000 (4096 bájt), a FAT táblák első példánya előtti lefoglalt szektorok számával - eltolás 0x0E=0x01FE ( 510 szektor), a FAT másolatok száma - eltolás szerint 0x10=0x02, egy FAT másolat mérete - eltolás szerint 0x24=00000F01 (3841 szektor). A kapott paraméterek felhasználásával kiszámítjuk az adatterület kezdetének pozícióját: 0x10000+0x01FE*200+0x00000F01*2*200=0x410000 (8320-as szektor). Kis bökkenő a FAT32 készítőitől, hogy jelenleg kiszámoltuk a FAT32 partíció adatterületének kezdetét, de ez nem nulla referenciapont, mivel a FAT tábla első két bejegyzése le van foglalva és nem rendeltetésüknek megfelelően használják, ezért a nulla pont az adatterület eleje mínusz 2 klaszter. Ebben az esetben 0x410000-0x1000*2=0x40E000 lesz (8318-as szektor).
Ellenőrizzük a rekordok hiányát a fájlkiosztási táblázatban, és végezzük el a másolatok összehasonlítását az eltérések keresésére.

Rizs. 4
A FAT-másolatok összehasonlítása azt mutatta, hogy nincsenek eltérések. Az egyik FAT-másolat tartalmának elemzése azt mutatta, hogy a táblázat szerint csak egy klaszter van kitöltve a partíción.
A következő lépés a gyökérkönyvtár kiértékelése a törölt bejegyzések szempontjából. Az első gyökérkönyvtár-fürt pozíciója a rendszerindító szektorban 0x2C=0x00000002 eltolásban van feltüntetve. A második klaszternél a FAT FF FF FF 0F értéket mutat, ami a lánc végét jelenti, vagyis a gyökérkönyvtár egy klaszterből áll.

rizs. 5
A fent kiszámított címen a gyökérkönyvtárat (root directory) látjuk, amely egyetlen 32 bájtos bejegyzést tartalmaz. A 0x0B eltolásnál a 0x08 értéket látjuk, amely jelzi a rekord típusát - a kötetcímkét. Az a tény, hogy a fájlkiosztási táblák nullákkal vannak kitöltve, és a gyökérkönyvtárban nincs utalás más bejegyzésekre, azt jelzi, hogy a partíció formázva van.
Annak ellenőrzésére, hogy a partíciót nem hozták létre újra, és minden fájlrendszer-paraméter helyes, meg kell keresni a 0x2E 0x2E 0x20 0x20 0x20 0x20 0x20 0x20 reguláris kifejezést a 0x20 szektoron belüli eltolással (ez a kifejezés egy FAT32 könyvtár).

rizs. 6
A reguláris kifejezés keresésekor meg kell győződni arról, hogy ez valóban egy könyvtár, más előjelek szerint, mivel bizonyos esetekben lehetséges az egyezés, és a talált reguláris kifejezés nem könyvtárelem. ábra információi szerint. 6, azt mondhatjuk, hogy ez a könyvtár a 3-as fürttel kezdődött (a DWORD-könyvtár jelenlegi fürtszámát a WORD 0x1A eltolásban (alsó rész) és a WORD 0x14 eltolásban (magasabb rész) tartalmazza), és a gyökérkönyvtárban van leírva, mivel a 0x3A és 0x34 eltolások nullákat tartalmaznak (a szülőkönyvtár kezdeti fürtje). Ellenőrizzük, hogy ennek a könyvtárnak a fürtszáma megfelel-e a formázás után létrehozott fájlrendszer nullapontjának. Ehhez szorozza meg a címtárfürt számát az aktuális fürt méretével, és adja hozzá a 0x03*0x1000+0x40E000=0x411000 értéket a nulla ponthoz. Amint látja, a számlázási cím megfelel a tényleges helynek. Ennek a könyvtárnak a nevét csak akkor lehet beállítani, ha korábban a gyökérkönyvtár egynél több fürtből állt, és az erre a könyvtárra mutató hivatkozás nem volt az első fürtben, mivel az első fürt tartalma a formázás során teljesen megsemmisült. a fájlkiosztási táblákat.

rizs. 7
Minden ellenőrzést megismételünk: 0x04*0x1000+0x40E000=0x412000. Ismét azt látjuk, hogy a könyvtár pozíciója megfelel az aktuális fájlrendszer paramétereinek. De ezen kívül azt látjuk, hogy van egy 0x03 szülőkönyvtár fürtszáma, ami azt jelzi, hogy ez a könyvtár be van ágyazva, és nézzük a 2. ábrát. A 6. ábrán beállíthatja a könyvtár nevét, amely az ábrán látható. 7. Tehát az ábra szerint. A 6. ábrán a 0x4B eltolásnál a 0x10 értéket látjuk – ez azt jelenti, hogy ez a bejegyzés egy könyvtárra mutat, a 0x5A és 0x54 eltolásoknál pedig a 0x00000004 szám a 4. klaszterre mutat. 0x40 eltolásnál - a "BIN" könyvtár neve. Így jön létre a sérült FAT partícióban lévő könyvtárak összekapcsolása. A kép különböző részein lévő könyvtárak bizonyos számú ellenőrzése után végül arra a következtetésre juthatunk, hogy ezt a meghajtót az előző fájlrendszer keretein belül formázták, és az újonnan létrehozott fájlrendszer paraméterei az előzőtől öröklődnek, A partíción belül további elemző műveleteket kell végrehajtani, a partíciós táblázatban leírtak szerint, figyelembe véve az aktuális fájlrendszer paramétereit.
Tudva, hogy a DBF fájlokból álló 1C adatbázisnak tartalmaznia kell az 1CV7.MD konfigurációs fájlt, keressük meg a 0x31 0x43 0x56 0x37 0x20 0x20 0x20 0x20 0x4D 0x44 sorozatot. A szándékosan hamis eredmények számának csökkentése érdekében jobb, ha 32 bájtos blokkokon belül nulla eltolással keresünk.

Rizs. nyolc
Így minden olyan könyvtárat megtalálunk, amely az 1CV7.MD fájlra mutató mutatót tartalmaz. Esetünkben csak egy ilyen könyvtárat találtunk, ami arra utal, hogy megtaláltuk a szükséges könyvtár első fürtjét. Ezt követi a szülőkönyvtárak helyzetének elemzése egészen a gyökérkönyvtárig. Minden talált könyvtár beírásra kerül a FAT táblába (először egy fürt könyvtáraként, az FF FF FF 0F beírásával a megfelelő táblabejegyzéshez). Ezenkívül a gyökérkönyvtárba egy gyermekobjektumra mutató hivatkozás is be van írva.
Jelenlegi szakaszban a talált fájlokat a folytonosságuk feltételezésével másoljuk, mivel mindkét FAT-másolat nem tartalmaz töredezettségi információt (emlékezzünk rá, hogy ezeket a rendszergazda helyrehozhatatlanul megsemmisítette egy gondatlan USB flash formázás eredményeként). Az 1C adatbázis-könyvtár másolása után elemezzük a fájlok számát. Tekintettel arra, hogy a könyvtártöredék egy klaszter méretű volt, legfeljebb 126 fájlt bontottunk ki, ami egyértelműen sokkal kevesebb, mint amennyi az 1C adatbázishoz kapcsolódó DBF és CDX fájlokat tartalmazó könyvtárban kellene. Körülbelül ugyanezt az eredményt adják az automatikus helyreállítási programok, amint azt a rendszergazda által az R-Studio használatával elért eredmény is bizonyítja.
A kibontott fájlok között található az 1CV7.MD (konfigurációs fájl) és az 1CV7.DD (adatszótár fájl). Az integritásellenőrzés elvégzése után létrehozunk egy ideiglenes mappát a lemezünkön, ahová az 1CV7.MD-t helyezzük el. Új adatbázis hozzáadásakor adja meg ezt az elérési utat, és nyissa meg a konfigurátort, amelyen keresztül a konfiguráció alapján tiszta adatbázist hozunk létre. Hasonlítsuk össze a generált DD fájlt a visszaállítottal, ha a leírások és a könyvtárak száma megegyezik, akkor nincs szükség további műveletekre, és a fájlok teljes listája birtokában elkezdheti keresni az 1C adatbázis-könyvtár fennmaradó töredékeit. . Ehhez meg kell keresnie a hiányzó DBF fájlok nevében használt ASCII karakterkódok sorozatait. Amint a könyvtár töredékeit megtalálja, adja hozzá a lánc folytatását a fájlkiosztási táblához. A címtárlánc hozzáadásának minden egyes művelete után másolja ki a fájlokat, és elemezze, hogy mennyivel csökkent a hiányzó DBF fájlok száma, majd hozzon létre ismét egy ASCII karakterkód sorozatot a következő töredék kereséséhez.

rizs. kilenc
Ne feledje azt is, hogy amikor könyvtártöredékekből álló láncot ír a fájlkiosztási táblába, elemeznie kell a töredékeket, hogy az LFN rekordok egyesüljenek. Csak rövid bejegyzések esetén a lánc tetszőleges töredéksorrenddel írható.
Ebben az esetben 5 szekvencia keresése után sikerült megtalálnunk a könyvtár összes többi töredékét az 1C bázissal.
A teljes könyvtártöredéklánc felépítése után újra másoljuk az 1C bázis összes fájlját a folytonosságuk feltételezésével. A felhasználói információkat a DBF fájlok tartalmazzák, ezért ellenőrizni kell azok integritását.
A DBF-fájlok integritásának ellenőrzésének fő módszere a szolgáltatás fejlécében található információk ellenőrzése, valamint, hogy a fájl tartalma egyezik-e a fejlécben található leírással.

rizs. tíz
Kezdetben a fejléc kiértékelése történik: a 0x08 eltolásnál megadott hosszát ellenőrzik, hogy a benne megadott eltolás a 0x0D végjelzőhöz vezet-e. Az alapmezőrekordokat a 0x20 eltolástól kezdve 32 bájtos rekordok írják le, amelyekben a mező neve 0x00 eltolásnál, a mező típusa 0x0B eltolásnál, a mező mérete pedig 0x10 eltolásnál következik. A mezőméretek összegének +1 (az adatbázis minden rekordjához egy plusz bájt a rekord állapota a DBF-ben) meg kell egyeznie a 0x0A eltolás tartalommal (egy rekord mérete az adatbázisban). A DBF fájlok ábráján a következő mezőhosszakat látjuk: 0x09+0x10+0x10+0x10+0x10+0x10+0x01=0x5A.
Ellenőrizzük a fájlméret helyességét. Ehhez megszorozzuk a fejlécben 0x04 eltolásnál jelzett rekordok számát az adatbázisban lévő 0x0A eltolású rekord méretével, majd összeadjuk a 0x08 eltolású tartalommal.
0x00000003*0x005A+0xE1=0x01EF. Az eredményül kapott eltolásnak tartalmaznia kell a 0x1A fájlvégi jelölőt.
A mezők tartalmának integritásának ellenőrzéséhez használhatja a vizuális módszert.
Ebben a nézetben végig kell görgetni a rekordok tartalmát az elejétől a végéig. Ha a kitöltés homogén, minden mező a fejlécben leírtakra jellemző adattípusokat tartalmaz, és nincs idegen tartalom, akkor a DBF fájl megtekintése után megállapíthatjuk, hogy annak tartalma helyes.
Ha olyan tartalmat talál, amely nem egyezik az adatbázis fejlécében található mező leírásával, meg kell határoznia a hibás adatok pontos helyét.

Rizs. 12
A fejléc mezőinek leírása és egy adott DBF fájl tartalma alapján feltételezhető ASCII szekvenciák képezhetők, amelyeknek a hiányzó töredékekben a megadott eltolásokon kell elhelyezkedniük. Ha az egyik meghajtón nincsenek azonos típusú adatbázisok (beleértve ugyanazon adatbázis fájlmásolatait is), akkor ez a módszer lehetővé teszi, hogy viszonylag gyorsan megtalálja az összes hiányzó töredéket a meghajtó képében. Külön megjegyezzük, hogy további nehézségek merülnek fel a töredékek összekapcsolásakor, ha a DBF fájl rekordmérete kicsi vagy 16 többszöröse. Ha vannak más azonos típusú adatbázisok, a feladat sokkal bonyolultabb lesz (ez az állítás igaz a munka minden szakaszában, kezdve a kívánt könyvtár töredékeinek keresésével).
Minden egyes DBF fájl integritását ellenőrizni kell, amelyekből több száz van egy 1C adatbázisban. Az összes ellenőrzés átesése és a fájltöredékek összegyűjtése után egy utolsó ellenőrzés következik az 1C Enterprise konfigurátorban.

rizs. tizenhárom
Ideális esetben a teszteredmények szerint minden jelölőnégyzetben megjelölt tétel sikeresen megfelel. Ha az első két ponton hibát találunk, akkor elemezni kell a hibanaplót a konfigurátorban, és ki kell deríteni, hogy mely DBF fájlok tartalmaznak olyan idegen adatokat, amelyeket az ellenőrzések során nem észleltünk. Ha hibákat talál a logikai integritás ellenőrzése során, akkor ismét elemezni kell a hibanaplót, hogy megtudja, hogy a probléma az alapban, mint annak gyűjteményében van-e, vagy az 1C konfiguráció fejlesztői által elkövetett hibákban.
Figyeljünk arra, hogy ha ez az USB flash meghajtó nem lett volna formázva, akkor az olvasás után sokkal egyszerűbb lenne az adatmentés folyamata, ami nagyban befolyásolná a költségeket és az átfutási időt. Végezetül szeretném figyelmeztetni az összes felhasználót és karbantartó személyzetet a vészhelyzetekben a problémát sokszorosára súlyosbító elgondolkodtató intézkedésekre, valamint gyakrabban szeretnének biztonsági mentési műveleteket végezni.
Korábban közzétéve a Clipper Summer 87-en.
Clipper 5.3-on CDX index fájlt kell létrehoznom, de még exe fájlt sem tudok készíteni.
A program elejére beszúrva:
DBFCDX KÉRÉSE
rddSetDefault("DBFCDX")
Belinkelem, mint a példában:
BLINKER FÁJL $(objs) KIMENET [e-mail védett] lib dbfcdx.lib
Építéskor hibát ad:
BLINKER: 1115: DBFCDX.LIB(CL53INIT) : "_DBFCDX" : megoldatlan külső
BLINKER cserélve.
Elkezdődött a BLINKERom 6.0 összegyűjtése
ugyanaz.
Az érdekes, ha a DBFCDX helyett a DBFNDX-et kapcsolod a példához, pl.
egy programban
DBFNDX KÉRÉSE
rddSetDefault("DBFNDX")
és akkor
BLINKER FÁJL $(objs) KIMENET [e-mail védett] lib dbfndx.lib
minden össze van kötve és jól működik.
A második kérdésre - az én rendszeremben a CLIPPER-t (gyakrabban) és a FOXPRO-t is használom (ritkábban és hozzá kötve, mert a FOXPRO-nak van egy halálos hibája - a maximális tömbméret 2. Algoritmistának ez a tűzifa. Ha azonnal tudnám, általában a FOX nem vette fel a kapcsolatot). De ennek ellenére több program már fent van a FOXe-n. Azt viszont nem értem, hogy miért kellenek közös indexek? A vágógépben NDX-et használok, FOXe-n pedig az ő kibaszott IDX-ét, a DBF gyakori. A munka külön-külön megy tovább – mindenkinek a sajátja. Vagy annyira monumentális a rendszer, hogy folyamatos a fájlmódosítások mindkét oldalról? Attól tartok, hogy a heterogén rendszerekre, amelyek index szinten ennyire szorosan együttműködnek egymással, nincs normális megoldás.
A CDX Clipper készítésének hibáiról pedig csak annyi a tanács, hogy egy minimális tesztesetet tartalmazó fájlt tölts fel tárgyrész nélkül (prog + DBF + a hiba leírása (mikor és hogyan jelentkezik), hátha sikerül valakinek a végére, hogy mi történik.
Legalábbis engem érdekelt.
Válasz az előző levélre. Természetesen linkelem a _dbfcdx.lic fájlt, de nem segít.
A felmerült érdeklődés felismeréséhez előveheti az első elérhető .DBF-et és megépítheti bármilyen indexkifejezéssel.CDX vágógéppel és fox-szal.
Az indexek mérete eltérő lesz, nem beszélve a vélhetően azonos indexek tartalmáról.
Nál nél róka van előnye nyírógép: sokkal gyorsabban működik az adatbázissal, és van egy feladatom 400 ezer előfizetőre, akiket havonta masszívan kell számolni. Itt Fox segített volna, egyébként rohangálok a vezetőségen, keresem a számítógépeket, amiket éjszakára is el lehet hagyni a számításhoz. Szóval egy ilyen csomó néha nagyon hasznosKSS: ... 400 ezer előfizetőre van egy feladatom ... ... egyébként rohangálok a vezetőségen, keresek éjszakára hagyható számítógépeket a számításhoz. Természetesen nem ez a téma, de ekkora előfizetőszám és ezért nagy felelősség mellett érdemes külön szervert kijelölni. Ezután szervizfeladatokat futtathat rajta. A már 13 éves Clipper programom pont ezt teszi.
Andrey: Urri írja: 400 ezer előfizetőnek van egy feladatom, régen 150 ezer előfizetőnek volt egy feladatom. Egész este számoltam. Aztán az algoritmus limitált (sokáig csinálta) 5 óra alatt kezdett számolni. Kikötőbe költözött. Körülbelül 1,5-2 órát vesz igénybe. Szóval Fox, Clipper – ideje váltani a normál fordítókra. És ha a vezetőség nem érti a munkáját, akkor menedzsmentet kell váltania, vagy fel kell adnia a munkát. Minél előbb megérted ezt az igazságot, annál könnyebb lesz tovább élni.
ránéztem xHarbor pályafutása elején, de aztán nem találta meg a lehetőséget, hogy ADS-t csatoljon hozzá, ami nélkül ma már el sem tudom képzelni, hogy nagy adatbázisaimnál dolgozzak (az indexek, tranzakciók helyessége drága). Ha tudja, hogyan lehet barátkozni az ADS-szel - kérem, mondja meg, és adjon egy linket, ahol stabilan működő xHarbort szerezhet. Megpróbálom a településrészt emelni rá - hátha jobb lesz.
Válts egy normál fordítóra, azt mondod? Ez annak ellenére van így, hogy a gépek 60%-a (a 300-ból) olyan, hogy a w98 fele alig bír húzni, a másik fele pedig - a w95 csak 14"-os monitort és 640*480-as felbontást támogat... A VBasic-4? menedzsmentjét most nehéz megváltoztatni - válság van körülötte, de a programozók munkaadói most nem kedveznek. Vagy más a helyzet az Ön régiójában? Pasha: Ads támogatás van a kikötőben. Harbour összebarátkozott A hirdetések még korábban, mint a DBFCDX-nél, azaz az Ads-hez működő rdd készen állt, amikor a DBFCDX még hibás volt
Andrey: Urri azt írja, hogy a fele w98 alig tud húzni, a másik fele pedig a w95 csak 14"-es monitorokat és 640*480-as felbontást támogat... Mi van, VBasic-4-en? és gyorsabb lesz. Én is előtte nagyon kételkedtem, de most már csak arra gondolok, hogy miért nem mutatta meg előttem senki (xHarbor)!!!Már hoztam 5 saját és 3 másik rendszert!!!
Urri: Kedves (pasa moderátorral együtt)! Nem kötekedsz, hanem adsz egy linket az xHarbor és az rdd stabil kiadásához ADS-hez, és ahol olvashatsz valamit. Kérem. Nagyon szükséges
Andrey: A fenébe is! Csak felveszed az xharbour-t, letöltöd onnan a verziót és kész! Már majdnem egy éve használom ezt a verziót!
Csinált egy tesztet Clipper 5.3, Villogó 1.0 és FoxPro 8.
Két azonos fájl van: testclp.dbf és testfox.dbf
NÉV, NÉV1 - C(10), SZÁM, SZÁM1, SUMMACLP, SUMMAFOX - N(10) mezőkkel.
Fill.exe speciális program<кол-во записей>mindkét fájlt így tölti ki:
NÉV=A000000001, NUMBER1=1 az 1. bejegyzéshez,
NÉV=A000000002, NUMBER1=2 a 2. bejegyzéshez stb.
A NÉV1 és SZÁM1 mezők kitöltése ugyanúgy, de fordított sorrendben történik, pl. a megadott értékek az utolsó és az utolsó előtti bejegyzést tartalmazzák, és így tovább. A SUMMAFOX és SUMMACLP mezőket a fill.exe program nem tölti ki.
Ezenkívül két hasonló program létezik a CLIPPER (testclp.exe) és a FoxPro (testfox.exe) számára. A testclp.exe (vágógép) esetében a feladat a következő:
a) indexelje a testclp.dbf fájlt a NÉV mezővel (FLD címke)
és a NAME1 mezővel (FLD1 címke), így létrehozva a "saját" indexet a testclp.cdx;
b) menjen végig a testfox.dbf fájlon, és az a) pontban létrehozott indexfájl segítségével a testfox.dbf minden sorához a NÉV értékkel keresse meg a testclp.dbf fájlban azt a sort, amelyiknek ugyanaz a NÉV mezője van, és adja hozzá a SZÁMOT. mező ebből a fájlból a testfox.dbf SUMMACLP mezőjébe; majd ugyanazzal a NÉV értékkel keressen egy másik sort a testclp.dbf fájlban, amelyben ugyanaz a NAME1 mező, és vonja ki a testfox.dbf fájlt a SUMMACLP mezőből.
c) menjen végig a testclp.dbf fájlon, és egy másik program (testfox.exe - FoxPro) által létrehozott testfox.cdx indexfájl segítségével
a testclp.dbf minden egyes sorához a NÉV érték alapján keresse meg a sort
a testfox.dbf fájlban, amely ugyanazt a NÉV mezőt tartalmazza, és adja hozzá a SZÁM mezőt
ebből a fájlból a testclp.dbf SUMMACLP mezőjébe; majd ugyanazzal a NÉV értékkel
keressen egy sort a testfox.dbf fájlban, amely ugyanazt a NAME1 mezőt tartalmazza, és
vonja le a SUMMACLP testclp.dbf mezőből.
A testfox.exe (FoxPro) esetében hasonló feladat:
a) indexelje a fájlt testfox.dbf NAME mező alapján (FLD címke)
és által terület NAME1 (FLD1 címke), miközben létrehozza a "saját" testfox.cdx indexet;
b) menjen végig a testclp.dbf fájlon, és az a) pontban létrehozott indexfájl segítségével a testclp.dbf fájl minden egyes sorához a NÉV értékkel keresse meg a testfox.dbf fájlban azt a sort, amelyiknek ugyanaz a NÉV mezője van, és adja hozzá a SZÁMOT. mező ebből a fájlból a testclp.dbf SUMMAFOX mezőjébe; majd ugyanazzal a NÉV értékkel keressen a testfox.dbf fájlban egy olyan sort, amelyben ugyanaz a NAME1 mező, és vonja ki a testclp.dbf fájlt a SUMMAFOX mezőből.
c) menjen végig a testfox.dbf fájlon, és egy másik program (testclp.exe - Clipper) által létrehozott testclp.cdx indexfájl segítségével
a testfox.dbf minden egyes sorához a NÉV érték alapján keresse meg a sort
a testclp.dbf fájlban, amely ugyanazt a NÉV mezőt tartalmazza, és adja hozzá a SZÁM mezőt
ebből a fájlból a testfox.dbf SUMMAFOX mezőjébe; majd ugyanazzal a NÉV értékkel
keressen egy sort a testclp.dbf fájlban, amely ugyanazt a NAME1 mezőt tartalmazza, és
vonjuk ki a SUMMAFOX testfox.dbf mezőből.
Így a helyes működés során mindkét programnak ugyanazt a számot kell hozzáadnia és kivonnia minden fájl minden mezőjéből (bár különböző rekordokban található), és ennek eredményeként, ha a rendszer megfelelően működik, nulla értéknek kell maradnia a fájlban. a SUMMACLP és SUMMAFOX mezőket mindkét fájlban.
A tesztet 100 000 és 400 000 rekordra végezték el, és az indexfájlok eltérő mérete ellenére a megfelelő eredményt adta. Az egyetlen dolog az, hogy bejegyzések hozzáadásakor az egyik indexfájl ("idegen") hibás marad, ezért az első indításkor mindegyik program csak a "saját" indexével dolgozik, az "idegen" indexszel nem. . A második program futtatása után mindkét fájl megfelelően indexelve van, és mindkét program hibamentesen kezd működni (hasonlóan, amikor a rekordok száma csökken, de a FoxPro hibába ütközik valaki más indexében, és az ON ERROR kezelőt kellett használnom. .. De ez annak köszönhető, hogy a rekordok számának módosítását a fill.exe mindkét index megnyitása nélkül hajtja végre, valamint azért, mert az egyik program nem indexeli újra valaki más indexét (azaz ezt
a problémát mesterségesen hozzák létre – ennek nem szabadna másként lennie). Ha engedélyezi a FoxPro-nak valaki más indexének újraindexelését, akkor a normál működés visszaáll. Továbbá nem "fejlesztettem" a hibakezelő rendszert, hogy a két program ne sokban térjen el egymástól.
Az eredmény a következő:
1) Eleinte Clipper 5.3 volt patch nélkül (és már régóta dolgozom rajta). Valóban összeomlott: valahonnan 40 000 rekord körül indult, néha jól működött, néha lefagyott, néha hibával (mintha a program illegális műveletet végzett) a program elején, amikor megpróbálta indexelni "a" CDX-ét. Ahogy itt a fórumon tanácsoltam, javítottam az 5.3b-t - minden rendben működött. De még a javítás előtt sem voltak hibák abban az értelemben, hogy a FoxPro-indexeket nem értik – anélkül újraindexelés(amikor mindkét indexet a FoxPro hozta létre) a feldolgozás általában megtörtént, a CLIPPER az "saját" indexek létrehozására esett.
2) a modern DBMS-ek esetében a 400 000 rekord nem túl sok. hogyan
a teszteredményekből nézve a teljes fájl feldolgozása véletlenszerű kereséssel
2-3 percet vesz igénybe még kissé elavult számítógépeken is. Szóval 2-4 óra modern technológián eltöltött idő (és még 30 perc is) az én fogalmaim szerint "das ist fantastisch". A probléma nagy valószínűséggel vagy egy gazdaságtalan algoritmusban van, vagy olyan szűk keresztmetszetekben, mint például a hálózati sávszélesség (a kliens-szerver architektúra iránti őrület miatt, amihez negatívan viszonyulok - de ez offtopic). 3) Mint a teszteredményekből is látszik, az index létrehozásának ideje elenyésző a teljes működési időhöz képest, ezért célszerű a fájlfeldolgozás megkezdése előtt újra létrehozni az indexeket, nem bízva a korábban létrehozott "idegen"-ben és "saját"-ban. indexek (kivéve, ha más programok jelenleg nem használják).
A programok mindegyike normál esetén fájlfeldolgozás jelenti a szükséges időt (másodpercben):
- "saját" index létrehozása (a pont);
- fájlfeldolgozás "saját" indexszel (b tétel);
- fájlfeldolgozás "idegen" indexszel (c tétel);
- teljes munkaidő (itt további idő kerül hozzáadásra a mezők kitöltéséhez
SUMMAFOX és SUMMACLP null értékekkel mindkét fájlban).
Csatolt archívum:
info.doc - futásidejű kísérlet eredményei.
fill.prg - segédszöveg programokat vágógépen a fájlok kitöltéséhez.
calc.prg - a clipper program szövege.
program1.prg - FoxPro program szövege.
makefill.bat - létrehozza a fill.exe fájlt (kicsit módosítani kell)
makecalc.bat – létrehozza a testclp.exe fájlt (ugyanaz).
proj1.pjx – FoxPro projektfájl.
A testfox.dbf és a testclp.dbf adatfájlok (DBU-ban készültek).
testclp.cdx – a CLIPPER által létrehozott indexfájl.
A testfox.cdx a FoxPro által létrehozott inex fájl.
fill.exe- program a fájlok befejezéséhez.
testclp.exe – CLIPPER program.
A testfox.exe egy FoxPro program.
A testfox.exe futtatókörnyezetet igényel (a VFP6
valószínűleg nem fog működni, ezért a program1.prg szövegét kell használnod
és esetleg javítva.)
Az archívum méretének csökkentése érdekében a dbf fájlok egyenként 10 rekordot tartalmaznak, valódi tesztekhez a rekordok számát növelni kell.
Ha elérhető a CLIPPER 5.2, akkor a fill.prg-t és a сalc.prg-t is javítani kell.
Kicsit később megpróbálom a CLIPPER "87, CLIPPER 5.2 és VFP6 teszteket elvégezni, mivel nem dolgozom ezekkel a verziókkal, és most nincsenek működőképes állapotban
(valamint a kereszttesztek, mint a CLIPPER 5.2<->VFP8 és CLIPPER 5.3<->VFP6).
A feladat látszólagos egyszerűsége ellenére még így is sok időbe telt, de pont az ilyen objektív összehasonlító tanulmányok érdekelnek számottevően. ist fantastish" szóval. A probléma nagy valószínűséggel vagy egy gazdaságtalan algoritmusban van, ez nem probléma, és nem gazdaságtalan algoritmus. Normális, máshogy nincs. Ennek az algoritmusnak a koncepciójához 24 pénzbevételi összeg, 24 pénzbevételi dátum, 24 tarifa, 24 díjösszeg stb. értékének nyilvántartása szükséges. egy rekordba az adatbázisban. Tehát még mindig én írtam a Clipperen, és még nem készítettem újra, és valószínűleg nem is fogom. Láttam, hogy az 1C platform 7.5-ös verzióján hogyan hajtották végre a közüzemi számlák elhatárolását, így ott 9.tys. az előfizetők felhalmozása körülbelül 5 órára történt. És semmi, senki nem panaszkodott.
Programok elveszett információk helyreállítására a számítógépen.
↓ Újdonság az Adatmentés kategóriában:
Ingyenes
Az UndeletePlus 3.0.2.406 egy kis alkalmazás, amely helyreállítja a törölt fájlokat. Az Undelete Plus alkalmazás segít helyreállítani az elveszett fájlokat, beleértve a DOS módban törölteket is, a Lomtárból, a Windows Intézőből vagy a hálózati meghajtóról.
Ingyenes  A Scan DBF 1.6 a sérült DBF fájlok javítására vagy visszaállítására szolgáló alkalmazás. A Scan DBF alkalmazás segít a sérült fájlok helyreállításában számítógép vagy áramkimaradás esetén, ha a DBF fájl vége vagy fejléce megsérül.
A Scan DBF 1.6 a sérült DBF fájlok javítására vagy visszaállítására szolgáló alkalmazás. A Scan DBF alkalmazás segít a sérült fájlok helyreállításában számítógép vagy áramkimaradás esetén, ha a DBF fájl vége vagy fejléce megsérül.
Ingyenes  A Recuva 1.42.544 egy praktikus alkalmazás a törölt fájlok helyreállításához. A Recuva alkalmazás könnyen használható, és minden konfiguráció nélkül képes visszaállítani az adatokat, illetve olyan felhasználók számára, akik korábban nem találkoztak hasonló programokkal.
A Recuva 1.42.544 egy praktikus alkalmazás a törölt fájlok helyreállításához. A Recuva alkalmazás könnyen használható, és minden konfiguráció nélkül képes visszaállítani az adatokat, illetve olyan felhasználók számára, akik korábban nem találkoztak hasonló programokkal.
Ingyenes  A Recover My Files 4.9.4.1343 egy olyan alkalmazás, amely a Windows operációs rendszer Lomtárával törölt fájlok helyreállítására szolgál. Ezenkívül a Recover My Files alkalmazás képes helyreállítani a lemez formázása miatt elveszett, számítógép- vagy szoftverhiba miatt törölt vagy vírusok által törölt fájlokat.
A Recover My Files 4.9.4.1343 egy olyan alkalmazás, amely a Windows operációs rendszer Lomtárával törölt fájlok helyreállítására szolgál. Ezenkívül a Recover My Files alkalmazás képes helyreállítani a lemez formázása miatt elveszett, számítógép- vagy szoftverhiba miatt törölt vagy vírusok által törölt fájlokat.
Ingyenes  A PC INSPECTOR File Recovery 4.0 egy olyan alkalmazás, amelynek vissza kell állítania az információkat, ha a merevlemez megsérül. A PC INSPECTOR File Recovery FAT 12/16/32, valamint NTFS fájlrendszerekkel is működhet.
A PC INSPECTOR File Recovery 4.0 egy olyan alkalmazás, amelynek vissza kell állítania az információkat, ha a merevlemez megsérül. A PC INSPECTOR File Recovery FAT 12/16/32, valamint NTFS fájlrendszerekkel is működhet.
Ingyenes  Az OS Backup Wizard 1.19 egy biztonsági mentési alkalmazás a Windows rendszerhez. Az alkalmazás egyedisége abban rejlik, hogy a rendszer biztonsági mentése során nem használ fölösleges lemezterületet.
Az OS Backup Wizard 1.19 egy biztonsági mentési alkalmazás a Windows rendszerhez. Az alkalmazás egyedisége abban rejlik, hogy a rendszer biztonsági mentése során nem használ fölösleges lemezterületet.
Ingyenes 
Ingyenes  A Norton Ghost 15.0.0.35659 egy személyi számítógépeken lévő adatok archiválására és visszaállítására szolgáló alkalmazás. Az alkalmazás támogatja a biztonsági mentést és a visszaállítást a rendszer újraindítása nélkül.
A Norton Ghost 15.0.0.35659 egy személyi számítógépeken lévő adatok archiválására és visszaállítására szolgáló alkalmazás. Az alkalmazás támogatja a biztonsági mentést és a visszaállítást a rendszer újraindítása nélkül.
Ingyenes  A Handy Backup 7.1.1 egy praktikus alkalmazás az adatok és dokumentumok automatikus másolatainak létrehozásához, amelyeket bármilyen eszközön (külső vagy belső, valamint CD-RW-n) tárolhatunk, vagy FTP-szerverre tölthetünk fel.
A Handy Backup 7.1.1 egy praktikus alkalmazás az adatok és dokumentumok automatikus másolatainak létrehozásához, amelyeket bármilyen eszközön (külső vagy belső, valamint CD-RW-n) tárolhatunk, vagy FTP-szerverre tölthetünk fel.
Ingyenes  A GetDataBack 4.25 egy hatékony és kényelmes eszköz az elveszett, sérült vagy törölt adatok merevlemezéről való helyreállítására. A GetDataBack alkalmazás intuitív felületet és jobb teljesítményt biztosít.
A GetDataBack 4.25 egy hatékony és kényelmes eszköz az elveszett, sérült vagy törölt adatok merevlemezéről való helyreállítására. A GetDataBack alkalmazás intuitív felületet és jobb teljesítményt biztosít.
Ingyenes  A BadCopy Pro 4.10.1215 egy olyan alkalmazás, amellyel CD-kről, hajlékonylemezekről, flash-eszközökről vagy merevlemez-meghajtókról lehet adatokat helyreállítani, amelyek sérültek, vírusosak, helytelenül rögzítettek vagy hibásak. A BadCopy alkalmazás automatikusan működik, amikor megadja a helyreállítási könyvtárat, és képes különféle formátumú grafikus, szöveges és végrehajtható fájlokkal, archívumokkal és más típusú fájlokkal dolgozni.
A BadCopy Pro 4.10.1215 egy olyan alkalmazás, amellyel CD-kről, hajlékonylemezekről, flash-eszközökről vagy merevlemez-meghajtókról lehet adatokat helyreállítani, amelyek sérültek, vírusosak, helytelenül rögzítettek vagy hibásak. A BadCopy alkalmazás automatikusan működik, amikor megadja a helyreállítási könyvtárat, és képes különféle formátumú grafikus, szöveges és végrehajtható fájlokkal, archívumokkal és más típusú fájlokkal dolgozni.
Ingyenes  Az Acronis True Image Home 2011 Build 6942/ Home 2012 Build 5545 egy hatékony alkalmazás a kiválasztott lemezpartíciók vagy a lemezek pontos képeinek létrehozására. Az Acronis True Image teljes biztonsági másolatot készít az összes adatról, alkalmazásról és operációs rendszerről, és gyorsan visszaállíthatja vagy másolhatja egy másik számítógépre, és ezzel a számítógépről teljes másolatot készíthet.
Az Acronis True Image Home 2011 Build 6942/ Home 2012 Build 5545 egy hatékony alkalmazás a kiválasztott lemezpartíciók vagy a lemezek pontos képeinek létrehozására. Az Acronis True Image teljes biztonsági másolatot készít az összes adatról, alkalmazásról és operációs rendszerről, és gyorsan visszaállíthatja vagy másolhatja egy másik számítógépre, és ezzel a számítógépről teljes másolatot készíthet.
Ingyenes  Az Acronis Disk Director 11 Home egy átfogó szoftvercsomag, amely számos eszközt tartalmaz a partíciókkal és merevlemez-meghajtókkal való munkához. A szoftvercsomag képes kezelni a lemezeket és partíciókat, valamint létrehozni saját indítólemezeket a rendszer biztonsági mentéséhez és a gyors helyreállításhoz.
Az Acronis Disk Director 11 Home egy átfogó szoftvercsomag, amely számos eszközt tartalmaz a partíciókkal és merevlemez-meghajtókkal való munkához. A szoftvercsomag képes kezelni a lemezeket és partíciókat, valamint létrehozni saját indítólemezeket a rendszer biztonsági mentéséhez és a gyors helyreállításhoz.
Ingyenes  DiVFix 1.10 ezzel a programmal könnyedén megtekintheti a részben feltöltött .avi videókat. A DiVFix különféle videoformátumok megtekintését támogatja, beleértve a .wmv vagy .mpeg fájlokat. Mivel az .avi fájlok csak teljesen letöltött állapotban tekinthetők meg, amiatt, hogy a fájlok végén indextábla található, és enélkül nem nyitható meg, így más lejátszókon sem játszhatók le.
DiVFix 1.10 ezzel a programmal könnyedén megtekintheti a részben feltöltött .avi videókat. A DiVFix különféle videoformátumok megtekintését támogatja, beleértve a .wmv vagy .mpeg fájlokat. Mivel az .avi fájlok csak teljesen letöltött állapotban tekinthetők meg, amiatt, hogy a fájlok végén indextábla található, és enélkül nem nyitható meg, így más lejátszókon sem játszhatók le.
Ingyenes  Az Avi Previewer 2.2.7 egy olyan program, amely képes megtekinteni a nem teljesen letöltött vagy egyszerűen sérült avi fájlokat, amelyek nem játszhatók le hagyományos lejátszókon, vagy hibásak. Az Avi Previewer program lehetővé teszi a sérült fájlok javítását, visszaállítását törlés vagy az archívumból való helytelen kibontás után és hasonlók.
Az Avi Previewer 2.2.7 egy olyan program, amely képes megtekinteni a nem teljesen letöltött vagy egyszerűen sérült avi fájlokat, amelyek nem játszhatók le hagyományos lejátszókon, vagy hibásak. Az Avi Previewer program lehetővé teszi a sérült fájlok javítását, visszaállítását törlés vagy az archívumból való helytelen kibontás után és hasonlók.
Ingyenes  Az Advanced ZIP Password Recovery 4.00 egy olyan program, amely képes visszaállítani az elveszett jelszavakat ZIP archívumokhoz.
Az Advanced ZIP Password Recovery 4.00 egy olyan program, amely képes visszaállítani az elveszett jelszavakat ZIP archívumokhoz.
 1. képernyőkép.
1. képernyőkép. Közvetlenül a program elindítása után DBF helyreállítási eszköztár megnyílik egy ablak a visszaállítandó dbf fájl kiválasztásához. A kívánt fájl kiválasztásának három módja van:
A tábla a dbf fájlon kívül tartalmazhat egy olyan fájlt is, amely MEMO típusú mezőkből származó információkat tartalmaz. Az ilyen fájlok neve általában megegyezik a dbf tábla nevével és a FoxPro táblák esetében az fpt kiterjesztéssel vagy a dBase táblák esetében a *.dbt kiterjesztéssel.
jegyzet Megjegyzés: Ha a sérült dbf fájl MEMO típusú mezőket tartalmaz, de az fpt vagy dbt fájl nincs megadva, a DBF Recovery Toolbox csak a fő táblafájlban lévő mező szerkezetét állítja vissza, és abból a mező fájljára mutató hivatkozásokat. . A külső fájlban található információk azonban nem kerülnek feldolgozásra. Így, ha a MEMO fájl nem sérült, a visszaállított táblával normál további munkavégzés lehetséges. Ha azonban magán a dbf táblán kívül az fpt vagy dbt fájl is megsérült, és nem állt helyre, akkor működés közben hibák léphetnek fel.
A visszaállítandó táblázatfájl kiválasztása után a munka folytatásához kattintson az Elemzés gombra, amely a program ablakának alján található.
Ha hiba történt a táblafájl nevének vagy elérési útjának megadásakor, a program figyelmeztetést ad. Kérjük, válassza ki a helyreállítandó fájlt! (Kérjük, válasszon egy fájlt a visszaállításhoz!) és a táblaszerkezet-elemzési folyamat nem indul el.
 2. képernyőkép.
2. képernyőkép. Amikor a forrástábla szerkezetének és adattartalmának megtekintésére lép, a program egy ablakot jelenít meg, amely figyelmezteti az adat-helyreállítási folyamat kezdetére El kívánja indítani a helyreállítást? (Szeretnéd elkezdeni a gyógyulást?). Ha módosítani kell a dbf fájl nevét vagy elérési útját, vagy MEMO fájlt kell hozzáadnia a kijelöléshez, kattintson a Nem gombra, és a Vissza gombbal térjen vissza a fájlkiválasztó ablakba.
Ha minden fájl helyesen van megadva, kattintson az Igen gombra a párbeszédablakban. A gombra kattintás után a program megkezdi a dbf táblafájl és a további MEMO mezőfájlok elemzését.
Ha a forrástábla szerkezetének elemzése során MEMO mezőket találtunk, de az fpt vagy dbt fájlt - az ilyen mezők tárolására szolgáló - nem adták meg, akkor a program ilyen típusú fájlokat keres a forrás nevével megegyező néven. fájlt abban a könyvtárban, ahonnan beolvassa. Érzékeléskor a program megjelenít egy ablakot, amely javaslatot tesz a fájl használatára a táblázat elemzésekor.
Az információk elemzése és helyreállítása során a program DBF helyreállítási eszköztár:
- Beolvassa a fájl fejlécét, azonosítja a tábla mezőinek nevét és típusát, és meghatározza azokat az eltolásokat, amelyeknél a rekordok fizikailag kezdődnek a forrásfájlban.
- Azonosítja az egyes rekordok kezdetét a forrástáblázatban, és kibontja a rekordok összes mezőjét a forrásfájlból. Ha a tábla MEMO típusú mezőket tartalmaz, azonosítja a táblarekordokban található hivatkozásokat az ezen mezők fájljában tárolt adatok címére. Maga a MEMO fájl nincs feldolgozva.
- Ha a MEMO mezőkhöz (fpt vagy dbt) társított fájl került megadásra, a program elemzi annak szerkezetét, és azonosítja a fő tábla hivatkozásainak megfelelő fájlrekordokat.
Információ visszaállításkor a képernyő alján megjelenik egy folyamatjelző sáv, amellyel felmérheti, hogy az adat-helyreállítás melyik szakaszában van.
A sérült dbf fájl elemzésének befejezése után a visszaállított információ táblázat formájában jelenik meg az ablak fő munkaterületén. A képernyőn megjelenő táblázat oszlopai a forrásfájl mezőinek, a táblázat sorai pedig a rekordjainak felelnek meg.
Ha a fájl olyan súlyosan megsérült, hogy a program nem tud róla információt visszanyerni, akkor az ablak alján megjelenik a Fájl küldése a fejlesztőknek gomb, amellyel a sérült fájlt elküldheti a program fejlesztőinek e. -mail a részletesebb elemzéshez és helyreállításhoz. Ezenkívül bármikor elküldheti a fájlt elemzésre a fejlesztőknek a Műveletek menü Forrásfájl küldése elemével.
A helyreállított információk megtekintése után a program ablakának alján található Tovább gombra kell kattintania, hogy továbblépjen a helyreállított fájl mentési szakaszába.
 3. képernyőkép.
3. képernyőkép. Amikor az eredeti dbf fájllal és az összes csatolt fájllal dolgozik, azokon nem történik változás. Minden munka a számítógép RAM-jában található információk másolatával történik. Ezért a helyreállított adatokkal való további munkához azokat lemezre kell menteni.
Ugyanakkor az eredeti fájlból visszaállított információk mentése csak a program regisztrált verziójában lehetséges. A próbaverzióban csak a 2. szakaszban tekintheti meg az információkat.
Az információk mentéséhez háromféleképpen választhat ki egy fájlt:
- Írja be az elérési utat és a fájlnevet a Javított fájlnév (.dbf): kombinált mezőbe, amely az ablak fő munkaterületén található. Amikor megnyit egy ablakot a mentendő fájl kiválasztásához, a program automatikusan kitölti a beviteli mezőt. Alapértelmezés szerint a visszaállított dbf fájlt ugyanabba a mappába javasoljuk elmenteni, ahonnan az eredeti fájl került, de az eredeti fájl nevéből és a _repaired utótagból álló névvel. Azaz, ha az example.dbf fájlt használtuk, a program felajánlja annak mentését example_repaired.dbf néven.
- Menteni kívánt mappa és fájlnév kiválasztása a szabványos fájlmentési párbeszédpanelen. A fájlválasztó párbeszédpanel hívógombja a kombinált mező jobb oldalán található. Egy párbeszédablak megnyitásakor az a könyvtár, ahonnan a forrásfájl beolvasásra került, valamint a fent leírt elv szerint összeállított fájlnév is használatos.
- Fájl kiválasztása a beviteli mező legördülő listájából. A táblafájlokkal való munka során a program DBF helyreállítási eszköztár beállításaiban tárolja a korábban elmentett fájlokról szóló információkat, és szükség esetén ezek a nevek és fájl útvonalak újra felhasználhatók.
A mentett fájl elérési útjának és nevének megadása után a helyreállított információk mentéséhez kattintson a Mentés gombra, amely a program ablakának alján található.
Ha a Javított fájlnév (.dbf): mezőben megadott könyvtár nem létezik, a Könyvtár nem létezik figyelmeztetés jelenik meg, a fájl nem kerül mentésre, és a program a menteni kívánt fájl kiválasztásának szakaszában marad. .
Ha a mezőben megadott fájl már létezik, akkor a program felszólítja a felülírásra. Át akarja írni a meglévő fájlt? (Felül akar írni egy meglévő fájlt?). Ha megnyomja a Nem gombot, a program szintén a fájlkiválasztási szakaszban marad. Ha megnyomja az Igen gombot, vagy ha a fájl még nem létezik, a DBF Recovery Toolbox a helyreállítási eredmények megtekintésének szakaszába lép.
 4. képernyőkép.
4. képernyőkép. A program a forrásfájlból kiolvasott információkat bármilyen formátumban el tudja menteni: dBase III-IV, FoxPro 3.x (vagy újabb). Ne feledje azonban, hogy amikor egy dokumentumot egy korábbi verziójú formátumba ment, előfordulhat, hogy egyes, a mentett fájl verziójával nem kompatibilis adatok elvesznek vagy megsérülnek.
A mentett dokumentum formátumát a Kimeneti DBF-fájl verziójának kiválasztása: legördülő listamező segítségével lehet kiválasztani (Válassza ki a kapott DBF-fájl verzióját).
Amikor megnyitja a mentett dokumentum formátumának kiválasztására szolgáló ablakot, a program automatikusan felajánlja, hogy a helyreállított dokumentumot az eredeti dokumentumnak megfelelő formátumban mentse el. Ha a forrásfájl olyan súlyosan megsérült, hogy nem lehetett meghatározni a verzióját, a program alapértelmezés szerint felajánlja a fájl mentését a formátum legújabb elérhető verziójában.
A mentett dokumentum formátumának beállításainak elvégzése után az adatok visszaállításának és mentésének folyamatához kattintson a Fájl mentése gombra, amely a program ablakának alján található.
Ha szükséges, a Vissza gombra kattintva visszatérhet a menteni kívánt fájl kiválasztására szolgáló oldalra.
5. képernyőkép. A munka ezen szakaszában az ablak fő munkaterületén lévő program információkat jelenít meg az összes fájlról, amelyet a munka ebben a munkamenetében visszaállítottak. Az információ a következőkből áll:
- a visszaállítandó fájl neve és elérési útja;
- annak a fájlnak a neve és elérési útja, amelybe a helyreállított információkat mentette;
- a helyreállított rekordok száma;
- a dbf táblafájl visszaállításának időpontja.
A napló megtekintése után a programablak alján található Vissza gombbal visszaléphet a program ablakának alján található beállítások módosításához (a helyreállított fájl mentése más néven, másik fájl kiválasztása helyreállításhoz stb. .).
Ha végzett a programmal, a Befejezés gombra kattintva kiléphet, vagy egyszerűen bezárhatja a program ablakát.
munka vége
A napló áttekintése után a Kilépés gombra kattintva, vagy a Fájl menü Kilépés parancsával lehet kilépni. Lehetőség van arra is, hogy a Bak gomb (Vissza) segítségével visszatérjen a program első oldalára, és válasszon egy másik fájlt a helyreállításhoz. Felhívjuk figyelmét, hogy ebben az esetben a fájl elmentésekor a visszaállított fájl neve és mappája nem változik automatikusan, ezeket manuálisan kell módosítania, vagy a párbeszédpanelen kell kiválasztania.