The genetic code is encoded. What is a genetic code: general information
Lecture 5. Genetic code
Definition of the concept
The genetic code is a system for recording information about the sequence of amino acids in proteins using the sequence of nucleotides in DNA.
Since DNA is not directly involved in protein synthesis, the code is written in RNA language. RNA contains uracil instead of thymine.
Properties of the genetic code
1. Triplety
Each amino acid is encoded by a sequence of 3 nucleotides.
Definition: a triplet or codon is a sequence of three nucleotides encoding one amino acid.
The code cannot be monoplet, since 4 (the number of different nucleotides in DNA) is less than 20. The code cannot be doublet, because 16 (the number of combinations and permutations of 4 nucleotides by 2) is less than 20. The code can be triplet, because 64 (the number of combinations and permutations from 4 to 3) is more than 20.
2. Degeneracy.
All amino acids, with the exception of methionine and tryptophan, are encoded by more than one triplet:
2 AK for 1 triplet = 2.
9 AK, 2 triplets each = 18.
1 AK 3 triplets = 3.
5 AK of 4 triplets = 20.
3 AK of 6 triplets = 18.
A total of 61 triplets encode 20 amino acids.
3. Presence of intergenic punctuation marks.
Definition:
Gene - a section of DNA that encodes one polypeptide chain or one molecule tRNA, rRNA orsRNA.
GenestRNA, rRNA, sRNAproteins are not coded.
At the end of each gene encoding a polypeptide there is at least one of 3 triplets encoding RNA stop codons, or stop signals. In mRNA they have the following form: UAA, UAG, UGA . They terminate (end) the broadcast.
Conventionally, the codon also belongs to punctuation marks AUG - the first after the leader sequence. (See Lecture 8) It functions as a capital letter. In this position it encodes formylmethionine (in prokaryotes).
4. Unambiguity.
Each triplet encodes only one amino acid or is a translation terminator.
The exception is the codon AUG . In prokaryotes, in the first position (capital letter) it encodes formylmethionine, and in any other position it encodes methionine.
5. Compactness, or absence of intragenic punctuation marks.
Within a gene, each nucleotide is part of a significant codon.
In 1961, Seymour Benzer and Francis Crick experimentally proved the triplet nature of the code and its compactness.
The essence of the experiment: “+” mutation - insertion of one nucleotide. "-" mutation - loss of one nucleotide. A single "+" or "-" mutation at the beginning of a gene spoils the entire gene. A double "+" or "-" mutation also spoils the entire gene.
A triple “+” or “-” mutation at the beginning of a gene spoils only part of it. A quadruple “+” or “-” mutation again spoils the entire gene.
The experiment proves that The code is transcribed and there is no punctuation marks inside the gene. The experiment was carried out on two adjacent phage genes and showed, in addition, presence of punctuation marks between genes.
6. Versatility.
The genetic code is the same for all creatures living on Earth.
In 1979, Burrell opened ideal human mitochondria code.
Definition:
It's called "ideal" genetic code, in which the rule of degeneracy of the quasi-doublet code is satisfied: If in two triplets the first two nucleotides coincide, and the third nucleotides belong to the same class (both are purines or both are pyrimidines), then these triplets code for the same amino acid.
There are two exceptions to this rule in the universal code. Both deviations from the ideal code in the universal relate to fundamental points: the beginning and end of protein synthesis:
Codon | Universal code | Mitochondrial codes |
|||
Vertebrates | Invertebrates | Yeast | Plants |
||
STOP | STOP |
||||
With UA | |||||
A G A | STOP | ||||
STOP | 230 substitutions do not change the class of the encoded amino acid. to tearability. In 1956, Georgiy Gamow proposed a variant of the overlapping code. According to the Gamow code, each nucleotide, starting from the third in the gene, is part of 3 codons. When the genetic code was deciphered, it turned out that it was non-overlapping, i.e. Each nucleotide is part of only one codon. Advantages of an overlapping genetic code: compactness, less dependence of the protein structure on the insertion or deletion of a nucleotide. Disadvantage: the protein structure is highly dependent on nucleotide replacement and restrictions on neighbors. In 1976, the DNA of phage φX174 was sequenced. It has single-stranded circular DNA consisting of 5375 nucleotides. The phage was known to encode 9 proteins. For 6 of them, genes located one after another were identified. It turned out that there is an overlap. Gene E is located entirely within the gene D . Its start codon results from a frame shift of one nucleotide. Gene J starts where the gene ends D . Start codon of the gene J overlaps with the stop codon of the gene D as a result of a shift of two nucleotides. The construction is called a “reading frameshift” by a number of nucleotides not a multiple of three. To date, overlap has only been shown for a few phages. Information capacity of DNA There are 6 billion people living on Earth. Hereditary information about them 4x10 13 book pages. These pages would take up the space of 6 NSU buildings. 6x10 9 sperm take up half a thimble. Their DNA takes up less than a quarter of a thimble. | ||||
Chemical composition and structural organization of the DNA molecule.
Molecules nucleic acids are very long chains consisting of many hundreds and even millions of nucleotides. Any nucleic acid contains only four types of nucleotides. The functions of nucleic acid molecules depend on their structure, the nucleotides they contain, their number in the chain and the sequence of the compound in the molecule.
Each nucleotide consists of three components: a nitrogenous base, a carbohydrate and a phosphoric acid. IN compound each nucleotide DNA includes one of four types of nitrogenous bases (adenine - A, thymine - T, guanine - G or cytosine - C), as well as deoxyribose carbon and a phosphoric acid residue.
Thus, DNA nucleotides differ only in the type of nitrogenous base.
The DNA molecule consists of a huge number of nucleotides connected in a chain in a certain sequence. Each type of DNA molecule has its own number and sequence of nucleotides.
DNA molecules are very long. For example, to write down the sequence of nucleotides in DNA molecules from one human cell (46 chromosomes) in letters would require a book of about 820,000 pages. Alternating four types of nucleotides can form infinite set variants of DNA molecules. These structural features of DNA molecules allow them to store a huge amount of information about all the characteristics of organisms.
In 1953, the American biologist J. Watson and the English physicist F. Crick created a model of the structure of the DNA molecule. Scientists have found that each DNA molecule consists of two chains, interconnected and spirally twisted. It looks like a double helix. In each chain, four types of nucleotides alternate in a specific sequence.
Nucleotide DNA composition varies among different types bacteria, fungi, plants, animals. But it does not change with age, it depends little on changes environment. Nucleotides are paired, that is, the number of adenine nucleotides in any DNA molecule is equal to the number of thymidine nucleotides (A-T), and the number of cytosine nucleotides is equal to the number of guanine nucleotides (C-G). This is due to the fact that the connection of two chains to each other in a DNA molecule is subject to a certain rule, namely: adenine of one chain is always connected by two hydrogen bonds only with Thymine of the other chain, and guanine - by three hydrogen bonds with cytosine, that is, the nucleotide chains of one molecule DNA is complementary, complementing each other.
Nucleic acid molecules - DNA and RNA - are made up of nucleotides. DNA nucleotides include a nitrogenous base (A, T, G, C), the carbohydrate deoxyribose and a phosphoric acid molecule residue. The DNA molecule is double helix, consisting of two chains connected by hydrogen bonds according to the principle of complementarity. The function of DNA is to store hereditary information.
Properties and functions of DNA.
DNA is a carrier genetic information, recorded as a sequence of nucleotides using the genetic code. DNA molecules are associated with two fundamental properties of living things organisms - heredity and variability. During a process called DNA replication, two copies of the original strand are formed, which are inherited by daughter cells when they divide, so that the resulting cells are genetically identical to the original.
Genetic information is realized during gene expression in the processes of transcription (synthesis of RNA molecules on a DNA template) and translation (synthesis of proteins on an RNA template).
The sequence of nucleotides “encodes” information about various types RNA: informational or matrix (mRNA), ribosomal (rRNA) and transport (tRNA). All these types of RNA are synthesized from DNA during the process of transcription. Their role in protein biosynthesis (translation process) is different. Messenger RNA contains information about the sequence of amino acids in a protein, ribosomal RNA serves as the basis for ribosomes (complex nucleoprotein complexes, the main function of which is the assembly of proteins from individual amino acids based on mRNA), transfer RNAs deliver amino acids to the site of protein assembly - to the active center of the ribosome, " crawling" on mRNA.
Genetic code, its properties.
Genetic code- a method characteristic of all living organisms of encoding the amino acid sequence of proteins using a sequence of nucleotides. PROPERTIES:
- Triplety- a meaningful unit of code is a combination of three nucleotides (triplet, or codon).
- Continuity- there are no punctuation marks between triplets, that is, the information is read continuously.
- Non-overlapping- the same nucleotide cannot simultaneously be part of two or more triplets (not observed for some overlapping genes of viruses, mitochondria and bacteria, which encode several frameshift proteins).
- Uniqueness (specificity)- a specific codon corresponds to only one amino acid (however, the UGA codon has Euplotes crassus encodes two amino acids - cysteine and selenocysteine)
- Degeneracy (redundancy)- several codons can correspond to the same amino acid.
- Versatility- the genetic code works the same in organisms of different levels of complexity - from viruses to humans (methods are based on this genetic engineering; there are a number of exceptions, shown in the table in the Variations in the Standard Genetic Code section below).
- Noise immunity- mutations of nucleotide substitutions that do not lead to a change in the class of the encoded amino acid are called conservative; nucleotide substitution mutations that lead to a change in the class of the encoded amino acid are called radical.
5. Autoreproduction of DNA. Replicon and its functioning .
The process of self-reproduction of nucleic acid molecules, accompanied by inheritance (from cell to cell) exact copies genetic information; R. carried out with the participation of a set of specific enzymes (helicase<helicase>controlling the unwinding of the molecule DNA, DNA-polymerase<DNA polymerase> I and III, DNA-ligase<DNA ligase>), proceeds in a semi-conservative manner with the formation of a replication fork<replication fork>; on one of the circuits<leading strand> the synthesis of the complementary chain is continuous, and on the other<lagging strand> occurs due to the formation of Dkazaki fragments<Okazaki fragments>; R. - a high-precision process, the error rate of which does not exceed 10 -9; in eukaryotes R. can occur at several points of one molecule at once DNA; speed R. eukaryotes have about 100, and bacteria have about 1000 nucleotides per second.
6. Levels of eukaryotic genome organization .
In eukaryotic organisms, the mechanism of transcription regulation is much more complex. As a result of cloning and sequencing of eukaryotic genes, specific sequences involved in transcription and translation were discovered.
A eukaryotic cell is characterized by:
1. The presence of introns and exons in the DNA molecule.
2. Maturation of mRNA - excision of introns and stitching of exons.
3. The presence of regulatory elements that regulate transcription, such as: a) promoters - 3 types, each of which is occupied by a specific polymerase. Pol I replicates ribosomal genes, Pol II replicates protein structural genes, Pol III replicates genes encoding small RNAs. The Pol I and Pol II promoter are located in front of the transcription initiation site, the Pol III promoter is within the structural gene; b) modulators - DNA sequences that enhance the level of transcription; c) amplifiers - sequences that enhance the level of transcription and act regardless of their position relative to the coding part of the gene and the state of the starting point of RNA synthesis; d) terminators - specific sequences that stop both translation and transcription.
These sequences differ from prokaryotic sequences in their primary structure and location relative to the start codon, and bacterial RNA polymerase does not “recognize” them. Thus, for the expression of eukaryotic genes in prokaryotic cells, the genes must be under the control of prokaryotic regulatory elements. This circumstance must be taken into account when constructing expression vectors.
7. Chemical and structural composition of chromosomes .
Chemical chromosome composition - DNA - 40%, Histone proteins - 40%. Non-histone - 20% some RNA. Lipids, polysaccharides, metal ions.
The chemical composition of a chromosome is a complex of nucleic acids with proteins, carbohydrates, lipids and metals. The chromosome regulates gene activity and restores it in the event of chemical or radiation damage.
STRUCTURAL????
Chromosomes- nucleoprotein structural elements cell nuclei containing DNA, which contains the hereditary Information of the organism, are capable of self-reproduction, have structural and functional individuality and retain it over a number of generations.
in the mitotic cycle the following features of the structural organization of chromosomes are observed:
There are mitotic and interphase forms of the structural organization of chromosomes, mutually transforming into each other in the mitotic cycle - these are functional and physiological transformations
8. Levels of packaging of hereditary material in eukaryotes .
Structural and functional levels of organization of hereditary material of eukaryotes
Heredity and variability provide:
1) individual (discrete) inheritance and change of individual characteristics;
2) reproduction in individuals of each generation of the entire complex of morphofunctional characteristics of organisms of a particular biological species;
3) redistribution in species with sexual reproduction in the process of reproduction of hereditary inclinations, as a result of which the descendant has a combination of characteristics that is different from their combination in the parents. The patterns of inheritance and variability of traits and their sets follow from the principles of the structural and functional organization of genetic material.
There are three levels of organization of the hereditary material of eukaryotic organisms: gene, chromosomal and genomic (genotype level).
Elementary structure gene level serves as a gene. The transfer of genes from parents to offspring is necessary for the development of certain characteristics. Although several forms of biological variability are known, only a violation of the structure of genes changes the meaning of hereditary information, in accordance with which specific characteristics and properties are formed. Due to the presence of the gene level, individual, separate (discrete) and independent inheritance and changes in individual characteristics are possible.
Genes in eukaryotic cells are distributed in groups along chromosomes. These are the structures of the cell nucleus, which are characterized by individuality and the ability to reproduce themselves with the preservation of individual structural features over generations. The presence of chromosomes determines the identification of the chromosomal level of organization of hereditary material. The placement of genes on chromosomes influences the relative inheritance of traits and makes it possible for the function of a gene to be influenced by its immediate genetic environment - neighboring genes. The chromosomal organization of hereditary material serves a necessary condition redistribution of hereditary inclinations of parents in offspring during sexual reproduction.
Despite the distribution on different chromosomes, the entire set of genes functionally behaves as a whole, forming unified system, representing the genomic (genotypic) level of organization of hereditary material. At this level, there is a wide interaction and mutual influence of hereditary inclinations, localized both in one and in different chromosomes. The result is the mutual correspondence of genetic information of different hereditary inclinations and, consequently, the development of traits balanced in time, place and intensity in the process of ontogenesis. The functional activity of genes, the mode of replication and mutational changes in the hereditary material also depend on the characteristics of the genotype of the organism or cell as a whole. This is evidenced, for example, by the relativity of the property of dominance.
Eu - and heterochromatin.
Some chromosomes appear condensed and intensely colored during cell division. Such differences were called heteropyknosis. The term " heterochromatin" There are euchromatin - the main part of mitotic chromosomes, which undergoes the usual cycle of compaction and decompaction during mitosis, and heterochromatin- regions of chromosomes that are constantly in a compact state.
In most species of eukaryotes, chromosomes contain both ew- and heterochromatic regions, the latter making up a significant part of the genome. Heterochromatin located in pericentromeric, sometimes in peritomeric regions. Heterochromatic regions were discovered in the euchromatic arms of chromosomes. They look like inclusions (intercalations) of heterochromatin into euchromatin. Such heterochromatin called intercalary. Chromatin compaction. Euchromatin and heterochromatin differ in compaction cycles. Euhr. goes through a full cycle of compaction-decompaction from interphase to interphase, hetero. maintains a state of relative compactness. Differential stainability. Different areas of heterochromatin are stained with different dyes, some areas with one, others with several. By using various dyes and using chromosomal rearrangements that break up heterochromatic regions, it has been possible to characterize many small regions in Drosophila where the affinity for the stains is different from neighboring regions.
10. Morphological features of the metaphase chromosome .
The metaphase chromosome consists of two longitudinal strands of deoxyribonucleoprotein - chromatids, connected to each other in the region of the primary constriction - the centromere. Centromere - in a special way organized site chromosomes common to both sister chromatids. The centromere divides the chromosome body into two arms. Depending on the location of the primary constriction, there are following types chromosomes: equal arms (metacentric), when the centromere is located in the middle and the arms are approximately equal length; unequal arms (submetacentric), when the centromere is displaced from the middle of the chromosome and the arms are of unequal length; rod-shaped (acrocentric), when the centromere is shifted to one end of the chromosome and one arm is very short. There are also point (telocentric) chromosomes; they lack one arm, but they are not present in the human karyotype (chromosomal set). Some chromosomes may have secondary constrictions that separate a region called a satellite from the chromosome body.
GENETIC CODE, a system for recording hereditary information in the form of a sequence of nucleotide bases in DNA molecules (in some viruses - RNA), which determines the primary structure (location of amino acid residues) in protein molecules (polypeptides). The problem of the genetic code was formulated after proving the genetic role of DNA (American microbiologists O. Avery, K. McLeod, M. McCarthy, 1944) and deciphering its structure (J. Watson, F. Crick, 1953), after establishing that genes determine the structure and functions of enzymes (the principle of “one gene - one enzyme” by J. Beadle and E. Tatem, 1941) and that there is a dependence of the spatial structure and activity of a protein on its primary structure (F. Sanger, 1955). The question of how combinations of 4 nucleic acid bases determine the alternation of 20 common amino acid residues in polypeptides was first posed by G. Gamow in 1954.
Based on an experiment in which they studied the interactions of insertions and deletions of a pair of nucleotides, in one of the genes of the T4 bacteriophage, F. Crick and other scientists in 1961 determined general properties genetic code: triplet, i.e. each amino acid residue in the polypeptide chain corresponds to a set of three bases (triplet, or codon) in the DNA of the gene; reading of codons within a gene occurs from a fixed point, in one direction and “without commas”, that is, the codons are not separated by any signs from each other; degeneracy, or redundancy - the same amino acid residue can be encoded by several codons (synonymous codons). The authors assumed that the codons do not overlap (each base belongs to only one codon). Direct study of the coding capacity of triplets was continued using a cell-free protein synthesis system under the control of synthetic messenger RNA (mRNA). By 1965, the genetic code was completely deciphered in the works of S. Ochoa, M. Nirenberg and H. G. Korana. Unraveling the secrets of the genetic code was one of the outstanding achievements of biology in the 20th century.
The implementation of the genetic code in a cell occurs during two matrix processes - transcription and translation. The mediator between the gene and the protein is mRNA, which is formed during transcription on one of the DNA strands. In this case, the sequence of DNA bases, which carries information about the primary structure of the protein, is “rewritten” in the form of a sequence of mRNA bases. Then, during translation on ribosomes, the nucleotide sequence of the mRNA is read by transfer RNAs (tRNAs). The latter have an acceptor end, to which an amino acid residue is attached, and an adapter end, or anticodon triplet, which recognizes the corresponding mRNA codon. The interaction of a codon and an anti-codon occurs on the basis of complementary base pairing: Adenine (A) - Uracil (U), Guanine (G) - Cytosine (C); in this case, the base sequence of the mRNA is translated into the amino acid sequence of the synthesized protein. Various organisms They use different synonymous codons with different frequencies for the same amino acid. Reading of the mRNA encoding the polypeptide chain begins (initiates) with the AUG codon corresponding to the amino acid methionine. Less commonly, in prokaryotes, the initiation codons are GUG (valine), UUG (leucine), AUU (isoleucine), and in eukaryotes - UUG (leucine), AUA (isoleucine), ACG (threonine), CUG (leucine). This sets the so-called frame, or phase, of reading during translation, that is, then the entire nucleotide sequence of the mRNA is read triplet by triplet of tRNA until any of the three terminator codons, often called stop codons, are encountered on the mRNA: UAA, UAG , UGA (table). Reading of these triplets leads to the completion of the synthesis of the polypeptide chain.
AUG and stop codons appear at the beginning and end of the regions of mRNA encoding polypeptides, respectively.
The genetic code is quasi-universal. This means that there are slight variations in the meaning of some codons in different objects, and this applies, first of all, to terminator codons, which can be significant; for example, in the mitochondria of some eukaryotes and mycoplasmas, UGA encodes tryptophan. In addition, in some mRNAs of bacteria and eukaryotes, UGA encodes an unusual amino acid - selenocysteine, and UAG in one of the archaebacteria - pyrrolysine.
There is a point of view according to which the genetic code arose by chance (the “frozen chance” hypothesis). It's more likely that it evolved. This assumption is supported by the existence of a simpler and, apparently, more ancient version of the code, which is read in mitochondria according to the “two out of three” rule, when the amino acid is determined by only two of the three bases in the triplet.
Lit.: Crick F. N. a. O. General nature of the genetic code for proteins // Nature. 1961. Vol. 192; The genetic code. N.Y., 1966; Ichas M. Biological code. M., 1971; Inge-Vechtomov S.G. How the genetic code is read: rules and exceptions // Modern natural science. M., 2000. T. 8; Ratner V. A. Genetic code as a system // Soros educational journal. 2000. T. 6. No. 3.
S. G. Inge-Vechtomov.
The genetic code is a system for recording hereditary information in nucleic acid molecules, based on a certain alternation of nucleotide sequences in DNA or RNA, forming codons corresponding to amino acids in a protein.
Properties of the genetic code.
The genetic code has several properties.
Tripletity.
Degeneracy or redundancy.
Unambiguity.
Polarity.
Non-overlapping.
Compactness.
Versatility.
It should be noted that some authors also propose other properties of the code related to chemical features included in the code of nucleotides or with the frequency of occurrence of individual amino acids in the proteins of the body, etc. However, these properties follow from those listed above, so we will consider them there.
A. Tripletity. The genetic code, like many things, is complicated organized system has the smallest structural and smallest functional unit. A triplet is the smallest structural unit of the genetic code. It consists of three nucleotides. Codon - smallest functional unit genetic code. Typically, triplets of mRNA are called codons. In the genetic code, a codon performs several functions. Firstly, its main function is that it encodes a single amino acid. Secondly, the codon may not code for an amino acid, but, in this case, it performs another function (see below). As can be seen from the definition, a triplet is a concept that characterizes elementary structural unit genetic code (three nucleotides). Codon – characterizes elementary semantic unit genome - three nucleotides determine the attachment of one amino acid to the polypeptide chain.
The elementary structural unit was first deciphered theoretically, and then its existence was confirmed experimentally. Indeed, 20 amino acids cannot be encoded with one or two nucleotides because there are only 4 of the latter. Three out of four nucleotides give 4 3 = 64 variants, which more than covers the number of amino acids available in living organisms (see Table 1).
The 64 nucleotide combinations presented in table have two features. Firstly, of the 64 variants of triplets, only 61 are codons and encode any amino acid, they are called sense codons. Three triplets do not encode
amino acids a are stop signals indicating the end of translation. There are three such triplets - UAA, UAG, UGA, they are also called “meaningless” (nonsense codons). As a result of a mutation, which is associated with the replacement of one nucleotide in a triplet with another, a nonsense codon can arise from a sense codon. This type of mutation is called nonsense mutation. If such a stop signal is formed inside the gene (in its information part), then during protein synthesis in this place the process will be constantly interrupted - only the first (before the stop signal) part of the protein will be synthesized. A person with this pathology will experience a lack of protein and experience symptoms associated with this deficiency. For example, this kind of mutation was identified in the gene encoding the hemoglobin beta chain. A shortened inactive hemoglobin chain is synthesized, which is quickly destroyed. As a result, a hemoglobin molecule devoid of a beta chain is formed. It is clear that such a molecule is unlikely to fully fulfill its duties. A serious disease occurs that develops as hemolytic anemia (beta-zero thalassemia, from the Greek word “Thalas” - Mediterranean Sea, where this disease was first discovered).
The mechanism of action of stop codons differs from the mechanism of action of sense codons. This follows from the fact that for all codons encoding amino acids, corresponding tRNAs have been found. No tRNAs were found for nonsense codons. Consequently, tRNA does not take part in the process of stopping protein synthesis.
CodonAUG (sometimes GUG in bacteria) not only encode the amino acids methionine and valine, but are alsobroadcast initiator .
b. Degeneracy or redundancy.
61 of the 64 triplets encode 20 amino acids. This three-fold excess of the number of triplets over the number of amino acids suggests that two coding options can be used in the transfer of information. Firstly, not all 64 codons can be involved in encoding 20 amino acids, but only 20 and, secondly, amino acids can be encoded by several codons. Research has shown that nature used the latter option.
His preference is obvious. If out of 64 variant triplets only 20 were involved in encoding amino acids, then 44 triplets (out of 64) would remain non-coding, i.e. meaningless (nonsense codons). Previously, we pointed out how dangerous it is for the life of a cell to transform a coding triplet as a result of mutation into a nonsense codon - this significantly disrupts normal work RNA polymerases, ultimately leading to the development of diseases. Currently, three codons in our genome are nonsense, but now imagine what would happen if the number of nonsense codons increased by about 15 times. It is clear that in such a situation the transition of normal codons to nonsense codons will be immeasurably higher.
A code in which one amino acid is encoded by several triplets is called degenerate or redundant. Almost every amino acid has several codons. Thus, the amino acid leucine can be encoded by six triplets - UUA, UUG, TSUU, TsUC, TsUA, TsUG. Valine is encoded by four triplets, phenylalanine by two and only tryptophan and methionine encoded by one codon. The property that is associated with recording the same information with different symbols is called degeneracy.
The number of codons designated for one amino acid correlates well with the frequency of occurrence of the amino acid in proteins.
And this is most likely not accidental. The higher the frequency of occurrence of an amino acid in a protein, the more often the codon of this amino acid is represented in the genome, the higher the likelihood of its damage by mutagenic factors. Therefore, it is clear that a mutated codon has a greater chance of encoding the same amino acid if it is highly degenerate. From this perspective, the degeneracy of the genetic code is a mechanism that protects the human genome from damage.
It should be noted that the term degeneracy is used in molecular genetics in another sense. Thus, the bulk of the information in a codon is contained in the first two nucleotides; the base in the third position of the codon turns out to be of little importance. This phenomenon is called “degeneracy of the third base.” Last feature minimizes the effect of mutations. For example, it is known that the main function of red blood cells is to transport oxygen from the lungs to the tissues and carbon dioxide from the tissues to the lungs. This function is performed by the respiratory pigment - hemoglobin, which fills the entire cytoplasm of the erythrocyte. It consists of a protein part - globin, which is encoded by the corresponding gene. In addition to protein, the hemoglobin molecule contains heme, which contains iron. Mutations in globin genes lead to the appearance various options hemoglobins. Most often, mutations are associated with replacing one nucleotide with another and the appearance of a new codon in the gene, which may encode a new amino acid in the hemoglobin polypeptide chain. In a triplet, as a result of mutation, any nucleotide can be replaced - the first, second or third. Several hundred mutations are known that affect the integrity of the globin genes. Near 400 of which are associated with the replacement of single nucleotides in a gene and the corresponding amino acid replacement in a polypeptide. Of these only 100 replacements lead to instability of hemoglobin and various kinds of diseases from mild to very severe. 300 (approximately 64%) substitution mutations do not affect hemoglobin function and do not lead to pathology. One of the reasons for this is the above-mentioned “degeneracy of the third base,” when a replacement of the third nucleotide in a triplet encoding serine, leucine, proline, arginine and some other amino acids leads to the appearance of a synonymous codon encoding the same amino acid. Such a mutation will not manifest itself phenotypically. In contrast, any replacement of the first or second nucleotide in a triplet in 100% of cases leads to the appearance of a new hemoglobin variant. But even in this case, there may not be severe phenotypic disorders. The reason for this is the replacement of an amino acid in hemoglobin with another one similar to the first one. physical and chemical properties. For example, if an amino acid with hydrophilic properties is replaced by another amino acid, but with the same properties.
Hemoglobin consists of the iron porphyrin group of heme (oxygen and carbon dioxide molecules are attached to it) and protein - globin. Adult hemoglobin (HbA) contains two identical -chains and two -chains. Molecule -chain contains 141 amino acid residues, -chain - 146, - And -chains differ in many amino acid residues. The amino acid sequence of each globin chain is encoded by its own gene. Gene encoding -the chain is located in the short arm of chromosome 16, -gene - in the short arm of chromosome 11. Substitution in the gene encoding -the hemoglobin chain of the first or second nucleotide almost always leads to the appearance of new amino acids in the protein, disruption of hemoglobin functions and serious consequences for the patient. For example, replacing “C” in one of the triplets CAU (histidine) with “Y” will lead to the appearance of a new triplet UAU, encoding another amino acid - tyrosine. Phenotypically this will manifest itself in a severe disease.. A similar substitution in position 63 -chain of histidine polypeptide to tyrosine will lead to destabilization of hemoglobin. The disease methemoglobinemia develops. Replacement, as a result of mutation, of glutamic acid with valine in the 6th position -chain is the cause of the most severe disease - sickle cell anemia. Let's not continue the sad list. Let us only note that when replacing the first two nucleotides, an amino acid with physicochemical properties similar to the previous one may appear. Thus, replacement of the 2nd nucleotide in one of the triplets encoding glutamic acid (GAA) in -chain with “U” leads to the appearance of a new triplet (GUA), encoding valine, and replacing the first nucleotide with “A” forms the triplet AAA, encoding the amino acid lysine. Glutamic acid and lysine are similar in physicochemical properties - they are both hydrophilic. Valine is a hydrophobic amino acid. Therefore, replacing hydrophilic glutamic acid with hydrophobic valine significantly changes the properties of hemoglobin, which ultimately leads to the development of sickle cell anemia, while replacing hydrophilic glutamic acid with hydrophilic lysine changes the function of hemoglobin to a lesser extent - patients develop a mild form of anemia. As a result of the replacement of the third base, the new triplet can encode the same amino acids as the previous one. For example, if in the CAC triplet uracil was replaced by cytosine and a CAC triplet appeared, then practically no phenotypic changes will be detected in humans. This is understandable, because both triplets code for the same amino acid – histidine.
In conclusion, it is appropriate to emphasize that the degeneracy of the genetic code and the degeneracy of the third base from a general biological point of view are defense mechanisms, which are inherent in evolution in the unique structure of DNA and RNA.
V. Unambiguity.
Each triplet (except nonsense) encodes only one amino acid. Thus, in the direction codon - amino acid the genetic code is unambiguous, in the direction amino acid - codon it is ambiguous (degenerate).
Unambiguous
Amino acid codon
Degenerate
And in this case, the need for unambiguity in the genetic code is obvious. In another option, when translating the same codon, different amino acids would be inserted into the protein chain and, as a result, proteins with different primary structures and different functions would be formed. Cell metabolism would switch to the “one gene – several polypeptides” mode of operation. It is clear that in such a situation the regulatory function of genes would be completely lost.
g. Polarity
Reading information from DNA and mRNA occurs only in one direction. Polarity has important to determine higher order structures (secondary, tertiary, etc.). Earlier we said that structures lower order determine structures of a higher order. Tertiary structure and higher order structures in proteins are formed as soon as the synthesized RNA chain leaves the DNA molecule or the polypeptide chain leaves the ribosome. While the free end of an RNA or polypeptide acquires a tertiary structure, the other end of the chain continues to be synthesized on DNA (if RNA is transcribed) or a ribosome (if a polypeptide is transcribed).
Therefore, the unidirectional process of reading information (during the synthesis of RNA and protein) is essential not only for determining the sequence of nucleotides or amino acids in the synthesized substance, but for the strict determination of secondary, tertiary, etc. structures.
d. Non-overlapping.
The code may be overlapping or non-overlapping. Most organisms have a non-overlapping code. Overlapping code is found in some phages.
The essence of a non-overlapping code is that a nucleotide of one codon cannot simultaneously be a nucleotide of another codon. If the code were overlapping, then the sequence of seven nucleotides (GCUGCUG) could encode not two amino acids (alanine-alanine) (Fig. 33, A) as in the case of a non-overlapping code, but three (if there is one nucleotide in common) (Fig. . 33, B) or five (if two nucleotides are common) (see Fig. 33, C). In the last two cases, a mutation of any nucleotide would lead to a violation in the sequence of two, three, etc. amino acids.
However, it has been established that a mutation of one nucleotide always disrupts the inclusion of one amino acid in a polypeptide. This is a significant argument that the code is non-overlapping.
Let us explain this in Figure 34. Bold lines show triplets encoding amino acids in the case of non-overlapping and overlapping code. Experiments have clearly shown that the genetic code is non-overlapping. Without going into details of the experiment, we note that if you replace the third nucleotide in the sequence of nucleotides (see Fig. 34)U (marked with an asterisk) to some other thing:
1. With a non-overlapping code, the protein controlled by this sequence would have a substitution of one (first) amino acid (marked with asterisks).
2. With an overlapping code in option A, a substitution would occur in two (first and second) amino acids (marked with asterisks). Under option B, the replacement would affect three amino acids (marked with asterisks).
However, numerous experiments have shown that when one nucleotide in DNA is disrupted, the disruption in the protein always affects only one amino acid, which is typical for a non-overlapping code.
GZUGZUG GZUGZUG GZUGZUG
GCU GCU GCU UGC GCU GCU GCU UGC GCU GCU GCU
*** *** *** *** *** ***
Alanin - Alanin Ala - Cis - Ley Ala - Ley - Ley - Ala - Ley
A B C
Non-overlapping code Overlapping code
Rice. 34. A diagram explaining the presence of a non-overlapping code in the genome (explanation in the text).
The non-overlapping nature of the genetic code is associated with another property - the reading of information begins from a certain point - the initiation signal. Such an initiation signal in mRNA is the codon encoding methionine AUG.
It should be noted that humans still have a small number of genes that deviate from general rule and overlap.
e. Compactness.
There is no punctuation between codons. In other words, triplets are not separated from each other, for example, by one meaningless nucleotide. The absence of “punctuation marks” in the genetic code has been proven in experiments.
and. Versatility.
The code is the same for all organisms living on Earth. Direct evidence of the universality of the genetic code was obtained by comparing DNA sequences with corresponding protein sequences. It turned out that all bacterial and eukaryotic genomes use the same sets of code values. There are exceptions, but not many.
The first exceptions to the universality of the genetic code were found in the mitochondria of some animal species. This concerned the terminator codon UGA, which reads the same as the codon UGG, encoding the amino acid tryptophan. Other rarer deviations from universality were also found.
DNA code system.
The genetic code of DNA consists of 64 triplets of nucleotides. These triplets are called codons. Each codon codes for one of the 20 amino acids used in protein synthesis. This gives some redundancy in the code: most amino acids are coded for by more than one codon.
One codon performs two interrelated functions: it signals the beginning of translation and encodes the inclusion of the amino acid methionine (Met) in the growing polypeptide chain. The DNA coding system is designed so that the genetic code can be expressed either as RNA codons or DNA codons. RNA codons are found in RNA (mRNA) and these codons are able to read information during the synthesis of polypeptides (a process called translation). But each mRNA molecule acquires a nucleotide sequence in transcription from the corresponding gene.
All but two amino acids (Met and Trp) can be encoded by 2 to 6 different codons. However, the genome of most organisms shows that certain codons are favored over others. In humans, for example, alanine is encoded by GCC four times more often than by GCG. This probably indicates greater translation efficiency of the translation apparatus (for example, the ribosome) for some codons.

The genetic code is almost universal. The same codons are assigned to the same section of amino acids and the same start and stop signals are overwhelmingly the same in animals, plants and microorganisms. However, some exceptions have been found. Most involve assigning one or two of the three stop codons to an amino acid.
Gene- a structural and functional unit of heredity that controls the development of a specific trait or property. Parents pass on a set of genes to their offspring during reproduction. Russian scientists made a great contribution to the study of the gene: Simashkevich E.A., Gavrilova Yu.A., Bogomazova O.V. (2011)
Currently, in molecular biology it has been established that genes are sections of DNA that carry some kind of integral information - about the structure of one protein molecule or one RNA molecule. These and other functional molecules determine the development, growth and functioning of the body.
At the same time, each gene is characterized by a number of specific regulatory DNA sequences, such as promoters, which are directly involved in regulating the expression of the gene. Regulatory sequences can be located either in close proximity to the open reading frame encoding a protein, or the beginning of an RNA sequence, as is the case with promoters (the so-called cis cis-regulatory elements), and over distances of many millions of base pairs (nucleotides), as in the case of enhancers, insulators and suppressors (sometimes classified as trans-regulatory elements, English. trans-regulatory elements). Thus, the concept of a gene is not limited only to the coding region of DNA, but is a broader concept that also includes regulatory sequences.
Originally the term gene appeared as a theoretical unit for the transmission of discrete hereditary information. The history of biology remembers disputes about which molecules can be carriers of hereditary information. Most researchers believed that only proteins could be such carriers, since their structure (20 amino acids) allows the creation more options than the structure of DNA, which is made up of only four types nucleotides. Later it was experimentally proven that it is DNA that includes hereditary information, which has been expressed as the central dogma of molecular biology.
Genes can undergo mutations - random or targeted changes in the sequence of nucleotides in the DNA chain. Mutations can lead to a change in sequence, and therefore a change biological characteristics protein or RNA, which in turn may result in general or local altered or abnormal functioning of the body. Such mutations in some cases are pathogenic, since they result in disease, or lethal at the embryonic level. However, not all changes in the nucleotide sequence lead to changes in protein structure (due to the effect of degeneracy of the genetic code) or to a significant change in the sequence and are not pathogenic. In particular, the human genome is characterized by single nucleotide polymorphisms and copy number variations. copy number variations), such as deletions and duplications, which account for about 1% of the entire human nucleotide sequence. Single nucleotide polymorphisms, in particular, define different alleles of a single gene.
The monomers that make up each DNA strand are complex organic compounds, including nitrogenous bases: adenine (A) or thymine (T) or cytosine (C) or guanine (G), pentaatomic sugar-pentose-deoxyribose, after which DNA itself was named, as well as a phosphoric acid residue. These compounds are called nucleotides.
Gene properties
- discreteness - immiscibility of genes;
- stability - the ability to maintain structure;
- lability - the ability to mutate repeatedly;
- multiple allelism - many genes exist in a population in multiple molecular forms;
- allelicity - in the genotype of diploid organisms there are only two forms of the gene;
- specificity - each gene encodes its own trait;
- pleiotropy - multiple effect of a gene;
- expressivity - the degree of expression of a gene in a trait;
- penetrance - frequency of manifestation of a gene in a phenotype;
- amplification - increasing the number of copies of a gene.
Classification
- Structural genes are unique components of the genome, representing a single sequence that encodes a specific protein or certain types of RNA. (See also the article genes household).
- Functional genes - regulate the functioning of structural genes.
Genetic code- a method characteristic of all living organisms of encoding the amino acid sequence of proteins using a sequence of nucleotides.
DNA uses four nucleotides - adenine (A), guanine (G), cytosine (C), thymine (T), which in Russian literature are designated by the letters A, G, C and T. These letters make up the alphabet of the genetic code. RNA uses the same nucleotides, with the exception of thymine, which is replaced by a similar nucleotide - uracil, which is designated by the letter U (U in Russian literature). In DNA and RNA molecules, nucleotides are arranged in chains and, thus, sequences of genetic letters are obtained.
Genetic code
To build proteins in nature, 20 different amino acids are used. Each protein is a chain or several chains of amino acids in a strictly defined sequence. This sequence determines the structure of the protein, and therefore all of its biological properties. The set of amino acids is also universal for almost all living organisms.
The implementation of genetic information in living cells (that is, the synthesis of a protein encoded by a gene) is carried out using two matrix processes: transcription (that is, the synthesis of mRNA on a DNA matrix) and translation of the genetic code into an amino acid sequence (synthesis of a polypeptide chain on mRNA). Three consecutive nucleotides are sufficient to encode 20 amino acids, as well as the stop signal indicating the end of the protein sequence. A set of three nucleotides is called a triplet. Accepted abbreviations, corresponding to amino acids and codons, are shown in the figure.
Properties
- Triplety- a meaningful unit of code is a combination of three nucleotides (triplet, or codon).
- Continuity- there are no punctuation marks between triplets, that is, the information is read continuously.
- Non-overlapping- the same nucleotide cannot simultaneously be part of two or more triplets (not observed for some overlapping genes of viruses, mitochondria and bacteria, which encode several frameshift proteins).
- Uniqueness (specificity)- a specific codon corresponds to only one amino acid (however, the UGA codon has Euplotes crassus encodes two amino acids - cysteine and selenocysteine)
- Degeneracy (redundancy)- several codons can correspond to the same amino acid.
- Versatility- the genetic code works the same in organisms of different levels of complexity - from viruses to humans (genetic engineering methods are based on this; there are a number of exceptions, shown in the table in the section “Variations of the standard genetic code” below).
- Noise immunity- mutations of nucleotide substitutions that do not lead to a change in the class of the encoded amino acid are called conservative; nucleotide substitution mutations that lead to a change in the class of the encoded amino acid are called radical.
Protein biosynthesis and its stages
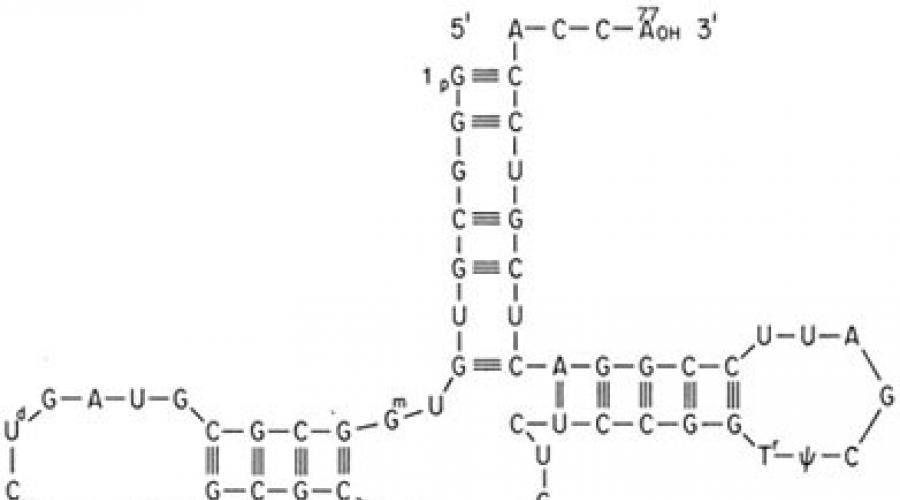
Protein biosynthesis- a complex multi-stage process of synthesis of a polypeptide chain from amino acid residues, occurring on the ribosomes of the cells of living organisms with the participation of mRNA and tRNA molecules.
Protein biosynthesis can be divided into the stages of transcription, processing and translation. During transcription, genetic information encrypted in DNA molecules is read and this information is written into mRNA molecules. During a series of successive processing stages, some fragments that are unnecessary in subsequent stages are removed from the mRNA, and nucleotide sequences are edited. After transporting the code from the nucleus to the ribosomes, the actual synthesis of protein molecules occurs by attaching individual amino acid residues to the growing polypeptide chain.
Between transcription and translation, the mRNA molecule undergoes a series of sequential changes that ensure the maturation of the functioning matrix for the synthesis of the polypeptide chain. A cap is attached to the 5΄-end, and a poly-A tail is attached to the 3΄-end, which increases the lifespan of the mRNA. With the advent of processing in the eukaryotic cell, it became possible to combine gene exons to obtain a greater variety of proteins encoded by a single sequence of DNA nucleotides - alternative splicing.
Translation consists of the synthesis of a polypeptide chain in accordance with the information encoded in messenger RNA. The amino acid sequence is arranged using transport RNA (tRNA), which forms complexes with amino acids - aminoacyl-tRNA. Each amino acid has its own tRNA, which has a corresponding anticodon that “matches” the mRNA codon. During translation, the ribosome moves along the mRNA, and as it does so, the polypeptide chain grows. Energy for protein biosynthesis is provided by ATP.
The finished protein molecule is then cleaved from the ribosome and transported to Right place cells. To achieve their active state, some proteins require additional post-translational modification.