Comment récupérer le fichier fpt dbf. Récupération de données. Description de la récupération de fichiers par l'outil OfficeRecovery for DBF Online
Lire aussi
Des solutions d'affaires
Si l'utilisation d'un service de récupération en ligne n'est pas possible, vous pouvez télécharger l'un des utilitaires suivants :
En plus de la possibilité de récupérer des informations à domicile, ils offrent également des options illimitées pour récupérer un grand nombre de fichiers, un support professionnel et de nombreuses autres options utiles pour les utilisateurs en entreprise.
Guide vidéo pour l'utilisation du service OfficeRecovery Online
À propos d'OfficeRecovery pour DBF Online
OfficeRecovery for DBF Online répare les bases de données DBF (dbf) corrompues.
Versions prises en charge de Visual FoxPro :
9.0, 8.0, 7.0, 6.0, 5.0 et 3.0
Les données récupérées sont enregistrées dans une nouvelle base de données Visual FoxPro.
Une fois la récupération de fichier terminée, vous pouvez évaluer les résultats de la démonstration et vous inscrire pour obtenir des résultats gratuits ou les acheter immédiatement. Si le fichier n'a pas pu être récupéré, vous pouvez commander son analyse par notre équipe expérimentée de spécialistes.
Exemples d'utilisation
Le service de réparation de fichiers DBF corrompus peut être utilisé lorsqu'un fichier dbf ne peut pas être ouvert dans Microsoft Visual FoxPro et que vous voyez des erreurs ou des avertissements lors de l'ouverture.
Afin de récupérer rapidement un fichier dbf endommagé, téléchargez la base de données dbf sur notre service de récupération cloud en utilisant le formulaire sur cette page.
Il est important de noter que si le processus de récupération réussit, vous recevrez un fichier dbf prêt à l'emploi. Vous pouvez obtenir une base de données dbf entièrement restaurée en choisissant des options payantes ou gratuites.
Caractéristiques standards:
- Prise en charge des bases de données Microsoft Visual FoxPro, dBASE, FoxBASE DBF
- Restaurer la structure et les données de la table
- Créer une nouvelle base de données (.dbf) avec les données récupérées
- Facile à utiliser, aucune compétence particulière requise
Description de la récupération de fichiers par l'outil OfficeRecovery for DBF Online
Les bases de données dbf corrompues sont des fichiers qui deviennent soudainement inutilisables et ne peuvent pas être ouverts avec Microsoft Visual FoxPro. Il existe un certain nombre de raisons pour lesquelles un fichier dbf peut être corrompu. Et dans certains cas, il est possible de réparer et de restaurer un fichier dbf (Visual FoxPro 9.0, 8.0, 7.0, 6.0, 5.0, 3.0) endommagé.
Si votre base de données dbf devient soudainement corrompue ou indisponible pour l'ouverture dans le programme avec lequel elle a été créée, ne désespérez pas ! Vous n'avez plus besoin d'acheter un logiciel coûteux pour réparer un seul fichier dbf cassé. OfficeRecovery for DBF Online vous présente un nouveau service en ligne qui vous aidera à récupérer instantanément une base de données dbf corrompue. Il vous suffit de télécharger le fichier dbf corrompu à l'aide d'un navigateur, d'évaluer la qualité de la récupération des résultats de la démonstration et de choisir la solution qui vous convient le mieux.
OfficeRecovery Online pour DBF prend en charge Microsoft Visual FoxPro 9.0, 8.0, 7.0, 6.0, 5.0, 3.0. Les données récupérées sont enregistrées dans une nouvelle base de données Visual FoxPro.
OfficeRecovery pour DBF Online propose des options gratuites et payantes pour obtenir des résultats de récupération complets. L'option gratuite suppose que les résultats complets peuvent être obtenus gratuitement dans un délai de 14 à 28 jours. Tout ce que vous avez à faire est de vous inscrire pour obtenir des résultats gratuits une fois le processus de récupération de fichier dbf terminé. Si vous avez besoin d'obtenir le fichier dbf restauré immédiatement, instantanément, vous devez choisir une option payante au lieu d'une option gratuite.
Que faire si votre fichier dbf ne contient pas de données de récupération ? Vous pouvez commander une analyse non remboursable de votre dossier par notre équipe technique expérimentée. Dans certains cas, la récupération des données n'est possible que manuellement.
Les personnes à la recherche de conditions de travail confortables pour eux ne pensent souvent pas à la sécurité et à la sûreté de leurs données et sont tôt ou tard confrontées au problème de leur perte. Considérons la demande du client avec USB Flash 2Gb Transcend. Selon le client, un jour où le lecteur a été installé dans le port USB de l'ordinateur, il a été proposé de le formater. Selon le client, il a refusé et s'est tourné vers l'administrateur système pour obtenir de l'aide. L'administrateur système, ayant découvert que l'ordinateur "se bloque" lorsqu'une clé USB est connectée, n'a rien trouvé de mieux que d'accepter la suggestion du système d'exploitation de la formater ( ne le fais jamais !). Ensuite, l'administrateur système a utilisé le populaire programme de récupération automatique R-Studio. Le résultat de son travail sous la forme de dossiers sans nom a été copié sur le client sur un autre lecteur. Lors de la visualisation du résultat, le client a constaté qu'environ un quart des fichiers ne pouvaient pas être ouverts et, pire que tout, 1C Accounting 7.7 a refusé de démarrer avec la base de données restaurée, se référant à l'absence de fichiers.
Il s'est avéré que le client avait une copie de sauvegarde de cette base de données datant de plus d'un an.
La première étape pour résoudre de tels problèmes est la création d'une copie bloc par bloc du lecteur d'origine (ou, comme il est d'usage d'écrire à partir du moment où seuls les lecteurs de disquette et de disque dur étaient des supports, secteur par secteur) . Lors de la soustraction, une vitesse de lecture instable est détectée, ce qui indique une usure importante de la mémoire NAND (la lecture multiple des pages mémoire NAND par le contrôleur NAND et la correction des erreurs dues aux codes de correction d'erreur redondants (ECC) est une opération très gourmande en ressources, ce qui affecte finalement la vitesse de lecture). S'il y a des sections non lues, il est nécessaire de les remplir avec un motif, ce qui nous aidera plus tard à identifier les fichiers qui n'ont pas été lus dans leur intégralité.
Ensuite, nous procédons à l'analyse. Il est nécessaire d'établir quel système de fichiers et dans quelles limites se trouvait auparavant sur la clé USB. Autrement dit, vous devez rechercher des expressions régulières spécifiques à diverses métadonnées du système de fichiers, mais avant de commencer, vérifions une variante simple qui suppose que les limites de partition sont les mêmes. Pour ce faire, définissez les paramètres actuels du système de fichiers.
Ouvrez LBA 0 (0x0 dans le fichier image) et vérifiez la présence d'une table de partition ou la présence du secteur Boot du système de fichiers.

riz. 2
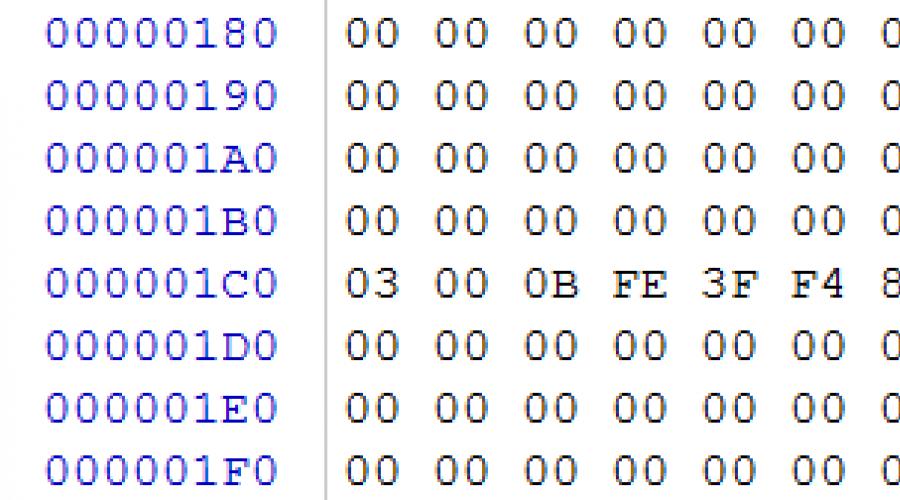
Dans notre cas, nous voyons par décalage 0x1C2 de type de partition 0x0B, ce qui signifie qu'il existe actuellement une partition FAT32 sur la clé USB, qui commence par le secteur 0x80 (DWORD au décalage 0x1C6), 0x003C2000 secteurs (DWORD au décalage 0x1CA ). Nous allons au secteur de démarrage de la section décrite dans le secteur 0x80 (dans le fichier image, octets 0x10000)

riz. 3
Il est nécessaire de calculer le point de référence de départ, c'est-à-dire la place du cluster zéro, par rapport auquel l'espace est calculé, et également de déterminer la taille du cluster.
Pour ce faire, nous avons besoin des paramètres suivants décrits dans le secteur de démarrage (sera spécifié comme un décalage depuis le début du secteur): taille du secteur au décalage 0x0B - 0x200 (512 octets), nombre de secteurs dans le cluster au décalage 0x0D - 0x08, la taille du cluster est obtenue en multipliant la taille des secteurs par le nombre de secteurs dans le cluster 0x08*0x0200=0x1000 (4096 octets), nombre de secteurs réservés avant la première copie des tables FAT - par décalage 0x0E=0x01FE (510 secteurs) , nombre de copies FAT - par décalage 0x10=0x02, taille d'une copie FAT - par décalage 0x24=00000F01 (3841 secteurs). En utilisant les paramètres obtenus, nous allons calculer la position du début de la zone de données : 0x10000+0x01FE*200+0x00000F01*2*200=0x410000 (secteur 8320). Une petite prise des créateurs de FAT32 est que pour le moment nous avons calculé le début de la zone de données pour la partition FAT32, mais ce n'est pas un point de référence zéro, car les deux premières entrées de la table FAT sont réservées et ne sont pas utilisés aux fins prévues, et donc le point zéro est le début de la zone de données moins 2 clusters. Dans ce cas, ce sera 0x410000-0x1000*2=0x40E000 (secteur 8318).
Vérifions l'absence d'enregistrements dans la table d'allocation de fichiers et effectuons la procédure de comparaison des copies pour les écarts.

Riz. 4
La comparaison des copies FAT a montré qu'il n'y avait pas de divergences. Une analyse du contenu d'une des copies FAT a montré que, selon le tableau, un seul cluster est rempli sur la partition.
L'étape suivante consiste à évaluer le répertoire racine pour les entrées supprimées. La position du premier cluster de répertoire racine est indiquée dans le secteur de démarrage au décalage 0x2C=0x00000002. Pour le deuxième cluster, le FAT affiche FF FF FF 0F, ce qui signifie la fin de la chaîne, c'est-à-dire que le répertoire racine se compose d'un cluster.

riz. 5
A l'adresse calculée ci-dessus, nous voyons le répertoire racine (répertoire racine), qui contient une seule entrée de 32 octets. Au décalage 0x0B, nous voyons la valeur 0x08, qui indique le type d'enregistrement - l'étiquette de volume. Le fait que les tables d'allocation de fichiers soient remplies de zéros et qu'il n'y ait aucune indication d'autres entrées dans le répertoire racine indique que la partition a été formatée.
Pour vérifier l'hypothèse que la partition n'a pas été recréée et que tous les paramètres du système de fichiers sont corrects, il faut rechercher l'expression régulière 0x2E 0x2E 0x20 0x20 0x20 0x20 0x20 0x20 avec un décalage dans le secteur 0x20 (cette expression indique le début de le répertoire FAT32).

riz. 6
Lors de la recherche d'une expression régulière, vous devez vous assurer qu'il s'agit bien d'un répertoire, selon d'autres signes, car dans certains cas, une correspondance est possible et l'expression régulière trouvée n'est pas un élément de répertoire. Selon les informations de la Fig. 6, on peut dire que ce répertoire commençait par le cluster 3 (le numéro de cluster actuel du répertoire DWORD est contenu dans WORD à l'offset 0x1A (partie inférieure) et WORD à l'offset 0x14 (partie supérieure)) et était décrit dans le répertoire racine, puisque les décalages 0x3A et 0x34 contiennent des zéros (le cluster initial du répertoire parent). Vérifions si le numéro de cluster de ce répertoire correspond au point zéro du système de fichiers créé après formatage. Pour ce faire, multipliez le numéro de cluster de répertoire par la taille du cluster actuel et ajoutez 0x03*0x1000+0x40E000=0x411000 au point zéro. Comme vous pouvez le voir, l'adresse de facturation correspond à l'emplacement réel. Il est possible de définir le nom de ce répertoire uniquement si auparavant le répertoire racine se composait de plusieurs clusters et que le lien vers ce répertoire ne se trouvait pas dans le premier cluster, car le contenu du premier cluster a été complètement détruit lors du formatage avec les tables d'allocation des fichiers.

riz. 7
Nous répétons toutes les vérifications : 0x04*0x1000+0x40E000=0x412000. Encore une fois, nous voyons la correspondance de la position du répertoire avec les paramètres du système de fichiers actuel. Mais, à côté de cela, nous voyons qu'il existe un numéro de cluster du répertoire parent 0x03, ce qui indique que ce répertoire était imbriqué, et en regardant la fig. 6, vous pouvez définir le nom du répertoire, qui est illustré à la Fig. 7. Ainsi, selon la fig. 6, au décalage 0x4B, nous voyons la valeur 0x10 - cela signifie que cette entrée pointe vers un répertoire, et aux décalages 0x5A et 0x54, le nombre 0x00000004 est un pointeur vers le 4ème cluster. Au décalage 0x40 - le nom du répertoire "BIN". C'est ainsi que l'interconnexion des répertoires dans une partition FAT endommagée est établie. Après avoir effectué quelques vérifications supplémentaires des répertoires dans différentes parties de l'image, nous pouvons enfin conclure que ce lecteur a été formaté dans les limites du système de fichiers précédent et que les paramètres du système de fichiers nouvellement créé ont été hérités du précédent, c'est-à-dire d'autres opérations d'analyse doivent être effectuées au sein de la partition, décrites dans la table de partition, en tenant compte des paramètres du système de fichiers actuel.
Sachant que la base de données 1C, constituée de fichiers DBF, doit contenir le fichier de configuration 1CV7.MD, recherchons la séquence 0x31 0x43 0x56 0x37 0x20 0x20 0x20 0x20 0x4D 0x44. Afin de réduire le nombre de résultats délibérément faux, il est préférable de rechercher dans des blocs de 32 octets avec un décalage nul.

Riz. 8
Ainsi, on retrouve tous les répertoires contenant un pointeur vers le fichier 1CV7.MD. Dans notre cas, un seul répertoire de ce type a été trouvé, ce qui suggère que nous avons trouvé le premier cluster du répertoire requis. Ceci est suivi d'une analyse de la position des répertoires parents, jusqu'au répertoire racine. Chaque répertoire trouvé est écrit dans la table FAT (d'abord en tant que répertoire d'un cluster, en écrivant FF FF FF 0F pour l'entrée de table correspondante). De plus, un lien vers un objet enfant est écrit dans le répertoire racine.
Au stade actuel, nous copierons les fichiers trouvés en supposant leur continuité, car les deux copies FAT ne contiennent pas d'informations de fragmentation (rappelons qu'elles ont été irrémédiablement détruites par l'administrateur système à la suite d'un formatage imprudent de la clé USB). Après avoir copié le répertoire de la base de données 1C, nous analysons le nombre de fichiers. Étant donné que le fragment de répertoire avait une taille de cluster, nous n'avons pas extrait plus de 126 fichiers, ce qui est clairement beaucoup moins que ce qu'il devrait être dans un répertoire contenant des fichiers DBF et CDX liés à la base de données 1C. Approximativement le même résultat sera donné par les programmes de récupération automatique, comme en témoigne le résultat obtenu par l'administrateur système grâce à l'utilisation de R-Studio.
Parmi les fichiers extraits figurent 1CV7.MD (fichier de configuration) et 1CV7.DD (fichier de dictionnaire de données). Après avoir effectué le contrôle d'intégrité, nous allons créer un dossier temporaire sur notre disque, où nous placerons 1CV7.MD. Spécifiez ce chemin lors de l'ajout d'une nouvelle base de données et ouvrez le configurateur, à travers lequel nous allons créer une base de données propre basée sur cette configuration. Comparons le fichier DD généré avec celui restauré, si les descriptions et le nombre de répertoires sont identiques, aucune action supplémentaire n'est requise, et ayant une liste complète des fichiers, vous pouvez commencer à rechercher les fragments restants du répertoire de la base de données 1C . Pour ce faire, vous devez rechercher des séquences de codes de caractères ASCII utilisés dans les noms de fichiers DBF manquants. Au fur et à mesure que des fragments du répertoire sont trouvés, ajoutez la suite de la chaîne à la table d'allocation de fichiers. Après chaque opération d'ajout de la chaîne de répertoires, copiez les fichiers et analysez dans quelle mesure le nombre de fichiers DBF manquants a diminué, puis formez à nouveau une séquence de codes de caractères ASCII pour rechercher le fragment suivant.

riz. 9
Vous devez également vous rappeler que lors de l'écriture d'une chaîne de fragments de répertoire dans la table d'allocation de fichiers, vous devez analyser les fragments afin que les enregistrements LFN soient joints. Dans le cas d'entrées courtes uniquement, la chaîne peut être écrite avec n'importe quel ordre de fragments.
Dans ce cas, après avoir recherché 5 séquences, nous avons réussi à trouver tous les autres fragments du répertoire avec la base 1C.
Après que la chaîne complète des fragments de répertoire a été construite, nous recopions tous les fichiers de la base 1C avec l'hypothèse de leur continuité. Les informations utilisateur sont contenues dans les fichiers DBF, il est donc nécessaire de vérifier leur intégrité.
La principale méthode de vérification de l'intégrité d'un fichier DBF consiste à vérifier les informations contenues dans l'en-tête du service et si le contenu du fichier correspond à la description dans l'en-tête.

riz. dix
Initialement, l'en-tête est évalué : sa longueur, spécifiée au décalage 0x08, est vérifiée pour voir si le décalage spécifié dans celui-ci mène au marqueur de fin 0x0D. Les enregistrements de champ de base, à partir du décalage 0x20, sont décrits par des enregistrements de 32 octets, dans lesquels le nom du champ suit au décalage 0x00, le type de champ suit au décalage 0x0B et la taille du champ suit au décalage 0x10. La somme des tailles de champ +1 (un octet supplémentaire pour chaque enregistrement dans la base de données est le statut de l'enregistrement dans le DBF) doit être égale au contenu au décalage 0x0A (la taille d'un enregistrement dans la base de données). Dans la figure des fichiers DBF, nous voyons les longueurs de champ suivantes : 0x09+0x10+0x10+0x10+0x10+0x10+0x01=0x5A.
Vérifions l'exactitude de la taille du fichier. Pour ce faire, nous multiplions le nombre d'enregistrements indiqués dans l'en-tête à l'offset 0x04 par la taille d'un enregistrement dans la base de données à l'offset 0x0A, suivi d'une addition avec le contenu à l'offset 0x08.
0x00000003*0x005A+0xE1=0x01EF. Le décalage résultant doit contenir le marqueur de fin de fichier 0x1A.
Pour contrôler l'intégrité du contenu des champs, vous pouvez utiliser la méthode visuelle.
Dans cette option d'affichage, vous devez faire défiler le contenu des enregistrements du début à la fin. Si le remplissage est homogène, que chaque champ contient des types de données typiques de ceux décrits dans l'en-tête et qu'il n'y a pas de contenu étranger, alors après consultation du fichier DBF, nous pouvons conclure que son contenu est correct.
Si vous trouvez un contenu qui ne correspond pas à la description du champ dans l'en-tête de la base de données, vous devez déterminer l'emplacement exact à partir duquel les données incorrectes commencent.

Riz. 12
Sur la base de la description des champs dans l'en-tête et du contenu d'un fichier DBF spécifique, il est possible de former des séquences ASCII présumées qui doivent être situées aux décalages spécifiés dans les fragments manquants. S'il n'y a pas de bases de données du même type sur l'un des lecteurs (y compris les copies de fichiers de la même base de données), cette méthode vous permettra de trouver relativement rapidement tous les fragments manquants dans l'image du lecteur. Séparément, nous notons que des difficultés supplémentaires surgiront pour joindre des fragments si la taille de l'enregistrement dans le fichier DBF est petite ou multiple de 16. S'il existe d'autres bases de données du même type, la tâche sera beaucoup plus compliquée (cette affirmation est vraie à toutes les étapes du travail, en commençant par la recherche de fragments du répertoire souhaité).
Il est nécessaire de vérifier l'intégrité de chaque fichier DBF, dont il existe plusieurs centaines dans une base de données 1C. Après avoir passé toutes les vérifications et collecté les fragments de fichiers, une dernière vérification suivra dans le configurateur 1C Enterprise.

riz. 13
Idéalement, selon les résultats du test, tous les éléments marqués dans les cases à cocher devraient réussir. Si des erreurs sont trouvées sur les deux premiers points, il est alors nécessaire d'analyser le journal des erreurs dans le configurateur et de savoir quels fichiers DBF contiennent des données étrangères qui n'ont pas été détectées lors des vérifications. Si des erreurs sont détectées lors de la vérification de l'intégrité logique, il est à nouveau nécessaire d'analyser le journal des erreurs pour savoir si le problème réside dans la base en tant que collection ou dans les erreurs commises par les développeurs de la configuration 1C.
Faisons attention au fait que si cette clé USB n'avait pas été formatée, après l'avoir lue, la procédure de récupération des données serait beaucoup plus simple, ce qui affecterait considérablement le coût et le délai d'exécution. En conclusion, je voudrais mettre en garde tous les utilisateurs et le personnel de maintenance contre les actions imprudentes dans les situations d'urgence, qui aggravent le problème à plusieurs reprises, et souhaite également effectuer plus souvent des opérations de sauvegarde.
Précédemment posté sur Clipper Summer 87.
J'ai besoin de créer un fichier d'index CDX sur Clipper 5.3, mais je ne peux même pas créer un fichier exe.
Inséré au début du programme :
DEMANDE DBFCDX
rddSetDefault("DBFCDX")
Je lie comme dans l'exemple:
FICHIER CLIGNOTANT $(objs) SORTIE [courriel protégé] lib dbfcdx.lib
Lors de la construction, cela donne une erreur:
CLIGNOTANT : 1115 : DBFCDX.LIB(CL53INIT) : "_DBFCDX" : externe non résolu
CLIGNOTANT remplacé.
A commencé à essayer de collecter BLINKERom 6.0
le même.
Ce qui est intéressant, si au lieu de DBFCDX vous connectez DBFNDX à l'exemple, c'est-à-dire
dans un programme
DEMANDE DBFNDX
rddSetDefault("DBFNDX")
et puis
FICHIER CLIGNOTANT $(objs) SORTIE [courriel protégé] lib dbfndx.lib
tout se connecte et fonctionne bien.
Sur la deuxième question - dans mon système, j'utilise aussi CLIPPER (plus souvent) et FOXPRO (moins souvent et lié à lui, puisque FOXPRO a un défaut mortel - la dimension maximale du tableau est de 2. Pour un algorithmiste, c'est du bois de chauffage. Si je savais tout de suite, je serais généralement FOX n'a pas contacté). Mais néanmoins, plusieurs programmes sont déjà sur FOXe. Cependant, je ne comprends pas pourquoi des index communs sont nécessaires ? Dans le clipper j'utilise NDX, et sur FOXe j'utilise son putain d'IDX, DBF est courant. Le travail se poursuit séparément - chacun le sien. Ou le système est-il si monumental qu'il y a un flux continu de modifications de fichiers des deux côtés ? Je crains qu'il n'y ait pas de solution normale pour les systèmes hétérogènes qui fonctionnent si étroitement les uns avec les autres au niveau de l'index.
Et à propos des pépins dans la création de CDX Clipper, le seul conseil est de télécharger un fichier avec un cas de test minimal sans sujet (prog + DBF + description du pépin (quand et comment il se manifeste), peut-être que quelqu'un pourra accéder au fond de ce qui se passe.
Au moins je me suis intéressé.
Réponse à la lettre précédente. Bien sûr, je lie _dbfcdx.lic, mais cela n'aide pas.
Pour réaliser l'intérêt suscité, vous pouvez prendre le premier .DBF disponible et le construire en utilisant n'importe quelle expression d'index.CDX avec un clipper et un renard.
La taille des index sera différente, sans parler du contenu d'index supposés identiques.
À renard il y a un avantage sur tondeuse: cela fonctionne beaucoup plus rapidement avec la base de données, et j'ai une tâche pour 400 000 abonnés, qui doivent être massivement comptés chaque mois. Fox aurait aidé ici, sinon je cours autour de la direction, à la recherche d'ordinateurs qui peuvent être laissés pour la nuit pour le calcul. Donc, un tel groupe est parfois très utileKSS: ... j'ai une tâche pour 400 000 abonnés ... ... sinon je cours autour de la gestion, je cherche des ordinateurs qui peuvent être laissés pour la nuit pour le calcul. Bien sûr, ce n'est pas le sujet, mais avec un tel nombre d'abonnés et, par conséquent, une grande responsabilité, il est logique d'allouer un serveur séparé. Ensuite, vous pouvez exécuter des tâches de service dessus. Mon programme Clipper, qui a déjà 13 ans, fait exactement cela.
Andreï : Urri écrit : J'ai une tâche pour 400 000 abonnés, j'avais une tâche pour 150 000 abonnés. J'ai compté toute la nuit. Ensuite, l'algorithme était limitant (il l'a fait pendant longtemps) a commencé à compter en 5 heures. Déménagé au port. Considère environ 1,5 à 2 heures. Alors Fox, Clipper - il est temps de passer aux compilateurs normaux. Et si la direction ne comprend pas votre travail, vous devez changer de direction ou abandonner le travail. Plus tôt vous comprendrez cette vérité, plus il vous sera facile de vivre.
j'ai regardé xPort au début de sa carrière, mais ensuite il n'a pas trouvé l'opportunité d'y attacher ADS, sans quoi maintenant je ne peux pas imaginer travailler pour mes grandes bases de données (l'exactitude des index et des transactions coûte cher). Si vous savez comment vous lier d'amitié avec ADS, dites-le-moi et donnez-moi un lien pour obtenir un xHarbor stable et fonctionnel. Je vais essayer d'aborder la question du règlement - peut-être que ça ira mieux.
Passer à un compilateur normal, dites-vous ? Ceci malgré le fait que 60% des machines (sur 300) sont telles que la moitié d'entre elles w98 peuvent à peine tirer, et l'autre moitié - w95 ne prend en charge que les moniteurs 14 "et une résolution de 640 * 480 ... Quoi, sur VBasic-4 ? il est difficile de changer la gestion maintenant - il y a une crise partout, cependant, les employeurs de programmeurs ne favorisent pas les programmeurs maintenant. Ou est-ce différent dans votre région ? Pasha : Il y a un support Ads dans le port. Harbour s'est lié d'amitié avec Ads encore plus tôt qu'avec DBFCDX, c'est-à-dire que le travail rdd pour Ads était prêt lorsque DBFCDX était encore bogué
Andrey : Urri écrit : que la moitié d'entre eux w98 peut à peine tirer, et l'autre moitié - w95 ne prend en charge que les moniteurs 14" et une résolution de 640*480... Quoi, sur VBasic-4 ? et ce sera plus rapide. J'ai aussi J'ai beaucoup douté avant, mais maintenant je me demande pourquoi personne ne me l'a montré (xHarbor) avant !!! J'ai déjà apporté 5 systèmes à moi et 3 à d'autres !!!
Urri : Cher (avec le modérateur Pasha) ! Vous ne taquinez pas, mais donnez un lien vers une version stable de xHarbor et rdd pour ADS et où vous pouvez lire quelque chose. S'il te plaît. Très nécessaire
Andreï : Merde ! Il vous suffit de prendre xharbour, de télécharger la version à partir de là et c'est tout ! Je suis sur cette version depuis presque un an maintenant !
A fait un test pour Tondeuse 5.3, Clignotant 1.0 et FoxPro 8.
Il existe deux fichiers identiques testclp.dbf et testfox.dbf
avec les champs NOM, NOM1 - C(10), NUMÉRO, NUMÉRO1, SUMMACLP, SUMMAFOX - N(10).
Programme spécial Fill.exe<кол-во записей>remplit ces deux fichiers comme ceci :
NAME=A000000001, NUMBER1=1 pour la 1ère entrée,
NAME=A000000002, NUMBER1=2 pour la 2ème entrée, etc.
Les champs NOM1 et NUMERO1 sont remplis de la même manière, mais dans l'ordre inverse, c'est-à-dire les valeurs spécifiées auront les dernières et avant-dernières entrées, et ainsi de suite. Les champs SUMMAFOX et SUMMACLP ne sont pas renseignés par le programme fill.exe.
De plus, il existe deux programmes similaires pour CLIPPER (testclp.exe) et pour FoxPro (testfox.exe). Pour testclp.exe (clipper), la tâche est la suivante :
a) indexer le fichier testclp.dbf par le champ NAME (balise FLD)
et par le champ NAME1 (balise FLD1), créant ainsi l'index "propre" testclp.cdx ;
b) parcourir le fichier testfox.dbf et, en utilisant le fichier d'index créé en a) pour chaque ligne de testfox.dbf par la valeur NAME, trouver la ligne dans le fichier testclp.dbf qui a le même champ NAME et ajouter le NUMBER champ de ce fichier au champ SUMMACLP de testfox.dbf ; puis, en utilisant la même valeur NAME, recherchez une autre ligne dans le fichier testclp.dbf qui a le même champ NAME1 et soustrayez testfox.dbf du champ SUMMACLP.
c) parcourir le fichier testclp.dbf et, à l'aide du fichier d'index testfox.cdx créé par un autre programme (testfox.exe - FoxPro),
pour chaque ligne de testclp.dbf par valeur NAME trouver la ligne
dans le fichier testfox.dbf, qui a le même champ NAME et ajoutez le champ NUMBER
de ce fichier au champ SUMMACLP de testclp.dbf ; puis par la même valeur NAME
trouver une ligne dans le fichier testfox.dbf qui a le même champ NAME1 et
soustraire du champ SUMMACLP testclp.dbf.
Pour testfox.exe (FoxPro) une tâche similaire :
UN) indexer le fichier testfox.dbf par champ NAME (balise FLD)
et par champ NAME1 (tag FLD1), lors de la création de "votre" index testfox.cdx ;
b) parcourir le fichier testclp.dbf et, en utilisant le fichier d'index créé en a) pour chaque ligne de testclp.dbf par la valeur NAME, trouver la ligne dans le fichier testfox.dbf qui a le même champ NAME et ajouter le NUMBER champ de ce fichier au champ SUMMAFOX de testclp.dbf ; puis, en utilisant la même valeur NAME, recherchez une ligne dans le fichier testfox.dbf qui a le même champ NAME1 et soustrayez testclp.dbf du champ SUMMAFOX.
c) parcourir le fichier testfox.dbf et, à l'aide du fichier d'index testclp.cdx créé par un autre programme (testclp.exe - Clipper),
pour chaque ligne de testfox.dbf par valeur NAME trouver la ligne
dans le fichier testclp.dbf, qui a le même champ NAME et ajoutez le champ NUMBER
de ce fichier au champ SUMMAFOX de testfox.dbf ; puis par la même valeur NAME
trouver une ligne dans le fichier testclp.dbf qui a le même champ NAME1 et
soustraire du champ SUMMAFOX testfox.dbf.
Ainsi, lorsqu'ils fonctionnent correctement, les deux programmes doivent ajouter et soustraire le même nombre à chaque champ de chaque fichier (bien que situés dans des enregistrements différents), et par conséquent, lorsque le système fonctionne correctement, les valeurs nulles doivent rester dans les champs SUMMACLP et SUMMAFOX dans les deux fichiers .
Le test a été effectué pour 100 000 et 400 000 enregistrements, et malgré la taille différente des fichiers d'index, il a donné le bon résultat. La seule chose est que lors de l'ajout d'entrées, l'un des fichiers d'index ("étranger") reste incorrect, par conséquent, au premier démarrage, chacun des programmes ne fonctionne qu'avec "son" index et ne fonctionne pas avec "étranger" . Après avoir exécuté le deuxième programme, les deux fichiers sont correctement indexés et les deux programmes commencent à fonctionner sans échec (de même, lorsque le nombre d'enregistrements est réduit, mais FoxPro se bloque sur une erreur sur l'index de quelqu'un d'autre, et j'ai dû appliquer le gestionnaire ON ERROR . .. Mais cela est dû au fait que la modification du nombre d'enregistrements est effectuée par fill.exe sans ouvrir les deux index, et également au fait que chacun des programmes ne réindexe pas l'index de quelqu'un d'autre (c'est-à-dire
le problème est créé artificiellement - il ne devrait pas en être autrement). Si vous autorisez FoxPro à réindexer l'index de quelqu'un d'autre, le travail normal est restauré. De plus, je n'ai pas "amélioré" le système de gestion des erreurs, de sorte que les deux programmes ne différaient pas beaucoup l'un de l'autre.
Le résultat est le suivant :
1) Au début j'avais Clipper 5.3 sans patch (et j'y travaille depuis longtemps). Il s'est vraiment écrasé : en commençant quelque part autour de 40 000 enregistrements, parfois il a bien fonctionné, parfois il s'est écrasé, parfois il s'est écrasé avec une erreur (comme si le programme avait effectué une opération illégale) au début du programme en essayant d'indexer "son" CDX. Comme conseillé ici sur le forum, j'ai fait un patch à 5.3b - tout a bien fonctionné. Mais même avant le patch, les problèmes n'étaient pas dans le sens où les index FoxPro n'étaient pas compris - sans réindexation(lorsque les deux index ont été créés par FoxPro) le traitement était normalement effectué, CLIPPER tombait lors de la création de "leurs" index.
2) pour les SGBD modernes, 400 000 enregistrements ne sont pas très nombreux. Comment
vu des résultats des tests, traitement de l'intégralité du dossier avec recherche aléatoire
prend 2-3 minutes maximum même sur des ordinateurs un peu obsolètes. Donc, 2 à 4 heures de temps sur la technologie moderne (et même 30 minutes) sont "das ist fantastisch" selon mes termes. Le problème réside probablement soit dans un algorithme non économique, soit dans des goulots d'étranglement tels que la bande passante du réseau (en raison de l'engouement pour l'architecture client-serveur, pour laquelle j'ai une attitude négative - mais c'est hors sujet). 3) Comme le montrent les résultats des tests, le temps de création d'un index est insignifiant par rapport au temps total de fonctionnement, il est donc préférable de créer de nouveaux index avant de commencer le traitement des fichiers, sans faire confiance aux "étrangers" et "propres" créés précédemment. " (sauf s'ils ne sont pas actuellement utilisés par d'autres programmes).
Chacun des programmes en cas de fonctionnement normal traitement des fichiers rapporte le temps (en secondes) requis pour :
- création d'un index "propre" (point a) ;
- traitement des fichiers par index « propre » (point b) ;
- traitement des fichiers par index « étranger » (point c) ;
- temps total de travail (plus de temps est ajouté ici pour remplir les champs
SUMMAFOX et SUMMACLP avec des valeurs nulles dans les deux fichiers).
Archive jointe :
info.doc - résultats de l'expérience d'exécution.
fill.prg - texte auxiliaire programmes sur clipper pour remplir les fichiers.
calc.prg - texte du programme clipper.
program1.prg - texte du programme FoxPro.
makefill.bat - crée fill.exe (devra ajuster un peu)
makecalc.bat - crée testclp.exe (identique).
proj1.pjx - Fichier de projet FoxPro.
testfox.dbf et testclp.dbf sont des fichiers de données (créés dans DBU).
testclp.cdx - fichier d'index créé par CLIPPER.
testfox.cdx est un fichier inex créé par FoxPro.
fill.exe- programme pour compléter les dossiers.
testclp.exe - programme CLIPPER.
testfox.exe est un programme FoxPro.
testfox.exe nécessitera un environnement d'exécution (à partir de VFP6
ne fonctionnera probablement pas, vous devrez donc utiliser le texte de program1.prg
et éventuellement corrigé.)
Pour réduire la taille de l'archive, les fichiers dbf contiennent 10 enregistrements chacun, pour des tests réels, le nombre d'enregistrements doit être augmenté.
Si CLIPPER 5.2 est disponible, vous devrez également corriger fill.prg et сalc.prg.
J'essaierai d'effectuer des tests pour CLIPPER "87, CLIPPER 5.2 et VFP6 un peu plus tard, car je ne travaille pas avec ces versions et maintenant elles ne sont pas en état de marche
(ainsi que des tests croisés comme CLIPPER 5.2<->VFP8 et CLIPPER 5.3<->VFP6).
Malgré l'apparente simplicité de la tâche, cela a tout de même pris beaucoup de temps, mais ce sont précisément ces études comparatives objectives qui m'intéressent considérablement. Le problème est très probablement soit dans un algorithme non économique.Ce n'est pas un problème, et pas un algorithme non économique. Normal, pas d'autre moyen. Pour le concept de cet algorithme, il est nécessaire de présenter un enregistrement des valeurs de 24 montants d'encaissement d'argent, 24 dates d'encaissement d'argent, 24 tarifs, 24 montants de charges, etc. en un seul enregistrement dans la base de données. Donc c'était toujours écrit par moi sur le Clipper, et je ne l'ai pas encore refait, et je ne le ferai probablement pas. J'ai vu comment sur la version 7.5 de la plate-forme 1C, ils ont implémenté l'accumulation des factures de services publics, donc il y a 9.tys. les cumuls d'abonnés ont été effectués pendant environ 5 heures. Et rien, personne ne s'est plaint.
Des programmes pour récupérer des informations perdues sur un PC.
↓ Nouveau dans la catégorie Récupération de données :
Gratuit
UndeletePlus 3.0.2.406 est une petite application qui récupère les fichiers supprimés. L'application Undelete Plus vous aidera à récupérer les fichiers perdus, y compris ceux supprimés en mode DOS, à partir de la Corbeille, de l'Explorateur Windows ou d'un lecteur réseau.
Gratuit  Scan DBF 1.6 est une application pour réparer ou restaurer des fichiers DBF endommagés. L'application Scan DBF vous aidera à récupérer les fichiers endommagés en cas de panne d'ordinateur ou de courant, lorsque la fin ou l'en-tête du fichier DBF est endommagé.
Scan DBF 1.6 est une application pour réparer ou restaurer des fichiers DBF endommagés. L'application Scan DBF vous aidera à récupérer les fichiers endommagés en cas de panne d'ordinateur ou de courant, lorsque la fin ou l'en-tête du fichier DBF est endommagé.
Gratuit  Recuva 1.42.544 est une application pratique pour récupérer des fichiers supprimés. L'application Recuva est facile à utiliser et pourra récupérer des données sans aucune configuration ou pour les utilisateurs qui n'ont jamais rencontré de programmes similaires auparavant.
Recuva 1.42.544 est une application pratique pour récupérer des fichiers supprimés. L'application Recuva est facile à utiliser et pourra récupérer des données sans aucune configuration ou pour les utilisateurs qui n'ont jamais rencontré de programmes similaires auparavant.
Gratuit  Recover My Files 4.9.4.1343 est une application de récupération de fichiers supprimés à l'aide de la corbeille du système d'exploitation Windows. En outre, l'application Recover My Files a la capacité de récupérer des fichiers perdus en raison du formatage du disque, effacés en raison d'une panne de PC, d'une panne de logiciel ou supprimés par des virus.
Recover My Files 4.9.4.1343 est une application de récupération de fichiers supprimés à l'aide de la corbeille du système d'exploitation Windows. En outre, l'application Recover My Files a la capacité de récupérer des fichiers perdus en raison du formatage du disque, effacés en raison d'une panne de PC, d'une panne de logiciel ou supprimés par des virus.
Gratuit  PC INSPECTOR File Recovery 4.0 est une application dont vous aurez besoin pour récupérer des informations si votre disque dur est endommagé. PC INSPECTOR File Recovery peut fonctionner avec les systèmes de fichiers FAT 12/16/32 ainsi que NTFS.
PC INSPECTOR File Recovery 4.0 est une application dont vous aurez besoin pour récupérer des informations si votre disque dur est endommagé. PC INSPECTOR File Recovery peut fonctionner avec les systèmes de fichiers FAT 12/16/32 ainsi que NTFS.
Gratuit  OS Backup Wizard 1.19 est une application de sauvegarde pour Windows. La particularité de cette application est sa capacité à ne pas utiliser d'espace disque inutile pour cela lors de la sauvegarde du système.
OS Backup Wizard 1.19 est une application de sauvegarde pour Windows. La particularité de cette application est sa capacité à ne pas utiliser d'espace disque inutile pour cela lors de la sauvegarde du système.
Gratuit 
Gratuit  Norton Ghost 15.0.0.35659 est une application d'archivage et de restauration de données sur des ordinateurs personnels. L'application prend en charge la sauvegarde et la restauration sans redémarrer le système.
Norton Ghost 15.0.0.35659 est une application d'archivage et de restauration de données sur des ordinateurs personnels. L'application prend en charge la sauvegarde et la restauration sans redémarrer le système.
Gratuit  Handy Backup 7.1.1 est une application pratique pour la création automatique de copies de vos données et documents, qui peuvent être stockées sur n'importe quel appareil (externe ou interne, ainsi que CD-RW) ou téléchargées sur un serveur FTP.
Handy Backup 7.1.1 est une application pratique pour la création automatique de copies de vos données et documents, qui peuvent être stockées sur n'importe quel appareil (externe ou interne, ainsi que CD-RW) ou téléchargées sur un serveur FTP.
Gratuit  GetDataBack 4.25 est un outil puissant et pratique pour récupérer les informations perdues, endommagées ou supprimées de votre disque dur. L'application GetDataBack fournit une interface intuitive et des performances améliorées.
GetDataBack 4.25 est un outil puissant et pratique pour récupérer les informations perdues, endommagées ou supprimées de votre disque dur. L'application GetDataBack fournit une interface intuitive et des performances améliorées.
Gratuit  BadCopy Pro 4.10.1215 est une application permettant de récupérer des données à partir de CD, de disquettes, de périphériques flash ou de disques durs endommagés, infectés par des virus, mal enregistrés ou présentant des erreurs. L'application BadCopy fonctionne automatiquement lorsque vous spécifiez le répertoire de récupération, avec la possibilité de travailler avec différents formats de fichiers graphiques, texte et exécutables, d'archives et d'autres types de fichiers.
BadCopy Pro 4.10.1215 est une application permettant de récupérer des données à partir de CD, de disquettes, de périphériques flash ou de disques durs endommagés, infectés par des virus, mal enregistrés ou présentant des erreurs. L'application BadCopy fonctionne automatiquement lorsque vous spécifiez le répertoire de récupération, avec la possibilité de travailler avec différents formats de fichiers graphiques, texte et exécutables, d'archives et d'autres types de fichiers.
Gratuit  Acronis True Image Home 2011 Build 6942/ Home 2012 Build 5545 est une application puissante pour créer des images précises des partitions de disque sélectionnées ou des disques eux-mêmes. Acronis True Image crée une copie de sauvegarde complète de toutes les données, applications et systèmes d'exploitation, avec la possibilité de restaurer ou de copier rapidement sur un autre ordinateur avec la possibilité de créer une copie complète de cet ordinateur.
Acronis True Image Home 2011 Build 6942/ Home 2012 Build 5545 est une application puissante pour créer des images précises des partitions de disque sélectionnées ou des disques eux-mêmes. Acronis True Image crée une copie de sauvegarde complète de toutes les données, applications et systèmes d'exploitation, avec la possibilité de restaurer ou de copier rapidement sur un autre ordinateur avec la possibilité de créer une copie complète de cet ordinateur.
Gratuit  Acronis Disk Director 11 Home est un progiciel complet avec de nombreux outils nécessaires pour travailler avec des partitions et des disques durs. Le progiciel a la capacité de gérer vos disques et partitions, ainsi que de créer vos propres disques de démarrage pour la sauvegarde du système et la récupération rapide.
Acronis Disk Director 11 Home est un progiciel complet avec de nombreux outils nécessaires pour travailler avec des partitions et des disques durs. Le progiciel a la capacité de gérer vos disques et partitions, ainsi que de créer vos propres disques de démarrage pour la sauvegarde du système et la récupération rapide.
Gratuit  DiVFix 1.10 avec ce programme, vous pouvez facilement visualiser des vidéos .avi partiellement téléchargées. DiVFix prend en charge la visualisation de divers formats vidéo, notamment .wmv ou .mpeg. Étant donné que les fichiers .avi ne peuvent être visualisés que s'ils sont entièrement téléchargés, en raison du fait qu'il y a une table d'index à la fin des fichiers, et sans elle, il ne peut pas être ouvert, ils ne peuvent pas non plus être lus sur d'autres lecteurs.
DiVFix 1.10 avec ce programme, vous pouvez facilement visualiser des vidéos .avi partiellement téléchargées. DiVFix prend en charge la visualisation de divers formats vidéo, notamment .wmv ou .mpeg. Étant donné que les fichiers .avi ne peuvent être visualisés que s'ils sont entièrement téléchargés, en raison du fait qu'il y a une table d'index à la fin des fichiers, et sans elle, il ne peut pas être ouvert, ils ne peuvent pas non plus être lus sur d'autres lecteurs.
Gratuit  Avi Previewer 2.2.7 est un programme qui a la capacité de visualiser les fichiers avi incomplètement téléchargés ou simplement endommagés qui ne peuvent pas être lus sur des lecteurs conventionnels ou qui présentent des défauts. Le programme Avi Previewer vous permettra de réparer les fichiers s'ils sont endommagés, de les restaurer après suppression ou extraction incorrecte de l'archive, etc.
Avi Previewer 2.2.7 est un programme qui a la capacité de visualiser les fichiers avi incomplètement téléchargés ou simplement endommagés qui ne peuvent pas être lus sur des lecteurs conventionnels ou qui présentent des défauts. Le programme Avi Previewer vous permettra de réparer les fichiers s'ils sont endommagés, de les restaurer après suppression ou extraction incorrecte de l'archive, etc.
Gratuit  Advanced ZIP Password Recovery 4.00 est un programme avec la capacité de récupérer les mots de passe perdus pour les archives ZIP.
Advanced ZIP Password Recovery 4.00 est un programme avec la capacité de récupérer les mots de passe perdus pour les archives ZIP.
 Capture d'écran 1.
Capture d'écran 1. Immédiatement après le démarrage du programme Boîte à outils de récupération DBF une fenêtre de sélection d'un fichier dbf à restaurer s'ouvre. Il existe trois façons de sélectionner le fichier souhaité :
En plus du fichier dbf, la table peut également inclure dans sa structure un fichier contenant les informations des champs de type MEMO. Ces fichiers ont généralement un nom qui correspond au nom de la table dbf et à l'extension fpt pour les tables FoxPro ou *.dbt pour les tables dBase.
Note Remarque : Si le fichier dbf endommagé contient des champs de type MEMO, mais que le fichier fpt ou dbt n'a pas été spécifié, DBF Recovery Toolbox restaurera uniquement la structure du champ dans le fichier de la table principale et les liens de celui-ci vers le fichier de ce champ . Cependant, les informations contenues dans le fichier externe ne seront pas traitées. Ainsi, si le fichier MEMO n'a pas été endommagé, un travail ultérieur normal avec la table restaurée sera possible. Cependant, si, en plus de la table dbf elle-même, le fichier fpt ou dbt a été endommagé et n'a pas été restauré, des pannes sont possibles pendant le fonctionnement.
Après avoir sélectionné le fichier de table à restaurer, pour continuer à travailler, vous devez cliquer sur le bouton Analyser, situé en bas de la fenêtre du programme.
Si une erreur a été commise lors de la saisie du nom ou du chemin d'accès au fichier de la table, le programme émettra un avertissement Veuillez sélectionner le fichier à restaurer ! (Veuillez sélectionner un fichier à restaurer !) et le processus d'analyse de la structure de la table ne démarrera pas.
 Capture d'écran 2.
Capture d'écran 2. Lorsque vous passez à l'étape de visualisation de la structure et du contenu des données de la table source, le programme affiche une fenêtre avec un avertissement sur le début du processus de récupération des données. Voulez-vous démarrer la récupération ? (Voulez-vous commencer la récupération ?). Si vous devez modifier le nom ou le chemin d'accès au fichier dbf, ou ajouter un fichier MEMO à la sélection, vous devez cliquer sur le bouton Non et revenir à la fenêtre de sélection de fichier à l'aide du bouton Précédent.
Si tous les fichiers sont spécifiés correctement, cliquez sur le bouton Oui dans la boîte de dialogue. Après avoir cliqué sur ce bouton, le programme commencera à analyser le fichier de table dbf et les fichiers de champ MEMO supplémentaires.
Si lors de l'analyse de la structure de la table source, des champs MEMO ont été trouvés, mais que le fichier fpt ou dbt - stockage de ces champs - n'a pas été spécifié, le programme recherche les fichiers de ces types avec un nom qui correspond au nom du fichier source dans le répertoire à partir duquel il est lu. Lors de la détection, le programme affichera une fenêtre avec une suggestion d'utiliser le fichier lors de l'analyse de la table.
Dans le processus d'analyse et de récupération des informations, le programme Boîte à outils de récupération DBF:
- Lit l'en-tête du fichier, identifie les noms et les types des champs dans la table et détermine les décalages auxquels les enregistrements commencent physiquement dans le fichier source.
- Identifie le début de chaque enregistrement dans la table source et extrait tous les champs de ces enregistrements du fichier source. Si la table contient des champs de type MEMO, identifie les liens contenus dans les enregistrements de la table vers les adresses des données stockées dans le fichier de ces champs. Le fichier MEMO lui-même n'est pas traité.
- Si un fichier associé aux champs MEMO (fpt ou dbt) a été spécifié, le programme analyse sa structure et identifie les enregistrements du fichier correspondant aux liens de la table principale.
Lors de la restauration des informations, une barre de progression s'affichera en bas de l'écran, avec laquelle vous pourrez évaluer à quel stade se trouve la récupération des données.
Une fois l'analyse du fichier dbf endommagé terminée, les informations restaurées seront affichées sous la forme d'un tableau dans l'espace de travail principal de la fenêtre. Les colonnes du tableau affiché à l'écran correspondront aux champs du fichier source, et les lignes du tableau correspondront à ses enregistrements.
Si le fichier est tellement endommagé que le programme ne pourra pas en récupérer les informations, le bouton Envoyer un fichier aux développeurs apparaîtra en bas de la fenêtre, avec lequel vous pourrez envoyer le fichier endommagé aux développeurs du programme par e -mail pour une analyse et une récupération plus détaillées. De plus, à tout moment, vous pouvez envoyer le fichier aux développeurs pour analyse à l'aide de l'élément Envoyer le fichier source, situé dans le menu Actions.
Après avoir visualisé les informations récupérées, vous devez cliquer sur le bouton Suivant, situé en bas de la fenêtre du programme, pour passer à l'étape d'enregistrement du fichier récupéré.
 Capture d'écran 3.
Capture d'écran 3. Lorsque vous travaillez avec le fichier dbf d'origine et tous les fichiers joints, aucune modification ne leur est apportée. Tout le travail s'effectue avec une copie des informations qui se trouvent dans la RAM de l'ordinateur. Par conséquent, pour un travail ultérieur avec les données récupérées, elles doivent être enregistrées sur le disque.
Dans le même temps, l'enregistrement des informations restaurées à partir du fichier d'origine n'est possible que dans la version enregistrée du programme. Dans la version d'essai, vous ne pouvez afficher les informations qu'à l'étape 2.
Pour enregistrer des informations, vous pouvez utiliser trois méthodes pour sélectionner un fichier :
- Entrez le chemin et le nom du fichier dans la liste déroulante Nom du fichier réparé (.dbf) : située dans l'espace de travail principal de la fenêtre. Lorsque vous ouvrez une fenêtre de sélection d'un fichier à enregistrer, le programme remplit automatiquement le champ de saisie. Par défaut, il est proposé d'enregistrer le fichier dbf restauré dans le même dossier à partir duquel le fichier d'origine a été obtenu, mais avec un nom composé du nom du fichier d'origine et du suffixe _repaired. C'est-à-dire que si le fichier example.dbf a été utilisé, le programme proposera de l'enregistrer sous le nom example_repaired.dbf.
- Sélection d'un dossier à enregistrer et d'un nom de fichier à l'aide de la boîte de dialogue d'enregistrement de fichier standard. Le bouton d'appel de la boîte de dialogue de sélection de fichier est situé à droite de la combo. Lors de l'ouverture d'une boîte de dialogue, le répertoire à partir duquel le fichier source a été lu et le nom du fichier construit selon le principe décrit ci-dessus sont également utilisés.
- Sélection d'un fichier dans la liste déroulante du champ de saisie. Lorsque vous travaillez avec des fichiers de table, le programme Boîte à outils de récupération DBF stocke des informations sur les fichiers précédemment enregistrés dans ses paramètres et, si nécessaire, ces noms et chemins de fichiers peuvent être réutilisés.
Après avoir spécifié le chemin et le nom du fichier enregistré, pour enregistrer les informations récupérées, vous devez cliquer sur le bouton Enregistrer, situé en bas de la fenêtre du programme.
Si le répertoire spécifié dans le champ Nom du fichier réparé (.dbf) : n'existe pas, l'avertissement Répertoire n'existe pas s'affichera, le fichier ne sera pas enregistré et le programme restera à l'étape de sélection d'un fichier à enregistrer .
Si le fichier spécifié dans le champ existe déjà, le programme vous demandera de l'écraser Voulez-vous réécrire le fichier existant ? (Voulez-vous écraser un fichier existant ?). Si vous appuyez sur le bouton Non, le programme restera également à l'étape de sélection du fichier. Si vous appuyez sur le bouton Oui ou si le fichier n'existe pas déjà, DBF Recovery Toolbox passera à l'étape d'affichage des résultats de la récupération.
 Capture d'écran 4.
Capture d'écran 4. Le programme peut enregistrer les informations lues à partir du fichier source dans n'importe quel format : dBase III-IV, FoxPro 3.x (ou ultérieur). Cependant, gardez à l'esprit que lorsque vous enregistrez un document dans un format de version antérieure, certaines des données incompatibles avec la version du fichier enregistré peuvent être perdues ou corrompues.
Le format du document enregistré est sélectionné à l'aide du champ de liste déroulante Sélectionner la version du fichier DBF de sortie : (sélectionnez la version du fichier DBF résultant).
Lorsque vous ouvrez la fenêtre de sélection du format du document enregistré, le programme propose automatiquement d'enregistrer le document récupéré dans une version de format qui correspond au document d'origine. Si le fichier source a été tellement endommagé qu'il n'a pas été possible de déterminer sa version, le programme proposera par défaut d'enregistrer le fichier dans la dernière version disponible du format.
Après avoir terminé les paramètres du format du document enregistré, pour procéder au processus de restauration et d'enregistrement des données, vous devez cliquer sur le bouton Enregistrer le fichier, situé en bas de la fenêtre du programme.
Si nécessaire, vous pouvez revenir à la page de sélection d'un fichier à enregistrer en cliquant sur le bouton Retour.
Capture d'écran 5. À ce stade du travail, le programme dans la zone de travail principale de la fenêtre affiche des informations sur tous les fichiers qui ont été restaurés au cours de cette session de son travail. Les informations consistent en :
- nom et chemin d'accès au fichier en cours de restauration ;
- nom et chemin d'accès au fichier dans lequel les informations récupérées ont été enregistrées ;
- le nombre d'enregistrements qui ont été restaurés ;
- l'heure à laquelle le fichier de table dbf a été restauré.
Après avoir consulté le journal, vous pouvez revenir en arrière en utilisant le bouton Retour, qui se trouve en bas de la fenêtre du programme pour modifier les paramètres de travail avec le programme (enregistrement du fichier récupéré sous un nom différent, sélection d'un autre fichier pour la récupération, etc. .).
Si vous avez terminé avec le programme, vous pouvez cliquer sur le bouton Terminer pour quitter ou simplement fermer la fenêtre du programme.
Fin du travail
Après avoir examiné le journal, vous pouvez quitter en cliquant sur le bouton Quitter ou en sélectionnant la commande Quitter dans le menu Fichier. Il est également possible, à l'aide du bouton Bak (Retour), de revenir à la première page du programme et de sélectionner un autre fichier à récupérer. Veuillez noter que dans ce cas, lorsque vous enregistrez le fichier, le nom et le dossier du fichier restauré ne changent pas automatiquement et vous devrez les modifier manuellement ou les sélectionner à l'aide de la boîte de dialogue.