Possibilities of using machine translation in the work of a translator in the professional field. Topic: Machine translation. PROMT machine translation system
Lecture No. 8 Topic: Purpose of machine translation systems.
Purpose of machine translation
Machine translation (MT), or automatic translation (AT), is an intensively developing field. scientific research, experimental developments and already functioning systems (NSS), in which a computer is involved in the process of translation from one natural language (NL) to another. SMPs provide quick and systematic access to information in a foreign language, ensure efficiency and uniformity in the translation of large flows of texts, mainly scientific and technical ones. EMS operating on an industrial scale rely on large terminological data banks and, as a rule, require the involvement of a person as a pre-, inter- or post-editor. Modern SMPs, especially those that are based on knowledge bases in a specific subject area when translated, are classified as systems artificial intelligence(AI).
Main areas of use of MC
1. In industry information services in the presence of a large array or constant flow of foreign language sources. If SMPs are used to provide signaling information, post-editing is not required.
2. In large international organizations, dealing with a multilingual polythematic array of documents. These are the conditions of work at the Commission of the European Communities in Brussels, where all documentation must appear simultaneously in nine working languages. Since the translation requirements here are high, MP requires post-editing.
3. In translation services technical documentation accompanying exported products. Translators cannot cope with extensive documentation within the required time frame (for example, specifications for aircraft and other complex objects can take up to 10,000 or more pages). The structure and language of technical documentation are quite standard, which makes translation easier and even makes it preferable to manual translation, as it guarantees a uniform style
the entire array. Since the translation of specifications must be complete and accurate, MP products require post-editing.
4. For simultaneous or almost simultaneous translation of some constant stream of similar messages. This is the flow of weather reports in Canada that must appear simultaneously in English and French.
In addition to the practical need of the business world for MSP, there are also purely scientific incentives for the development of MSP: stably operating experimental MSP systems are experimental field to test various aspects of the general theory of understanding, speech communication, information transformation, as well as to create new, more effective models of the MP itself.
In terms of scale and degree of development, SMPs can be divided into three main classes: industrial, developing and experimental.
Linguistic support for machine translation systems
The MT process is a sequence of transformations applied to the input text and transforming it into text in the output language, which should maximally recreate the meaning and, as a rule, the structure of the source text, but using the output language. The linguistic support of SMP includes the entire complex of linguistic, metalinguistic and so-called “extralinguistic” knowledge that is used in such transformation.
In classical SMTs, which carry out indirect translation of individual sentences (phrase-by-phrase translation), each sentence goes through a sequence of transformations consisting of three parts (stages): analysis -> transfer (interlingual operations) -> synthesis. In turn, each of these stages represents a sufficient complex system intermediate transformations.
The goal of the analysis stage is to construct a structural description (intermediate representation, internal representation) of the input sentence, | The task of the transfer stage (translation itself) is to transform the structure of the input sentence into the internal structure of the output sentence. This stage also includes replacing lexemes of the input language with their translation equivalents (lexical interlingual transformations). The goal of the synthesis stage is to construct the correct sentence of the target language based on the structure obtained as a result of the analysis.
Linguistic support for standard modern SMP includes:
1) dictionaries;
2) grammar;
3) formalized intermediate representations of units of analysis on different stages transformations.
In addition to standard ones, some SMPs may also have some non-standard components. Thus, expert knowledge about software can be specified using special conceptual networks, and not in the form of dictionaries and grammars.
Mechanisms (algorithms, procedures) for operating with existing dictionaries, grammars and structural representations are classified as mathematical and algorithmic support for SMP.
One of necessary requirements to modern SMP - high modularity. From a linguistically substantive point of view, this means that analysis and the processes that follow it are built taking into account the theory of linguistic levels. In the practice of creating SMP, the following levels of analysis are distinguished:
Pre-syntactic analysis (this includes morphological analysis - MorphAn, analysis of phrases, unidentified text elements, etc.);
Syntactic analysis SinAn (builds a syntactic representation of a sentence, or SinP); within its boundaries a number of sublevels can be distinguished that provide analysis of different types of syntactic units;
Semantic analysis SemAn, or logical-semantic analysis (builds an argument-predicate structure of statements or another type of semantic
proposal submissions and text);
Conceptual analysis (analysis in terms of conceptual structures reflecting software semantics). This level of analysis is used in SMPs that target very limited software. In fact, the conceptual structure is a projection of software schemes onto linguistic structures, often not even semantic, but syntactic. Only for very narrow software and limited classes of texts does the conceptual structure coincide with the semantic one; in general, there should not be a complete match, since the text is more detailed than any
conceptual diagrams.
Synthesis theoretically goes through the same levels as analysis, but in the opposite direction. In working systems, only the path from the SinP to the chain of words of the output sentence is usually implemented.
The linguistic differentiation of different levels can also be manifested in the differentiation of the formal means used in the corresponding descriptions (the set of these means is specified for each level separately). In practice, the linguistic means MorfAn are often specified separately and the means SinAn and SemAn are combined. But the distinction between levels can only remain meaningful if a single formalism is used in their descriptions, suitable for representing information from all distinguished levels.
From a technical point of view, the modularity of linguistic support means the separation of the structural representation of phrases and texts (as current, temporary knowledge about the text) from “permanent” knowledge about the language, as well as language knowledge from software knowledge; separation of dictionaries from grammars, grammars from algorithms for their processing, algorithms from programs. The specific relationships between the various modules of the system (dictionaries-grammars, grammars-algorithms, algorithms-programs, declarative-procedural knowledge, etc.), including the distribution of linguistic data across levels, is the main thing that determines the specifics of SMP.
Dictionaries. Analysis dictionaries are usually monolingual. They must contain all the information necessary to include a given lexical unit (LU) in the structural representation. Dictionaries of basics (with morphological-syntactic information: part of speech, type of inflection, subclass characterizing the syntactic behavior of LEs, etc.) are often separated from dictionaries of word meanings containing semantic and conceptual information: semantic class of LEs, semantic hopes (valences), conditions their implementation in a phrase, etc.
In many systems, dictionaries of common and terminological vocabulary are separated. This division makes it possible, when moving to texts of another subject area, to limit oneself only to changing terminological dictionaries. Dictionaries of complex LE (turns of phrases, constructions) usually form a separate array, the dictionary information in them indicates the method of “collecting” such a unit during analysis. Part of the dictionary information can be specified in a procedural form, for example, polysemous words can be associated with algorithms for resolving the corresponding type of ambiguity. New types of organization of dictionary information for MT purposes are offered by the so-called “lexical knowledge bases”. The presence of heterogeneous information about a word (called the lexical universe of a word) brings such a dictionary closer to an encyclopedia than to traditional linguistic dictionaries.
Grammars and algorithms. Grammar and vocabulary define the linguistic model, forming the bulk of linguistic data. Algorithms for their processing, 1. i.e. correlation with text units, are referred to as the mathematical and algorithmic support of the system.
The separation of grammars and algorithms is important in a practical sense because it allows you to change the rules of the grammar without changing the algorithms (and, accordingly, the programs) that work with the grammars. But such a division is not always possible. So, for a system with a procedural task of grammar, and even more so with a procedural representation of dictionary information, such a division is irrelevant. Decision-making algorithms in the case of insufficient (incompleteness of input data) or redundant (variability of analysis) information are more empirical; their formulation requires linguistic intuition. Setting a general control algorithm that controls the order in which different grammars are called (if there are several of them in one system) also requires linguistic justification. However, the current trend is to separate grammars from algorithms so that all linguistically meaningful information is specified in the static form of grammars, and to make algorithms so abstract that they can call and process different linguistic models.
The most clear separation of grammars and algorithms is observed in systems working with context-free grammars (CFG), where the language model is a grammar with a finite number of states, and the algorithm must provide for an arbitrary sentence a tree of its output according to the rules of the grammar, and if there are several such outputs , then list them. Such an algorithm, which is a formal (in the mathematical sense) system, is called an analyzer. The description of the grammar serves for the analyzer, which has universality, the same input as the analyzed sentence. Parsers are built for classes of grammars, although taking into account specific features of the grammar can improve the efficiency of the parser.
Syntactic level grammars are the most developed part both from the point of view of linguistics and from the point of view of their provision with formalisms.
The main types of grammars and algorithms that implement them:
Chain grammar fixes the order of elements, that is, the linear structures of a sentence, specifying them in terms of grammatical classes of words (article + noun + preposition) or in terms of functional elements (subject + predicate);
The grammar of components (or the grammar of direct components - NSG) records linguistic information about the grouping of grammatical elements, for example, a noun phrase (consists of a noun, an article,
adjective and other modifiers), prepositional phrase (consists of a preposition and a noun phrase), etc. up to the sentence level. The grammar is constructed as a set of substitution rules, or the calculus of productions of the form A-»B...C. NSG
They are grammars of the generative type and can be used both in analysis and in synthesis: sentences of a language are generated by repeated application of such rules;
Dependency grammar (DG) specifies a hierarchy of relations between sentence elements (the main word determines the form of the dependent ones). The analyzer in GZ is based on the identification of masters and their dependents (servants). The main thing in a sentence is the verb in personal form, since it determines the number and nature of dependent nouns. The strategy of analysis in civil law is top-down: first the masters are identified, then the servants, or bottom-up: the masters are determined by the substitution process;
The Bar-Hillel categorical grammar is a version of the constituent grammar, in which there are only two categories - sentences S and names n. The rest are defined in terms of the ability to combine with these main ones in the structure of the NS. Thus, a transitive verb is defined as n\S because it combines with and to the left of a name to form the sentence S.
There are many ways to account for contextual conditions: grammars of metamorphosis and their variants. All of them are extensions of the KS rules. In general terms, this means that the rules of production are rewritten as follows: A [a] -> B [b], ..., C [c], where small letters indicate conditions, tests, instructions, etc., expanding the original rigid rules and giving the grammar flexibility and efficiency.
In the grammar of generalized components-TCS, meta-rules are introduced, which are a generalization of the regularities of the rules of KS1.
The grammars of extended transition networks-RSP provide tests and conditions for arcs, as well as instructions that must be executed if the analysis follows a given arc. In various modifications of the RSP, weights can be assigned to arcs, then the analyzer can select the path with the highest weight. Conditions can be divided into two parts: context-free and context-sensitive.
A type of RSPG is cascade RSPG. The cascade is a RSP equipped with the action 1shshsh1. This action causes the process in this cascade to stop, storing information about the current configuration on the stack and moving to a deeper cascade with a subsequent return to its original state. RSP has a number of possibilities of transformational grammars. It can also be used as a generating system.
The graph analysis method allows you to store partial results and present analysis options.
A new and immediately popular method of grammatical description is lexical-functional grammar (LFG). It eliminates the need for transformation rules. Although the LFG is based on the CSG, the test conditions in it are separated from the substitution rules and are “solved” as autonomous equations.
Unification grammars (UG) represent the next stage of generalization of the analysis model after graph-schemes: they are capable of embodying grammars various types. The UG contains four components: a unification package, an interpreter for rules and lexical descriptions, programs for processing directed graphs, and an analyzer using a graph diagram. UGs combine grammatical rules with dictionary descriptions, syntactic valences with semantic ones.
The central problem of any NL analysis system is the problem of choosing options. To solve it, syntactic-level grammars are supplemented with auxiliary grammars and methods for analyzing complex situations. NN grammars use filter and heuristic methods. The filter method is: that first they receive all options for analyzing a proposal, and then reject those that do not satisfy a certain system of filter conditions. From the very beginning, the heuristic method constructs only a part of the options that are more plausible from the point of view of the given criteria. The use of weights to select options is an example of the use of heuristic methods in analysis.
The semantic level is much less supported by theory and practical developments. The traditional task of semantics is to remove the ambiguity of syntactic analysis - structural and lexical. For this purpose, the apparatus of selective restrictions is used, which is tied to the frames of sentences, i.e., fits into the syntactic model. The most common type of SemAn is based on so-called case grammars. The basis of grammar is the concept of deep, or semantic, case. The case frame of a verb is an extension of the concept of valence: it is a set of semantic relations that can (mandatory or optional) accompany the verb and its variations in the text. Within the same language, the same deep case is realized by different surface prepositional case forms. Deep cases, in principle, allow one to go beyond the boundaries of the sentence, and going into the text means moving to the semantic level of analysis.
Since semantic information, in contrast to syntactic information, which relies primarily on grammars, is concentrated mainly in dictionaries, in the 80s grammars were intensively developed to “lexicalize” DRGs. The development of grammars based on the study of the properties of discourse is underway.
Speakers: Irina Rybnikova and Anastasia Ponomareva.
We will tell you about the history of machine translation and how we use it in Yandex.
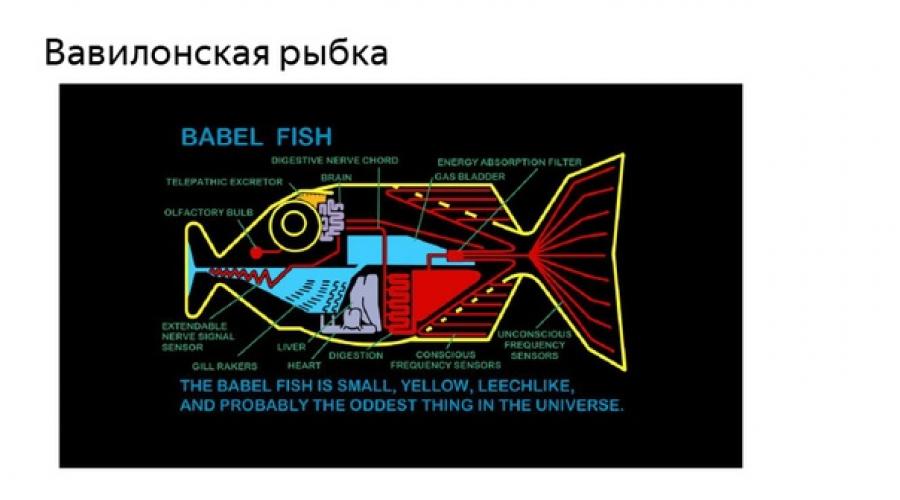
Back in the 17th century, scientists speculated about the existence of some kind of language that connects other languages, and this is probably too long ago. Let's take a closer look. We all want to understand the people around us - no matter where we go - we want to see what is written on the signs, we want to read announcements, information about concerts. The idea of the Babel fish haunts the minds of scientists and is found in literature, cinema, and everywhere. We want to reduce the time it takes us to access information. We want to read articles about Chinese technologies, understand any sites we see, and we want to receive it here and now.

In this context, it is impossible not to talk about machine translation. This is what helps solve this problem.

The starting point is considered to be 1954, when 60 sentences on general topics were translated in the USA on an IBM 701 machine organic chemistry from Russian to English, and at the heart of it all were 250 glossary terms and six grammatical rules. It was called the Georgetown Experiment, and it was such a shock to reality that the newspapers were full of headlines that in another three to five years, the problem would be completely solved, everyone would be happy. But as you know, everything went a little differently.
Rule-based machine translation emerged in the 1970s. It was also based on bilingual dictionaries, but also on the very same sets of rules that helped describe any language. Anyone, but with restrictions.

Serious linguistic experts were required to write down the rules. This is quite a complex job, it still could not take into account the context, completely cover any language, but they were experts, and high computing power was not required then.

If we talk about quality, classic example- a quote from the Bible, which was then translated like this. Not enough yet. Therefore, people continued to work on quality. In the 90s, a statistical translation model, SMT, arose, which spoke about the probabilistic distribution of words and sentences, and this system was fundamentally different in that it knew nothing at all about the rules and about linguistics. She received as input a huge number of identical texts, paired in one language and another, and then she made decisions herself. It was easy to maintain, didn't require a bunch of experts, didn't require waiting. You could download and get the result.

The requirements for incoming data were quite average, from 1 to 10 million segments. Segments - sentences, small phrases. But there were difficulties and the context was not taken into account; everything was not very easy. And in Russia, for example, such cases have appeared.

I also like the example of translations of GTA games, the result was great. Everything did not stand still. A fairly important milestone was 2016, when neural machine translation was launched. It was quite an epoch-making event that greatly changed life. My colleague, after looking at the translations and how we use them, said: “Cool, he speaks in my words.” And it was really great.
What are the features? High requirements at the entrance, training material. It is difficult to maintain this within the company, but a significant increase in quality is what it was started for. Only a high-quality translation will solve the assigned problems and make life easier for all participants in the process, the same translators who do not want to correct a bad translation, they want to do new creative tasks, and leave routine template phrases to the machine.
There are two approaches within machine translation. Expert review/ linguistic analysis of texts, that is, verification by real linguists and experts for compliance with the meaning and literacy of the language. In some cases, they sat down experts, allowed them to proofread the translated text and assessed how effective it was from this point of view.

What are the features of this method? A translation sample is not required; we look at the finished translated text now and evaluate it objectively according to any aspect. But it's expensive and time-consuming.

There is a second approach - automatic reference metrics. There are many of them, each has pros and cons. I won’t go into depth; you can read about these keywords in more detail later.
What feature? In fact, this is a comparison of translated machine texts with some kind of standard translation. These are quantitative metrics that show the discrepancy between the exemplary translation and the actual result. It's fast, cheap and can be done quite conveniently. But there are some peculiarities.

In fact, hybrid methods are now most often used. This is when something is initially evaluated automatically, then the error matrix is analyzed, and then an expert linguistic analysis is carried out on a smaller corpus of texts.

Recently, it is still a common practice when we invite not linguists, but simply users. The interface is being made - show which translation you like best. Or when you go to online translators, you enter text, and you can often vote on what you like better, whether this approach is suitable or not. In fact, we are all currently training these engines, and everything that we give them to translate, they use for training and work on their quality.
I would like to tell you how we use machine translation in our work. I give the floor to Anastasia.
We at Yandex in the localization department realized quite quickly that machine translation technology had great potential, and decided to try to use it in our daily tasks. Where did we start? We decided to conduct a small experiment. We decided to translate the same texts through a regular neural network translator, and also to assemble a trained machine translator. To do this, we have prepared corpora of texts in the Russian-English pair over the years that we at Yandex have been localizing texts into these languages. Next, we came with this corpus of texts to our colleagues from Yandex.Translator and asked us to train the engine.

When the engine was trained, we translated the next batch of texts, and, as Irina said, with the help of experts we evaluated the results. We asked translators to look at literacy, style, spelling, and conveying meaning. But the most turning point was when one of the translators said that “I recognize my style, I recognize my translations.”
To reinforce these feelings, we decided to calculate statistical indicators. First, we calculated the BLEU coefficient for transfers made through a regular neural network engine and got the following figure (0.34). It would seem that it needs to be compared with something. We again went to our colleagues from Yandex.Translator and asked them to explain what BLEU coefficient is considered the threshold for translations made by a real person. This is from 0.6.
Then we decided to check the results on trained translations. We got 0.5. The results are truly encouraging.

Let me give you an example. This is a real Russian phrase from the Direct documentation. Then it was translated through a regular neural network engine, and then through a trained neural network engine using our texts. Already in the very first line we notice that the traditional type of advertising for Direct was not recognized. And already in the trained neural network engine our translation appears, and even the abbreviation is almost correct.
We were very encouraged by the results obtained, and decided that it was probably worth using the machine engine in other pairs, on other texts, not just on that basic set of technical documentation. Then a series of experiments were carried out for several months. Faced with big amount features and problems, these are the most common problems that we had to solve.

I’ll tell you more about each one.

If you, like us, are going to make a custom engine, you will need enough a large number of high-quality parallel data. A large engine can be trained on a quantity of 10 thousand sentences; in our case, we prepared 135 thousand parallel sentences.

Your engine will not show equally good results on all types of text. In technical documentation where there are long sentences, structure, user documentation and even in the interface where there are short but unambiguous buttons, you will most likely do well. But perhaps, like us, you will encounter problems in marketing.
We conducted an experiment translating music playlists and got this example.

This is what the machine translator thinks about star factory workers. That these are labor shock workers.

When translating through a machine engine, the context is not taken into account. This is not such a funny example, but a very real one, from the technical documentation of Direct. It would seem that those are clear, when you read the technical documentation, those are technical. But no, the machine engine didn’t hit.

You will also have to take into account that the quality and meaning of the translation will greatly depend on the original language. We translate the phrase into French from Russian and get the same result. We get a similar phrase with the same meaning, but from English, and we get a different result.

If, as in our text, you have a large number of tags, markup, and some technical features, most likely you will have to track them, edit them, and write some scripts.
Here are examples of real phrases from the browser. In parentheses is technical information that should not be translated, in particular plural forms. In English they are in English, and in German they should also remain in English, but they are translated. You will have to keep track of these points.

The machine engine knows nothing about your naming features. For example, we have an agreement that we call Yandex.Disk everywhere in the Latin alphabet in all languages. But in French it turns into a disk in French.

Abbreviations are sometimes recognized correctly, sometimes not. In this example, BY, denoting that it belongs to the Belarusian technical requirements for advertising, turns into a preposition in English.

One of my favorite examples is new and borrowed words. Here’s a cool example, the word disclaimer, “originally Russian.” Terminology will have to be verified for each part of the text.
And one more, not so significant problem - outdated spelling.

Previously, the Internet was a new thing, in all texts it was written with a capital letter, and when we trained our engine, the Internet was written with a capital letter everywhere. Now is a new era, we are already writing the Internet with a small letter. If you want your engine to continue writing the Internet with a lowercase letter, you will have to retrain it.

We did not despair, we solved these problems. Firstly, we changed the text corpora and tried to translate on other topics. We passed on our comments to our colleagues from Yandex.Translator, re-trained the neural network and looked at the results, evaluated them, and asked for improvements. For example, tag recognition, HTML markup processing.
I will show real options use. We are good at machine translation for technical documentation. This is a real case.

Here is the phrase in English and Russian. The translator who handled this documentation was very encouraged by the appropriate choice of terminology. Another example.

The translator appreciated the choice of is instead of a dash, that the structure of the phrase has changed to English, the adequate choice of the term, which is correct, and the word you, which is not in the original, but it makes this translation exactly English, natural.

Another case is on-the-fly interface translations. One of the services decided not to bother with localization and translate texts right during loading. But after changing the engine, about once a month the word “delivery” changed in a circle. We suggested that the team connect not an ordinary neural network engine, but ours, trained on technical documentation, so that the same term, agreed upon with the team, which is already in the documentation, is always used.

How does all this affect the monetary moment? It has historically been the case that in a Russian-Ukrainian pair, minimal editing of the Ukrainian translation is required. Therefore, a couple of months ago we decided to switch to a post-editing system. This is how our savings grow. September is not over yet, but we estimate that we have reduced our post-editing costs by about a third in Ukrainian, and we are going to continue editing almost everything except marketing texts. A word from Irina to sum up.
Irina:
- It becomes obvious to everyone that we need to use this, this is already our reality, and we cannot exclude it from our processes and interests. But there are a few things to think about.

Decide on the types of documents and context you are working with. Is this technology right for you specifically?
Second point. We talked about Yandex.Translator because we are in good relations, we have direct access to developers and so on, but in fact you need to decide which engine will be the most optimal for you specifically, for your language, your topic. The next report will be devoted to this topic. Be prepared that there are still difficulties, engine developers are all working together to solve the difficulties, but for now they are still encountered.

I would like to understand what awaits us in the future. But in fact, this is no longer further, but ours present time, what is happening here and now. We all rather need customization to fit our terminology, our texts, and this is what is now becoming public. Now everyone is working to ensure that you don’t go inside the company and negotiate with the developers of a specific engine on how to optimize it for you. You can get this in public open engines via API.
Customization occurs not only in texts, but also in terminology, in customizing terminology to suit your own needs. This is quite an important point. The second topic is interactive translation. When a translator translates a text, the technology allows him to predict the next words, taking into account the source language, the source text. This can make your work much easier.
About what is really expensive now. Everyone is thinking about how to train some engines much more effectively using smaller amounts of text. This is something that happens everywhere and is triggered everywhere. I think the topic is very interesting, and it will become even more interesting in the future.
Machine Translation: A Brief History
Another outstanding mathematician of the 19th century, Charles Babbage, tried to convince the British government of the need to finance his research on the development of " computer"Among other benefits, he promised that someday this machine would be able to automatically translate spoken speech. However, this idea remained unrealized [Shalyapina 1996: 105].
The birth date of machine translation as a research field is usually considered to be March 1947. It was then that cryptography specialist Warren Weaver, in his letter to Norbert Wiener, first posed the problem of machine translation, comparing it with the problem of decryption.
The same Weaver, after a series of discussions, drew up a memorandum in 1949 in which he theoretically substantiated the fundamental possibility of creating machine translation systems. W. Weaver wrote: “I have a text in front of me which is written in Russian but I am going to pretend that it is really written in English and that it has been coded in some strange symbols. All I need to do is strip off the code in order to retrieve the information contained in the text" ("I have a text in front of me that is written in Russian, but I am going to pretend that it is actually written in English and encoded using rather strange characters. All I need is to crack the code to extract the information contained in the text" [Slocum 1989: 56-58].
Weaver's ideas formed the basis of an approach to MP based on the concept interlingua: The information transmission stage is divided into two stages. At the first stage, the source sentence is translated into an intermediary language (created on the basis of simplified English), and then the result of this translation is presented in the target language.
In those days, the few computers that were available were used mainly for solving military problems, so it is not surprising that in the USA the main attention was paid to Russian-English, and in the USSR - to English-Russian translation. By the early 50s, a number of research groups were struggling with the problem of automatic translation.
In 1952, the first conference on MT was held at the Massachusetts Institute of Technology, and in 1954, the first full-fledged machine translation system was presented - IBM Mark II, developed by IBM together with Georgetown University (this event went down in history as the Georgetown Experiment). The very limited system perfectly translated 49 specially selected sentences from Russian into English using a 250-word dictionary and six grammatical rules.
One of the new developments of the 70-80s was the TM (translation memory) technology, which works on the principle of accumulation: during the translation process, the original segment (sentence) and its translation are saved, resulting in the formation of a linguistic database; If an identical or similar segment to the original is found in the newly translated text, it is displayed along with the translation and an indication of the percentage match. The translator then makes a decision (edit, reject or accept the translation), the result of which is stored by the system.
Since the early 80s, when personal computers confidently and powerfully began to conquer the world, their operating time became cheaper, and they could be accessed at any moment. MP has become economically profitable. In addition, in these and subsequent years, the improvement of programs made it possible to translate many types of texts quite accurately, but some problems of MP remain unresolved to this day.
The 90s can be considered a true era of renaissance in the development of MP, which is associated not only with the high level of capabilities of personal computers, but also with the spread of the Internet, which created a real demand for MP. It has once again become an attractive investment area for both private investors and government agencies.
Since the early 1990s, Russian developers have been entering the PC systems market.
In July 1990, at the PC Forum exhibition in Moscow, Russia's first commercial machine translation system called PROMT (PROgrammer's Machine Translation) was presented. In 1991, PROJECT MT CJSC was created, and already in 1992 the company PROMT won the NASA competition for the supply of MP systems (PROMT was the only non-American company in this competition) [Kulagin 1979: 324].
As for the machine translation systems themselves, it should be noted that they went through three stages of their development:
- 1. "Electronic translators" of the first generation - direct transfer systems (DTS)- were software and hardware systems and analyzed the text “word by word” (semantic connections and nuances were practically not taken into account). The capabilities of the NGN were determined by the available sizes of dictionaries, which directly depended on the amount of computer memory. The IBM Mark II, which made the Georgetown experiment fundamentally possible, belonged to the SPP category.
- 2. Over time, SPP was replaced by T-systems(from the English Transfer - “transformation”), in which translation was carried out at the level of syntactic structures (this is how language is taught in high school). They performed a set of operations that made it possible, by analyzing the translated phrase, to determine its syntactic structure according to the rules of the grammar of the input language, and then transform it into the syntactic structure of the output sentence and synthesize a new phrase, substituting the necessary words from the dictionary of the output language. Work in this direction is no longer being carried out: practice has proven that the real correspondence system is more complex and adequate translation requires a fundamentally different algorithm of actions.
- 3. A little later, the increasingly numerous machine translation systems, depending on the principle of their operation, began to be divided into MT-programs(from Machine Translation - "machine translation") and TM-complexes(from Translation Memory - “translation memory”). As a truly successful example of an MT program, let’s name the famous Canadian METEO system, which translates weather forecasts from French into English and back (it was created almost thirty years ago and is still in use today). The METEO developers bet on the fact that truly automated machine translation is only possible under artificially limited conditions (as in vocabulary, and in grammar) of the language. And they succeeded. The world's most popular professional TM-tool is the Translation's Workbench package from TRADOS. Similar programs are mainly used professional translators who have realized the benefits of partially automating their work using a computer when translating repetitive texts that are similar in theme and structure.
The main idea of Translation Memory is not to translate the same text twice. This technology is based on comparing the document that needs to be translated with data stored in a pre-created “input” database. When the system finds a fragment that meets predetermined criteria, its translation is taken from the “output” database. The resulting text is subject to intensive human post-editing [Marchuk 1997: 21-22].
Chapter 1 Conclusions
In Chapter 1 we looked at what translation is. Its types, forms and genres were identified. We also looked at machine translation. Having touched on the topic of machine translation, we looked at its brief history, as well as what place it occupies in general classification translation. We found out how the translator program works.
The first experiments on machine translation, which confirmed the fundamental possibility of its implementation, were carried out in 1954 at Georgetown University (Washington, USA). Soon after, research and development began in industrialized countries around the world to create machine translation systems. And although more than half a century has passed since then, the problem of machine translation has still not been solved at the proper level. It turned out to be much more complex than the pioneers and enthusiasts of machine translation imagined in the late fifties and early sixties. Therefore, when assessing today's reality, we have to talk about both achievements and disappointments.
We have already said that in order to teach a machine to translate, a semantic translation model was created based on “generative semantics” and the current language model “meaning ↔ text”. The task was to provide electronic brain a sufficient number of synonyms, conversions, syntactic derivatives and semantic parameters that he could manipulate during the translation process. And translation at that time was understood only as the process of substituting words and phrases of one language instead of words and phrases of another language.
This was also the time when linguists working in the field of machine translation were trying to describe natural language using mathematical symbols. Unlike Retzker and Fedorov, who sought to establish existing patterns on the basis of practical observations, their goal was to create a deductive theory. The point was to develop a set of rules, the application of which to a certain set of linguistic units could lead to the generation of a meaningful text. Language units acted in the form of mathematical symbols, which, as a result of applying the named rules to them, also expressed mathematically, could be arranged in a certain way. After decoding, the combination of characters turned into text.
Scientists created a special language consisting of mathematical symbols that could be used by a machine as an intermediary in the transition from the source text to the target text. The intermediary language is the “metalanguage” of translation theory. In linguistics, a metalanguage is usually understood as a “second-order language,” that is, a language in which reasoning about natural language or some other phenomena is built. So, when talking about grammar, we use special words, or terms, and expressions, and when discussing the field of medicine, we use a different terminological apparatus. In other words, the metalanguage, or “intermediary language,” of translation is a complex of structural and linguistic characteristics that make it possible to describe the translation process with sufficient completeness.
According to the authors of the theory of machine translation, the intermediary language was based on the conceptual apparatus of “generative semantics” and the “meaning ↔ text” model. A set of rules has been prepared for converting surface structures of English into nuclear sentences. Scientists further expected that, with the help of an intermediary language, the machine would easily transform the deep structures of the source language into the deep structures of the target language, and then into its surface structures. But the results obtained were not completely satisfactory. The quality of machine translation turned out to be very low and subsequent attempts to improve it did not lead to success. What was the reason?
As mentioned earlier, scientists at that time, that is, in the early fifties and mid-sixties of the last century, were guided by the linguistic theory of structuralism, based on the description and interpretation of linguistic phenomena strictly within the framework of intralingual relations and not allowing going beyond the boundaries of the linguistic structure when analyzing these phenomena. They, of course, knew what every practicing translator knows well. Namely, the importance of taking into account the specific situation in which a given act of interlingual communication takes place, as well as the situation described in the translated message. From the point of view of the quality of the translated text, this information plays no less a role than the linguistic phenomena themselves.
In order to reconcile this circumstance with the requirement not to go beyond the framework of intralinguistic relations, translation activity was proposed to be divided into two components - translation itself, carried out according to given rules without recourse to extralinguistic reality reflected in the experience or perception of the translator, and interpretation, including the involvement of extralinguistic data.
But this clearly goes against what we know about real processes ordinary, that is, non-machine translation. Translation carried out by humans is characterized by an organic and inextricable unity of linguistic and extra-linguistic factors. The fact is that in any speech work not everything is expressed explicitly, or, as linguists say, explicitly. Much usually remains unexpressed, implied. Every statement is addressed to a specific person or a specific audience. The author of the statement assumes that his listeners or readers have sufficient knowledge to unambiguously interpret this or that message without specifying details.
Thus, machine translation, based only on the analysis of formal-structural patterns of the source text, does not allow revealing the interaction of linguistic and extra-linguistic factors and, thus, leaves the most important component of interlingual communication unattended. This was the main reason for its unsatisfactory quality.
Many researchers admit that to date, machine translation has not seen any breakthroughs in the implementation of other models, despite the fact that the capabilities of computers have increased many times since the beginning of machine translation work, and new programming languages have emerged, much more convenient for implementing programs for creating machine translations. The whole point, apparently, is that the interpretation of linguistic signs in relation to extra-linguistic reality is in many respects intuitive in nature and is carried out unconsciously, or, as they say, “in the subcortex”, and what is done unconsciously cannot be formalized and transferred to the machine in the form of software. Therefore, machine translation still requires a human editor and is the source of numerous translation jokes.
So, one day the machine was asked to translate into English, and then immediately back into Russian, the proverb “Out of sight, out of mind.” The final version was: "The Invisible Idiot." Why? Because the corresponding English proverb says: “Outofsight- outofmind”. The car found her without difficulty. But when translating this proverb back into Russian, it went down the wrong path. The fact is that in the Russian language there are direct correspondences to both components English phrase: Out of sight - conveyed by the word “invisible”, while the English outofmind corresponds to the Russian words “crazy, insane, idiot”. The machine took advantage of these correspondences. She simply did not realize that both named components of the English phrase should be transmitted not separately, but as a single whole. Due to her lack of a “human factor”.
In general, the level of quality of machine translation of purely informative texts, contracts, instructions, scientific reports, etc. significantly higher than journalistic texts. Here are some examples:
Payments under this contract for the equipment listed in supplement 1 to the contract shall be effected as follows.
Payments under this contract for the equipment listed in Appendix 1 to the contract are to be made as follows.
Yet plenty of traps await Mr. Bush if he tries to do it alone.
Yet plenty of trapezius muscles await Mr. Bush if he tries to go it alone.
The markets, given more and sooner than they had any reason to expect, were surprised all right.
The markets, given more and sooner than they had reason to expect, were well surprised.
Everything said earlier allows us to conclude that the pioneers of machine translation and their closest followers have achieved significant success in this area. But they still failed to solve many of the most important problems. In this regard, the statement of the head of the Japanese state program by machine translation by Professor Makoto Nagao of Kyoto University. In one of his articles published in 1982, he made the following statement: “All development of machine translation systems will sooner or later reach a dead end. Our development will also come to a standstill, but we will try to ensure that this happens as late as possible.”
That same year, Professor Nagao published a paper in which he proposed a new concept of machine translation. According to this concept, tests should be translated by analogy with other texts previously translated manually, that is, not by a machine, but by a translator. For this purpose, a large array of thematically similar texts and their translations (bilingual) must be generated, which will then be entered into a heavy-duty multiprocessor computer. In the process of translating new texts, analogues of fragments of these texts must be selected from the array of bilinguals, which can be used to form the final text. M. Nagao called his approach to machine translation “Examplebasedtranslation” (translation based on examples), and the traditional approach - “Rulebasedtranslation” (translation based on rules).
Makoto Nagao's concept echoes the recently widespread concept of "TranslationMemory", sometimes referred to as "SentenceMemory". The essence of this concept is as follows. When preparing foreign language versions of any documents (for example, operational documentation for the products of a machine-building plant) are first translated manually by highly qualified translators. Then the original documents and their translations into a foreign language are entered into a computer, divided into individual sentences or fragments of sentences, and a database is built from these elements, which is then loaded into a search engine. When translating new texts, the search engine finds in them sentences and parts of sentences similar to those it has and inserts them into the right places translated text. Thus, in automatic mode, a high-quality translation of those fragments of new text that are available in the database is obtained.
Unidentified text fragments are translated into a foreign language manually. In this case, you can use the procedure of approximate search for these fragments in the database, and use the search results as a hint. The results of manual translation of new text fragments are again entered into the database. As more and more documents are translated, the “translation memory” is gradually enriched and its effectiveness increases.
The indisputable advantage of the “translation memory” technology is high quality translations of the class of texts for which it was created. But the base of translation correspondences built for homogeneous texts of one enterprise is suitable only for homogeneous texts of enterprises with similar profiles, since sentences and large fragments of sentences extracted from the texts of some documents, as a rule, are not found or are very rarely found in the texts of other documents.
A new concept of machine translation, called the “phraseological theory of machine translation,” is aimed at overcoming this limitation of “translation memory” and, most importantly, getting out of the impasse where semantic theory seems to have reached. Main feature This concept is the idea that when translating, the main and most stable units of meaning should be considered not the semantic components that are an integral part of the language, but the concepts associated with the language through linguistic meanings, but at the same time acting as independent form a person's understanding of the environment material world. In this way, the first step is taken to teach the machine to operate not only linguistic, but also extra-linguistic aspects of translation.
Let me remind you that human consciousness is capable of reflecting the world around us in the form of two signal systems. The first signal system perceives the world around us through the senses. As a result of influence on one of the senses (vision, hearing, touch, smell, taste), a sensation arises. Based on the totality of sensations associated with a certain object, a person develops a holistic perception of this object. A perceived object can be stored in memory in the form of a corresponding representation of it without direct sensory contact.
The second signaling system allows a person, abstracting from specific objects, to form generalized concepts about the world around him. A concept differs in its volume, that is, the class of objects generalized in the concept, and the content of the concept - the characteristics of the objects through which the generalization is carried out. People operate with concepts in the process of communication. To do this, certain labels are assigned to each concept - their names in the form of individual words or (more often) phrases. Moreover, in different languages can be used to denote the same concepts different signs(snowdrop - snowdrop, eye - dog - guide dog, vacuumcleaner - vacuum cleaner).
Taking into account the stated principles, the phraseological machine translation system in general outline as follows. As already mentioned, the most stable elements of the text are the names of concepts. During the translation process, the names of the concepts of the source text are replaced with the names of these units of meaning in the target language and the resulting new text is formatted in accordance with the grammatical norms of the target language. As in “Translationmemory” systems, the principle of analogy is used - words, phrases and phrases that reflect typical situations are translated by analogy with previously completed translations of these units. The difference between them is that in systems like “translation memory” they use not such stable sections of text as concepts and typical situations, but all sentences found in the source text.
From the above it follows that machine dictionaries are the most important component of phraseological machine translation systems. The number of different words in languages such as Russian and English exceeds one million, and the number of relatively stable phraseological phrases amounts to hundreds of millions. It will not be possible to quickly create phraseological dictionaries of such a volume. So, the volume of the vocabulary of one of modern systems"RetransVista" has 3 million 300 thousand dictionary entries.
Compiling phraseological dictionaries of large volumes will require significant time expenditure, therefore, in machine translation systems constant companion phraseological phrases will also contain individual words. To translate them, as mentioned, the provisions of the semantic model are used, but the quality of machine translation raises many complaints.
This is certainly true, but word-by-word translation of texts is much better than
lack of any translation.
Hence, as many experts in this field believe, the only reasonable prospect for machine translation systems in the 21st century is a combination of phraseological and word-by-word semantic translation. At the same time, the specific weight of phraseological translation, apparently, should constantly increase, and the specific weight of semantic translation should constantly decrease.
Experience shows that machine translation systems should be focused primarily on the translation of business texts in the fields of science, technology, politics and economics. Translation literary texts- a more difficult task. But here, too, in the future it is possible to achieve a certain success if there are enthusiasts like Vladimir Dahl who, with the help of modern technical means will take on the hard work of compiling powerful phraseological dictionaries for this type of text.
Additional literature.
1. Belonogov G.G. On the use of the principle of analogy in automatic processing of text information. Sat. "Problems of Cybernetics", No. 28, 1974.
2. Ubin I.I. Modern translation automation tools: hopes, disappointments and reality. Sat. "Transfer to modern world", M., VCP, 2001, pp. 60-69.
Currently, there are three types of machine translation systems:
Systems based on grammatical rules (Rule-Based Machine Translation, RBMT);
Statistical systems (Statistical Machine Translation, SMT);
Hybrid systems;
Systems based on grammatical rules analyze the text that is used in the translation process. Translation is carried out on the basis of built-in dictionaries for a given language pair, as well as grammars covering semantic, morphological, syntactic patterns of both languages. Based on all this data, the source text is sequentially, sentence by sentence, converted into text in the required language. The basic principle of operation of such systems is the connection between the structures of the source and target texts.
Systems based on grammatical rules are often divided into three further subgroups - word-by-word translation systems, transfer systems and interlinguistic systems.
The advantages of systems based on grammatical rules are grammatical and syntactic accuracy, stability of the result, and the ability to customize for a specific subject area. The disadvantages of systems based on grammatical rules include the need to create, maintain and update linguistic databases, the complexity of creating such a system, as well as its high cost.
Statistical systems use statistical analysis in their work. A bilingual text corpus is loaded into the system (containing a large amount of text in the source language and its “manual” translation into the required language), after which the system analyzes the statistics of interlingual correspondences, syntactic structures, etc. The system is self-learning - when choosing a translation option, it relies on based on previously obtained statistics. The larger the dictionary within a language pair and the more accurately it is compiled, the better the result of statistical machine translation. With each new translated text, the quality of subsequent translations improves.
Statistical systems are quick to set up and easy to add new translation areas. Among the shortcomings, the most significant are the presence of numerous grammatical errors and the instability of the translation.
Hybrid systems combine the approaches described earlier. It is expected that hybrid machine translation systems will combine all the advantages of statistical and rule-based systems.
1.3 Classification of machine translation systems
Machine translation systems are programs that perform fully automated translation. The main criterion of the program is the quality of translation. In addition, important points for the user are the convenience of the interface, ease of integration of the program with other document processing tools, choice of topics, and a dictionary replenishment utility. With the advent of the Internet, major machine translation vendors included Web interfaces in their products, while ensuring their integration with other software and e-mail, allowing the use of MT engines for the translation of Web pages, electronic correspondence, and online conversation sessions.
New members of CompuServe's Foreign Language Forum often ask if anyone can recommend a good machine translation program at a reasonable price.
The answer to this question is invariably “no.” Depending on the person answering, the answer may contain two main arguments: either that machines cannot translate, or that machine translation is too expensive.
Both of these arguments are valid to a certain extent. However, the answer is far from so simple. When studying the problem of machine translation (MT), it is necessary to consider separately the various subsections of this problem. The following division is based on lectures by Larry Childs given at the 1990 International Technical Communication Conference:
Fully automatic translation;
Automated machine translation with human participation;
Translation carried out by a person using a computer.
Fully automated machine translation. This type of machine translation is what most people mean when they talk about machine translation. The meaning here is simple: text in one language is entered into the computer, this text is processed and the computer displays the same text in another language. Unfortunately, the implementation of this type of automatic translation faces certain obstacles that still need to be overcome.
The main problem is the complexity of the language itself. Take, for example, the meanings of the word "can". In addition to the basic meaning of a modal auxiliary verb, the word "can" has several formal and slang meanings as a noun: "can", "latrine", "prison". In addition, there is an archaic meaning of this word - “to know or understand.” Assuming that the output language has a separate word for each of these meanings, how can a computer differentiate between them?
As it turns out, some progress has been made in the development of translation programs that differentiate meaning based on context. More recent studies rely more on probability theories when analyzing texts. However, fully automated machine translation of texts with extensive subject matter is still an impossible task.
Automated machine translation with human participation. This type of machine translation is now entirely feasible. When we talk about human-assisted machine translation, we usually mean editing texts both before and after they are processed by a computer. Human translators change texts so that they are understandable to machines. After the computer has done the translation, humans again edit the rough machine translation, making the text in the output language correct. In addition to this operating procedure, there are MT systems that during translation require the constant presence of a human translator to help the computer translate particularly complex or ambiguous structures.
Human-assisted machine translation is applicable to a greater extent to texts with a limited vocabulary and narrowly limited subject matter.
The cost-effectiveness of using human-assisted machine translation is still a controversial issue. The programs themselves are usually quite expensive, and some of them require special equipment to run. Pre- and post-editing requires a learning curve, and it's not a pleasant job. Creating and maintaining word databases is a labor-intensive process and often requires special skills. However, for an organization translating large volumes of text in a well-defined subject area, human-assisted machine translation can be a fairly cost-effective alternative to traditional human translation.
Translation carried out by a person using a computer. In this approach, the human translator is placed at the center of the translation process, while the computer program is regarded as a tool that makes the translation process more efficient and the translation accurate. These are ordinary electronic dictionaries that provide translation of the required word, placing responsibility on the person for the choice the desired option and the meaning of the translated text. Such dictionaries greatly facilitate the translation process, but require the user to have a certain knowledge of the language and spend time on its implementation. And yet the translation process itself is significantly faster and easier.
Among the systems that help a translator in his work, the most important place is occupied by the so-called Translation Memory (TM) systems. TM systems are an interactive tool for accumulating in a database pairs of equivalent text segments in the original language and translation with the possibility of their subsequent search and editing. These software products do not aim to use highly intelligent information technologies, but, on the contrary, are based on using the creative potential of the translator. In the process of work, the translator himself creates a database (or receives it from other translators or from the customer), and the more units it contains, the greater the return on its use.
Here is a list of the most famous TM systems:
Transit from the Swiss company Star,
Trados (USA),
Translation Manager from IBM,
Eurolang Optimizer from the French company LANT,
DejaVu from ATRIL (USA),
WordFisher (Hungary).
TM systems make it possible to eliminate repeated translation of identical text fragments. The translation of a segment is carried out by the translator only once, and then each subsequent segment is checked for a match (full or fuzzy) with the database, and if an identical or similar segment is found, it is offered as a translation option.
Currently, developments are underway to improve TM systems. For example, the core of Star's Transit system is implemented based on neural network technology.
Despite the wide range of TM systems, they share several common features:
Alignment function. One of the advantages of TM systems is the ability to use already translated materials on a given topic. The TM database can be obtained by segment-by-segment comparison of the original and translation files.
Availability of import and export filters. This property ensures compatibility of TM systems with a variety of word processors and publishing systems and gives the translator relative independence from the customer.
A mechanism for searching fuzzy or complete matches. It is this mechanism that represents the main advantage of TM systems. If, when translating a text, the system encounters a segment that is identical or close to the previously translated one, then the already translated segment is offered to the translator as an option for translating the current segment, which can be corrected. The degree of fuzzy matching is specified by the user.
Support for thematic dictionaries. This feature helps the translator stick to the glossary. As a rule, if a word or phrase from a thematic dictionary occurs in a translated segment, it is highlighted in color and its translation is suggested, which can be inserted into the translated text automatically.
Tools for searching text fragments. This tool is very convenient when editing translations. If during the work more than good option translation of any text fragment, then this fragment can be found in all TM segments, after which the necessary changes are sequentially made to the TM segments.
Of course, like any software product, TM systems have their advantages and disadvantages, and their scope of application. However, regarding TM systems, the main disadvantage is their high cost.
It is especially convenient to use TM systems when translating documents such as user manuals, operating instructions, design and business documentation, product catalogs and other similar documentation with a large number of matches.